Let us have the following data
IF OBJECT_ID('dbo.LogTable', 'U') IS NOT NULL DROP TABLE dbo.LogTable
SELECT TOP 100000 DATEADD(day, ( ABS(CHECKSUM(NEWID())) % 65530 ), 0) datesent
INTO [LogTable]
FROM sys.sysobjects
CROSS JOIN sys.all_columns
I want to count the number of rows, the number of last year rows and the number of last ten years rows. This can be achieved using conditional aggregation query or using subqueries as follows
-- conditional aggregation query
SELECT
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
-- subqueries
SELECT
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
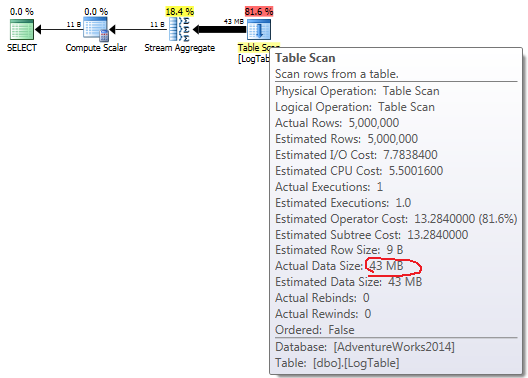
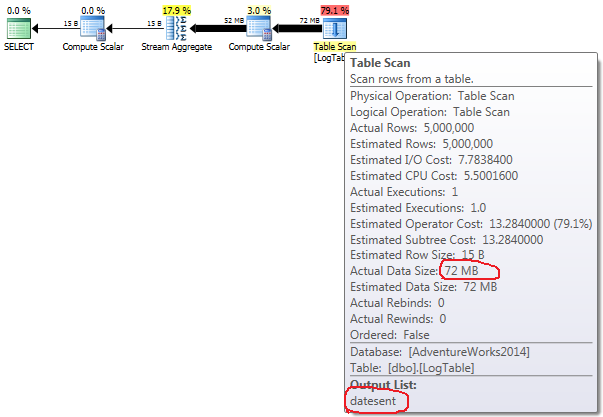
If you perform the queries and look on query plans then you see something like
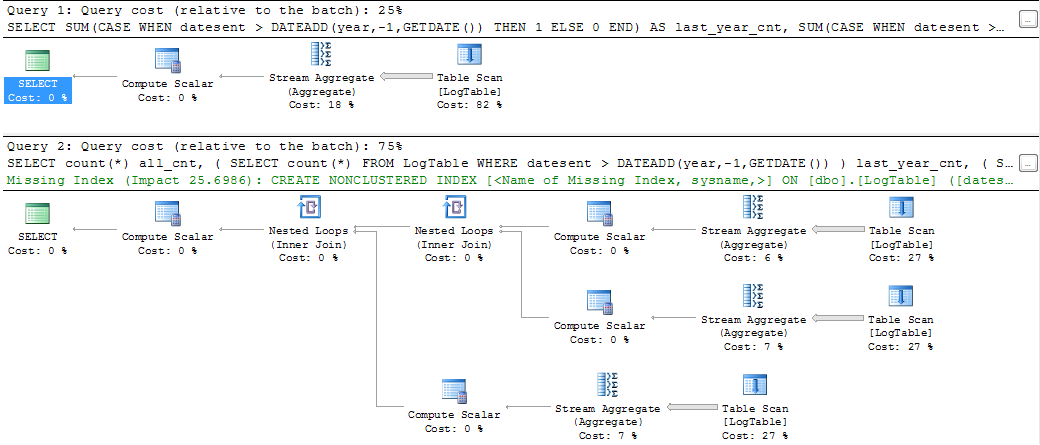
Clearly, the first solution has much nicer query plan, cost estimation and even the SQL command looks more concise and fancy. However, if you measure the CPU time of the query using SET STATISTICS TIME ON I get the following results (I have measured several times with approximately the same results)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 41 ms.
