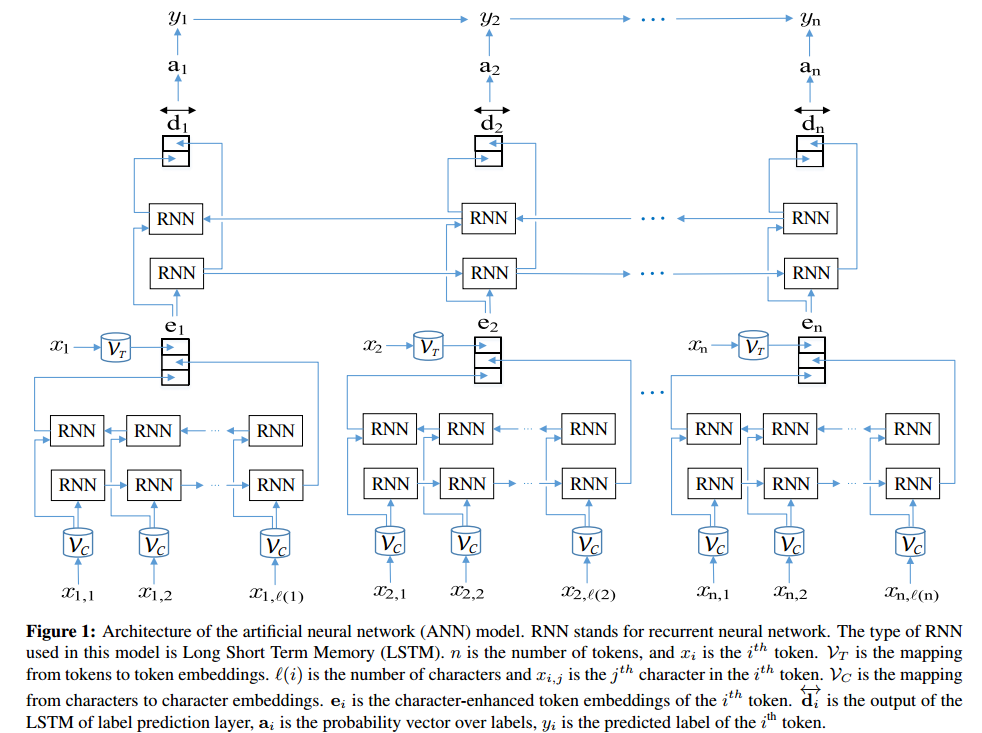
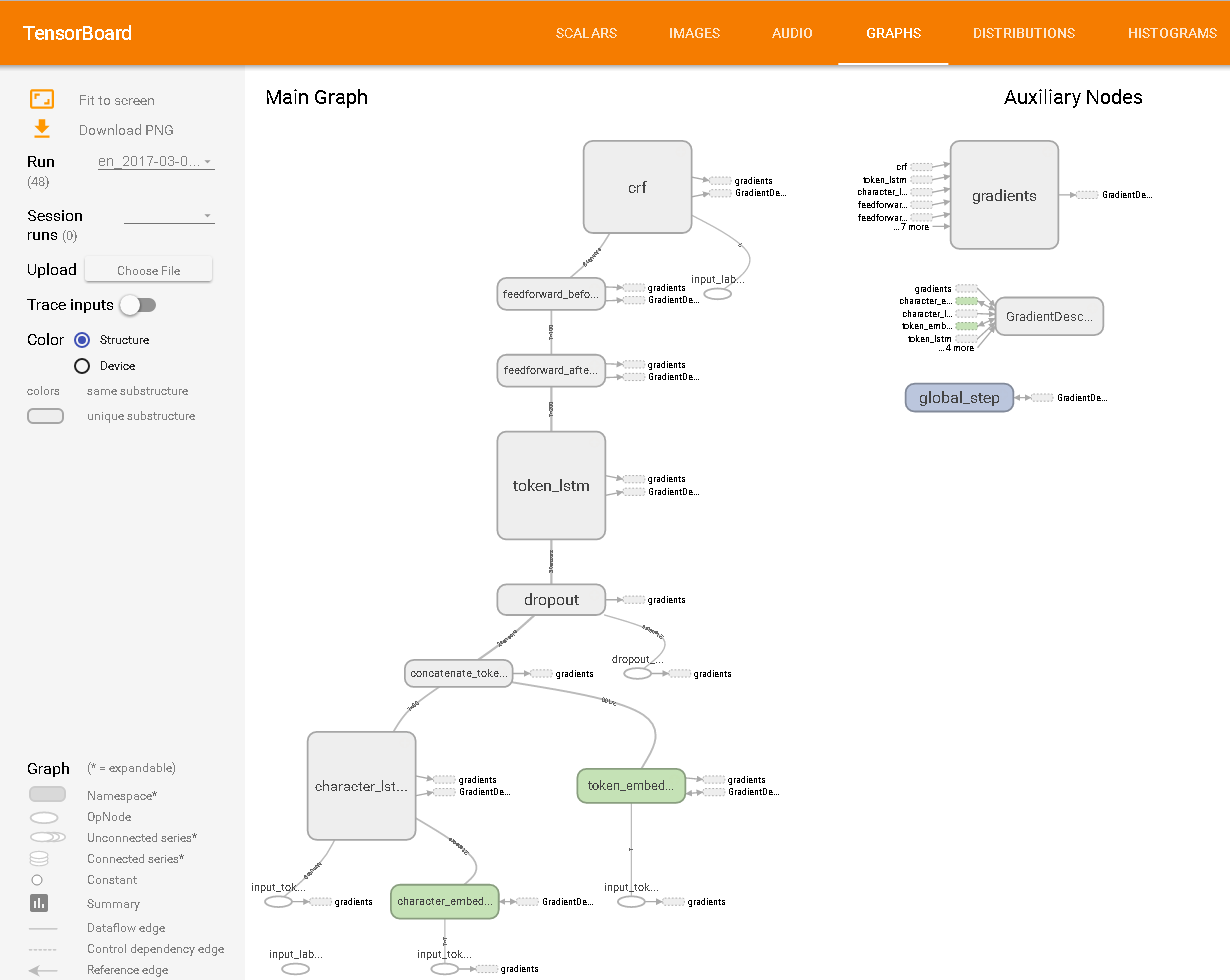
I would like to use named entity recognition (NER) to find adequate tags for texts in a database.
I know there is a Wikipedia article about this and lots of other pages describing NER, I would preferably hear something about this topic from you:
- What experiences did you make with the various algorithms?
- Which algorithm would you recommend?
- Which algorithm is the easiest to implement (PHP/Python)?
- How to the algorithms work? Is manual training necessary?
Example:
"Last year, I was in London where I saw Barack Obama." => Tags: London, Barack Obama
I hope you can help me. Thank you very much in advance!