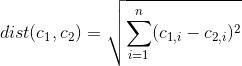You can use
PCA can be done by eigenvalue decomposition of a data covariance (or correlation) matrix or singular value decomposition of a data matrix, usually after mean centering (and normalizing or using Z-scores) the data matrix for each attribute. The results of a PCA are usually discussed in terms of component scores, sometimes called factor scores (the transformed variable values corresponding to a particular data point), and loadings (the weight by which each standardized original variable should be multiplied to get the component score).
Some essential points:
- the eigenvalues reflect the portion of variance explained by the corresponding component. Say, we have 4 features with eigenvalues
1, 4, 1, 2. These are the variances explained by the corresp. vectors. The second value belongs to the first principle component as it explains 50 % off the overall variance and the last value belongs to the second principle component explaining 25 % of the overall variance.
- the eigenvectors are the component's linear combinations. The give the weights for the features so that you can know, which feature as high/low impact.
- use PCA based on correlation matrix instead of empiric covariance matrix, if the eigenvalues strongly differ (magnitudes).
Sample approach
- do PCA on entire dataset (that's what the function below does)
- take matrix with observations and features
- center it to its average (average of feature values among all observations)
- compute empiric covariance matrix (e.g.
np.cov) or correlation (see above)
- perform decomposition
- sort eigenvalues and eigenvectors by eigenvalues to get components with highest impact
- use components on original data
- examine the clusters in the transformed dataset. By checking their location on each component you can derive the features with high and low impact on distribution/variance
Sample function
You need to import numpy as np and scipy as sp. It uses sp.linalg.eigh for decomposition. You might want to check also the scikit decomposition module.
PCA is performed on a data matrix with observations (objects) in rows and features in columns.
def dim_red_pca(X, d=0, corr=False):
r"""
Performs principal component analysis.
Parameters
----------
X : array, (n, d)
Original observations (n observations, d features)
d : int
Number of principal components (default is ``0`` => all components).
corr : bool
If true, the PCA is performed based on the correlation matrix.
Notes
-----
Always all eigenvalues and eigenvectors are returned,
independently of the desired number of components ``d``.
Returns
-------
Xred : array, (n, m or d)
Reduced data matrix
e_values : array, (m)
The eigenvalues, sorted in descending manner.
e_vectors : array, (n, m)
The eigenvectors, sorted corresponding to eigenvalues.
"""
# Center to average
X_ = X-X.mean(0)
# Compute correlation / covarianz matrix
if corr:
CO = np.corrcoef(X_.T)
else:
CO = np.cov(X_.T)
# Compute eigenvalues and eigenvectors
e_values, e_vectors = sp.linalg.eigh(CO)
# Sort the eigenvalues and the eigenvectors descending
idx = np.argsort(e_values)[::-1]
e_vectors = e_vectors[:, idx]
e_values = e_values[idx]
# Get the number of desired dimensions
d_e_vecs = e_vectors
if d > 0:
d_e_vecs = e_vectors[:, :d]
else:
d = None
# Map principal components to original data
LIN = np.dot(d_e_vecs, np.dot(d_e_vecs.T, X_.T)).T
return LIN[:, :d], e_values, e_vectors
Sample usage
Here's a sample script, which makes use of the given function and uses scipy.cluster.vq.kmeans2 for clustering. Note that the results vary with each run. This is due to the starting clusters a initialized randomly.
import numpy as np
import scipy as sp
from scipy.cluster.vq import kmeans2
import matplotlib.pyplot as plt
SN = np.array([ [1.325, 1.000, 1.825, 1.750],
[2.000, 1.250, 2.675, 1.750],
[3.000, 3.250, 3.000, 2.750],
[1.075, 2.000, 1.675, 1.000],
[3.425, 2.000, 3.250, 2.750],
[1.900, 2.000, 2.400, 2.750],
[3.325, 2.500, 3.000, 2.000],
[3.000, 2.750, 3.075, 2.250],
[2.075, 1.250, 2.000, 2.250],
[2.500, 3.250, 3.075, 2.250],
[1.675, 2.500, 2.675, 1.250],
[2.075, 1.750, 1.900, 1.500],
[1.750, 2.000, 1.150, 1.250],
[2.500, 2.250, 2.425, 2.500],
[1.675, 2.750, 2.000, 1.250],
[3.675, 3.000, 3.325, 2.500],
[1.250, 1.500, 1.150, 1.000]], dtype=float)
clust,labels_ = kmeans2(SN,3) # cluster with 3 random initial clusters
# PCA on orig. dataset
# Xred will have only 2 columns, the first two princ. comps.
# evals has shape (4,) and evecs (4,4). We need all eigenvalues
# to determine the portion of variance
Xred, evals, evecs = dim_red_pca(SN,2)
xlab = '1. PC - ExpVar = {:.2f} %'.format(evals[0]/sum(evals)*100) # determine variance portion
ylab = '2. PC - ExpVar = {:.2f} %'.format(evals[1]/sum(evals)*100)
# plot the clusters, each set separately
plt.figure()
ax = plt.gca()
scatterHs = []
clr = ['r', 'b', 'k']
for cluster in set(labels_):
scatterHs.append(ax.scatter(Xred[labels_ == cluster, 0], Xred[labels_ == cluster, 1],
color=clr[cluster], label='Cluster {}'.format(cluster)))
plt.legend(handles=scatterHs,loc=4)
plt.setp(ax, title='First and Second Principle Components', xlabel=xlab, ylabel=ylab)
# plot also the eigenvectors for deriving the influence of each feature
fig, ax = plt.subplots(2,1)
ax[0].bar([1, 2, 3, 4],evecs[0])
plt.setp(ax[0], title="First and Second Component's Eigenvectors ", ylabel='Weight')
ax[1].bar([1, 2, 3, 4],evecs[1])
plt.setp(ax[1], xlabel='Features', ylabel='Weight')
Output
The eigenvectors show the weighting of each feature for the component
![enter image description here]()
![enter image description here]()
Short Interpretation
Let's just have a look at cluster zero, the red one. We'll be mostly interested in the first component as it explains about 3/4 of the distribution. The red cluster is in the upper area of the first component. All observations yield rather high values. What does it mean? Now looking at the linear combination of the first component we see on first sight, that the second feature is rather unimportant (for this component). The first and fourth feature are the highest weighted and the third one has a negative score. This means, that - as all red vertices have a rather high score on the first PC - these vertices will have high values in the first and last feature, while at the same time they have low scores concerning the third feature.
Concerning the second feature we can have a look at the second PC. However, note that the overall impact is far smaller as this component explains only roughly 16 % of the variance compared to the ~74 % of the first PC.