(1 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 26 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
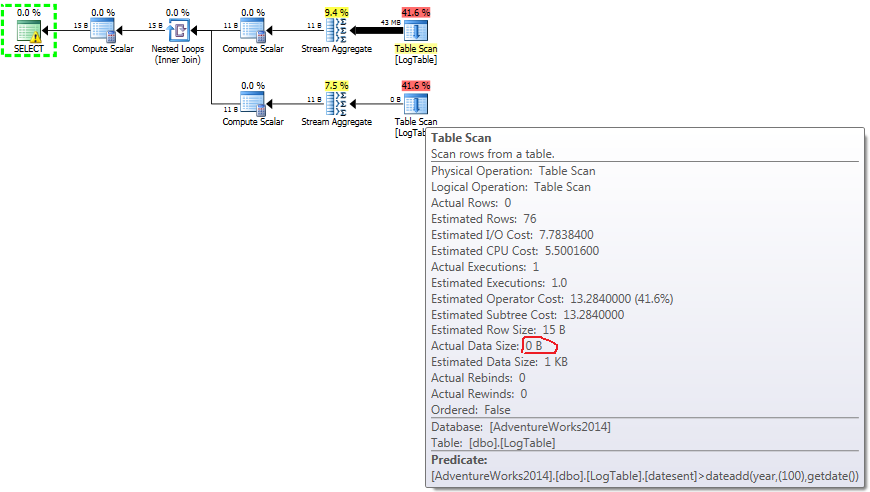
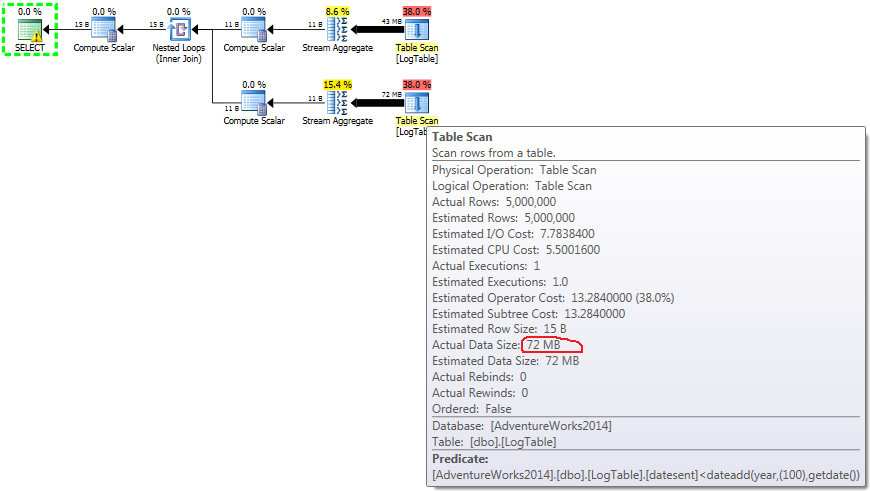
Therefore, the second solution has slightly better (or the same) performance than the solution using conditional aggregation. The difference becomes more evident if we create the index on datesent attribute.
CREATE INDEX ix_logtable_datesent ON dbo.LogTable(DateSent)
Then the second solution starts to use Index Seek instead of Table Scan and its query CPU time performance drops to 16ms on my computer.
My questions are two: (1) why the conditional aggregation solution does not outperform the subquery solution at least in the case without index, (2) is it possible to create 'index' for the conditional aggregation solution (or rewrite the conditional aggregation query) in order to avoid scan, or is conditional aggregation generally unsuitable if we are concerned about performance?
Sidenote: I can say, that this scenario is quite optimistic for conditional aggregation since we select the number of all rows which always leads to a solution using scan. If the number of all rows is not needed, then indexed solution with subqueries has no scan, whereas, the solution with conditional aggregation has to perform the scan anyway.
EDIT
Vladimir Baranov basically answered the first question (thank you very much). However, the second question remains. I can see on StackOverflow answers using conditional aggregation solutions quite offten and they attract a lot of attention being accepted as the most elegant and clear solution (and sometimes being proposed as the most efficient solution). Therefore, I will slightly generalize the question:
Could you give me an example, where conditional aggregation notably outperforms the subquery solution?
For simplicity let us assume that physical accesses are not present (data are in Buffer cache) since the today database servers remain most of their data in the memory anyway.

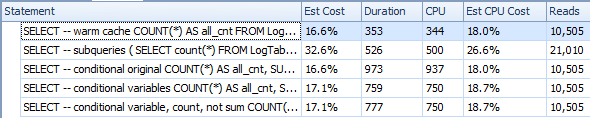
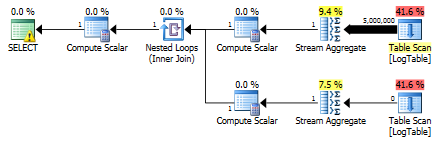

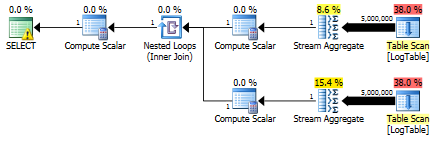
WHEREcolumn, the separate subqueries outperform the conditional aggregations. – Hardworking