I am working on sentiment analysis on steam reviews dataset using BERT model where I have 2 labels: positive and negative. I have fine-tuned the model with 2 Linear layers and the code for that is as below.
bert = BertForSequenceClassification.from_pretrained("bert-base-uncased",
num_labels = len(label_dict),
output_attentions = False,
output_hidden_states = False)
class bertModel(nn.Module):
def __init__(self, bert):
super(bertModel, self).__init__()
self.bert = bert
self.dropout1 = nn.Dropout(0.1)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(768, 512)
self.fc2 = nn.Linear(512, 2)
self.softmax = nn.LogSoftmax(dim = 1)
def forward(self, **inputs):
_, x = self.bert(**inputs)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout1(x)
x = self.fc2(x)
x = self.softmax(x)
return x
This is my train function:
def model_train(model, device, criterion, scheduler, optimizer, n_epochs):
train_loss = []
model.train()
for epoch in range(1, epochs+1):
total_train_loss, training_loss = 0,0
for idx, batch in enumerate(dataloader_train):
model.zero_grad()
data = tuple(b.to(device) for b in batch)
inputs = {'input_ids': data[0],'attention_mask': data[1],'labels':data[2]}
outputs = model(**inputs)
loss = criterion(outputs, labels)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
#update the weights
optimizer.step()
scheduler.step()
training_loss += loss.item()
total_train_loss += training_loss
if idx % 25 == 0:
print('Epoch: {}, Batch: {}, Training Loss: {}'.format(epoch, idx, training_loss/10))
training_loss = 0
#avg training loss
avg_train_loss = total_train_loss/len(dataloader_train)
#validation data loss
avg_pred_loss = model_evaluate(dataloader_val)
#print for every end of epoch
print('End of Epoch {}, Avg. Training Loss: {}, Avg. validation Loss: {} \n'.format(epoch, avg_train_loss, avg_pred_loss))
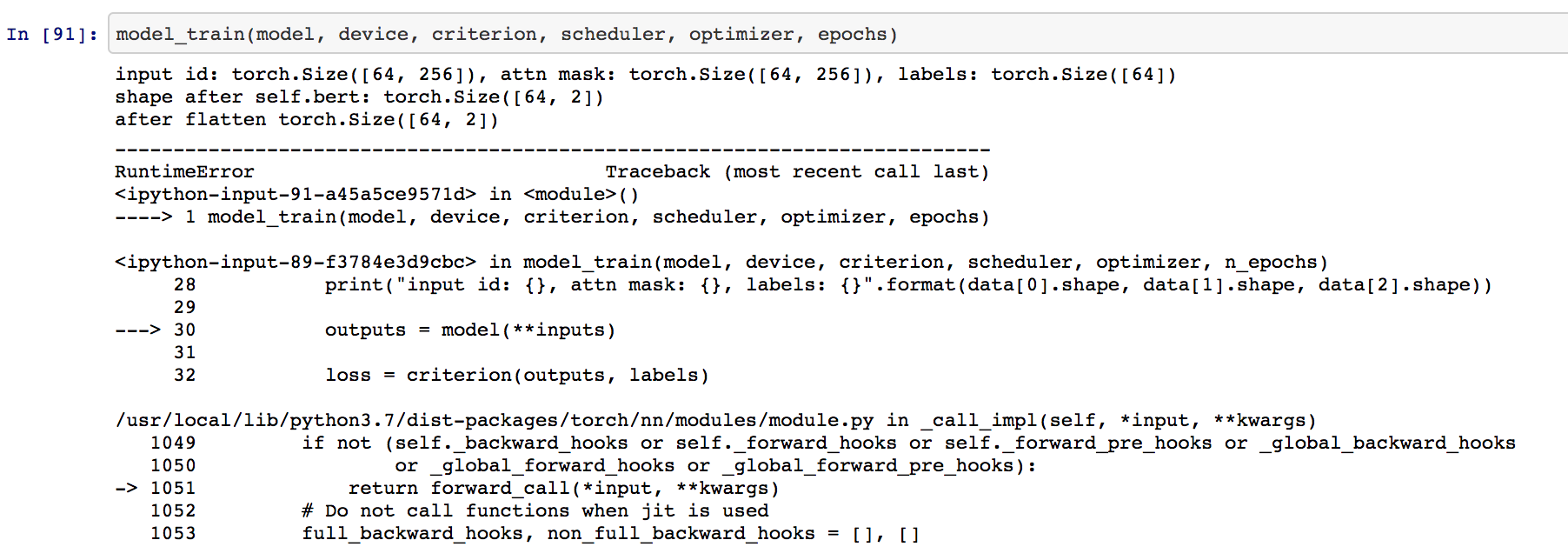
I am running this code on Google Colab. When I run the train function, I get the following the error, I have tried with batch sizes 32, 256, 512.
