I have a file that contains "straight" (normal, ASCII) quotes, and I'm trying to convert them to real quotation mark glyphs (“curly” quotes, U+2018 to U+201D). Since the transformation from two different quote characters into a single one has been lossy in the first place, obviously there is no way to automatically perform this conversion; nevertheless I suspect a few heuristics will cover most cases. So the plan is a script (in Emacs) that does something like the following: for each straight quote character,
- guess which curly quote character to use, if possible
- ask the user (me) to confirm, or make a choice
This question is about the first step: what would be a good algorithm (a set of heuristics, more like) to use, for normal English text (a novel, for example)? Here are some preliminary ideas, which I believe work for double-quotes (counterexamples are welcome!):
- If a double-quote is at the beginning of a line, guess that it is an opening quote.
- If a double-quote is at the end of a line, guess a closing quote.
- If a double-quote is preceded by a space, guess an opening quote.
- If a double-quote is followed by a space, guess a closing quote.
- If a double-quote doesn't fit into one of the above categories, guess that it is the “opposite” of the most recently used kind of double-quote.
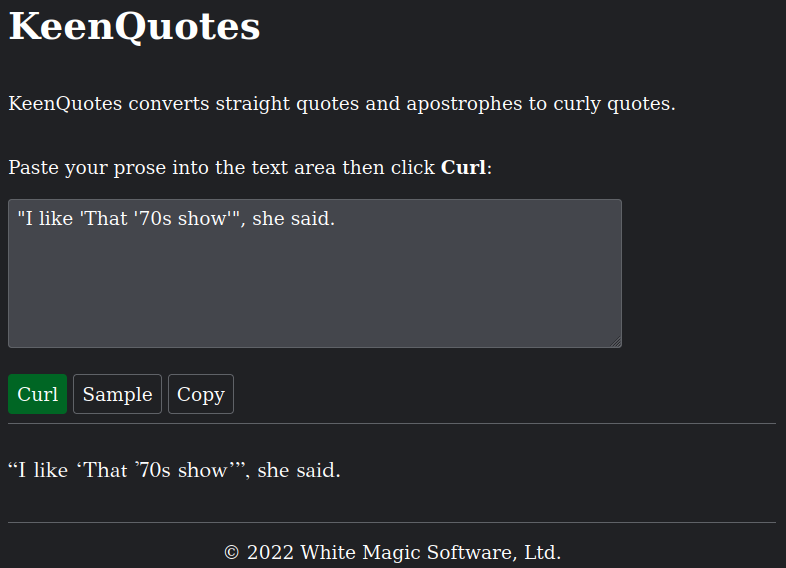
Single quotes are trickier, because a ' might be either an opening quote, closing quote, or apostrophe, and we want to leave apostrophes alone (mustn't write “mustn’t”). Some of the same rules as above apply, but 'tis possible apostrophes are at the beginning of words (or lines), although it's less common than 'twas in the past. I can't offhand think of rules that would properly handle fragments like ["I like 'That '70s show'", she said]. It might require looking at more than just neighbouring characters, and compute distances between quotes, for example…
Any more ideas? It is okay if not all possible cases are covered; the goal is to be as intelligent as possible but no further. :-)
Edit: Some more things that might be worth thinking about (or might be irrelevant, not sure):
- quotes might not always be in matching pairs: For single quotes it's obvious why as above. But even for double quotes, when there is a quotation that extends for more than one paragraph, usual typographic convention (don't ask me why) is to start each paragraph with a quotation mark, even though it has not been closed in the previous one. So simply keeping a state machine that alternates between two states will not work!
- Nested quotation (alluded to in the "I like 'That '70s show'" example above): this might make either kind of quote not be preceded or followed by a space.
- British/American punctuation style: are commas inside the quotes or outside?
- Many word processors (e.g Microsoft Word) already do some sort of conversion like this. Although they are not perfect and can often be annoying, it might be instructive to learn how they work...