I got two images showing exaktly the same content: 2D-gaussian-shaped spots. I call these two 16-bit png-files "left.png" and "right.png". But as they are obtained thru an slightly different optical setup, the corresponding spots (physically the same) appear at slightly different positions. Meaning the right is slightly stretched, distorted, or so, in a non-linear way. Therefore I would like to get the transformation from left to right.
So for every pixel on the left side with its x- and y-coordinate I want a function giving me the components of the displacement-vector that points to the corresponding pixel on the right side.
In a former approach I tried to get the positions of the corresponding spots to obtain the relative distances deltaX and deltaY. These distances then I fitted to the taylor-expansion up to second order of T(x,y) giving me the x- and y-component of the displacement vector for every pixel (x,y) on the left, pointing to corresponding pixel (x',y') on the right.
To get a more general result I would like to use normalized cross-correlation. For this I multiply every pixelvalue from left with a corresponding pixelvalue from right and sum over these products. The transformation I am looking for should connect the pixels that will maximize the sum. So when the sum is maximzied, I know that I multiplied the corresponding pixels.
I really tried a lot with this, but didn't manage. My question is if somebody of you has an idea or has ever done something similar.
import numpy as np
import Image
left = np.array(Image.open('left.png'))
right = np.array(Image.open('right.png'))
# for normalization (http://en.wikipedia.org/wiki/Cross-correlation#Normalized_cross-correlation)
left = (left - left.mean()) / left.std()
right = (right - right.mean()) / right.std()
Please let me know if I can make this question more clear. I still have to check out how to post questions using latex.
Thank you very much for input.


[left.png] https://i.sstatic.net/oSTER.png [right.png] https://i.sstatic.net/Njahj.png
{kind=link}
{kind=link}
I'm afraid, in most cases 16-bit images appear just black (at least on systems I use) :( but of course there is data in there.
UPDATE 1
I try to clearify my question. I am looking for a vector-field with displacement-vectors that point from every pixel in left.png to the corresponding pixel in right.png. My problem is, that I am not sure about the constraints I have.
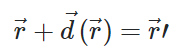
where vector r (components x and y) points to a pixel in left.png and vector r-prime (components x-prime and y-prime) points to the corresponding pixel in right.png. for every r there is a displacement-vector.
What I did earlier was, that I found manually components of vector-field d and fitted them to a polynom second degree:
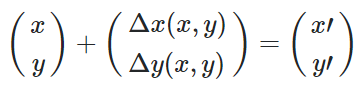
So I fitted:
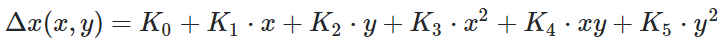 and
and
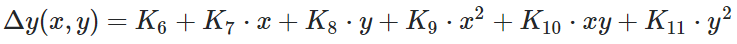
Does this make sense to you? Is it possible to get all the delta-x(x,y) and delta-y(x,y) with cross-correlation? The cross-correlation should be maximized if the corresponding pixels are linked together thru the displacement-vectors, right?
UPDATE 2
So the algorithm I was thinking of is as follows:
- Deform right.png
- Get the value of cross-correlation
- Deform right.png further
- Get the value of cross-correlation and compare to value before
- If it's greater, good deformation, if not, redo deformation and do something else
- After maximzied the cross-correlation value, know what deformation there is :)
About deformation: could one do first a shift along x- and y-direction to maximize cross-correlation, then in a second step stretch or compress x- and y-dependant and in a third step deform quadratic x- and y-dependent and repeat this procedure iterativ?? I really have a problem to do this with integer-coordinates. Do you think I would have to interpolate the picture to obtain a continuous distribution?? I have to think about this again :( Thanks to everybody for taking part :)