RuntimeError: CUDA error: CUBLAS_STATUS_INVALID_VALUE when calling `cublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)`
Can anyone please help me on this? Thank you.
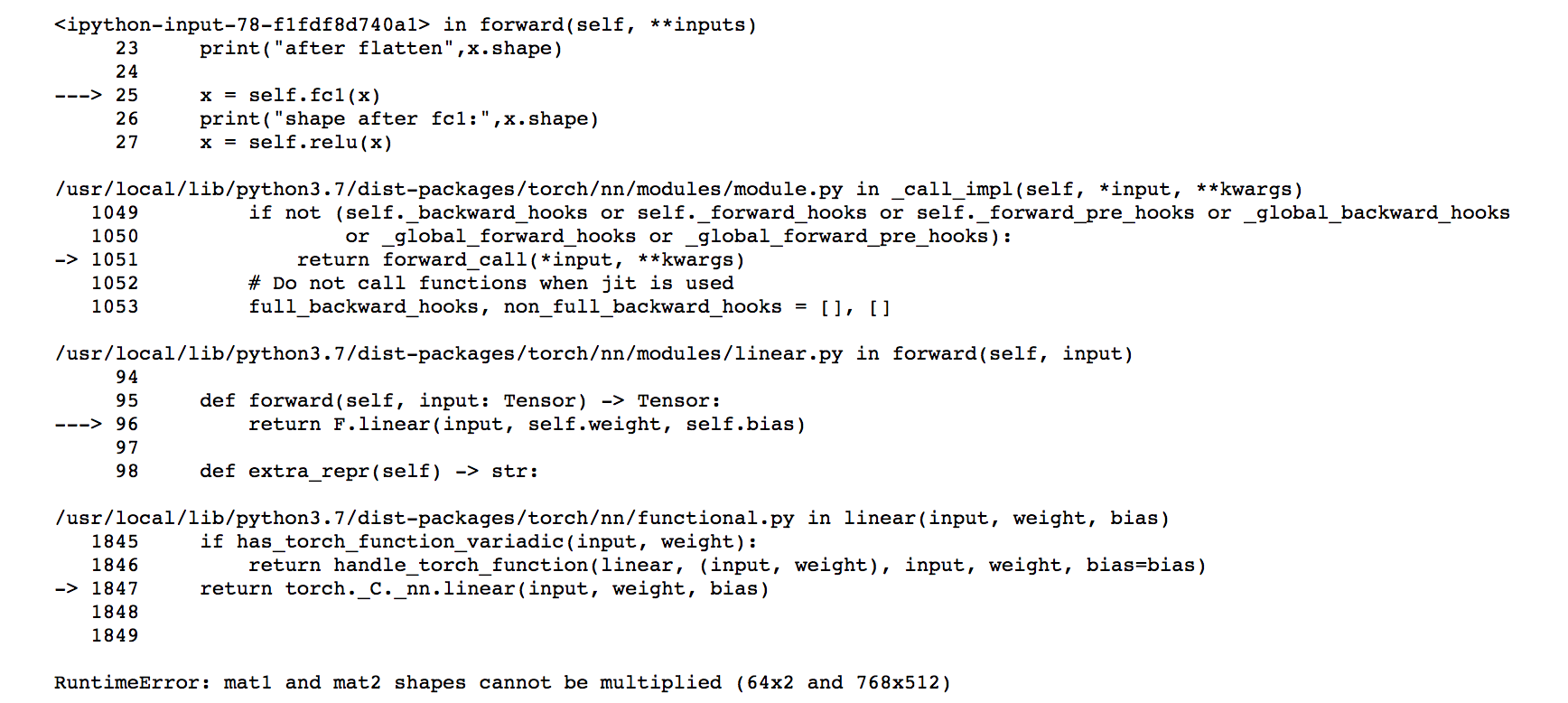
Update on the code: I tried running the code on the CPU and the error is in the matrix shapes mismatch. The input shape, shape after the self.bert is printed in the image. Since the first linear layer (fc1) is not getting executed, the shape after that is not printed.