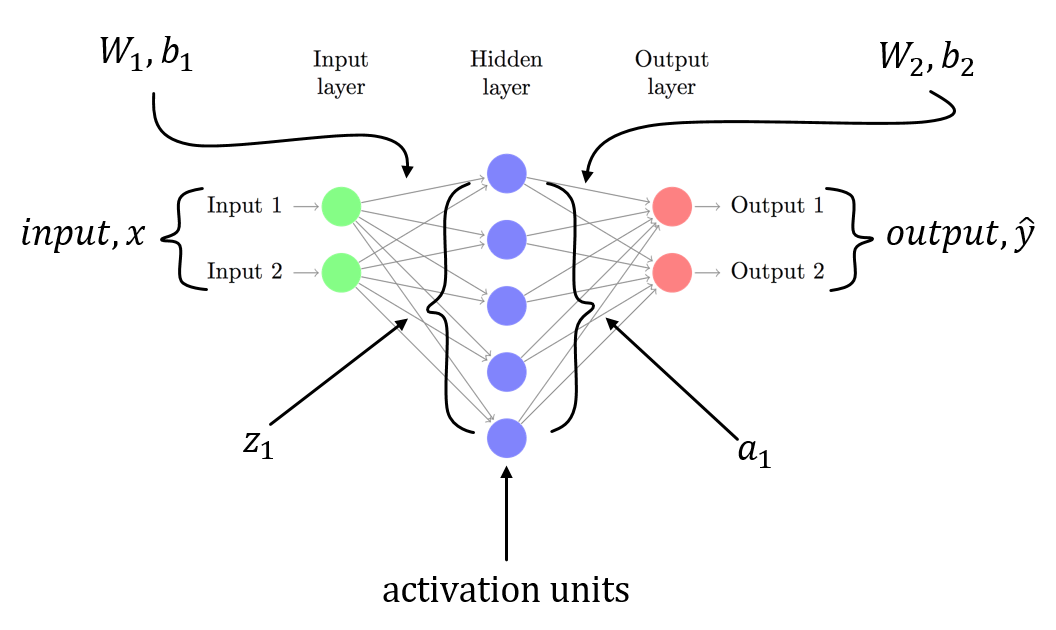
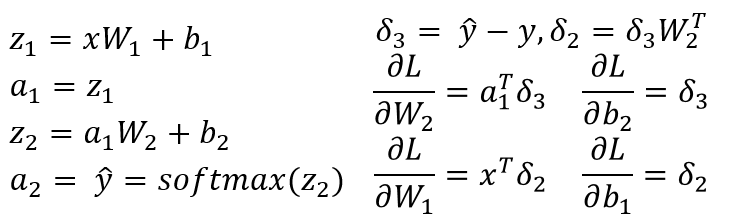I am trying to understand backpropagation in a simple 3 layered neural network with MNIST.
There is the input layer with weights and a bias. The labels are MNIST so it's a 10 class vector.
The second layer is a linear tranform. The third layer is the softmax activation to get the output as probabilities.
Backpropagation calculates the derivative at each step and call this the gradient.
Previous layers appends the global or previous gradient to the local gradient. I am having trouble calculating the local gradient of the softmax
Several resources online go through the explanation of the softmax and its derivatives and even give code samples of the softmax itself
def softmax(x):
"""Compute the softmax of vector x."""
exps = np.exp(x)
return exps / np.sum(exps)
The derivative is explained with respect to when i = j and when i != j. This is a simple code snippet I've come up with and was hoping to verify my understanding:
def softmax(self, x):
"""Compute the softmax of vector x."""
exps = np.exp(x)
return exps / np.sum(exps)
def forward(self):
# self.input is a vector of length 10
# and is the output of
# (w * x) + b
self.value = self.softmax(self.input)
def backward(self):
for i in range(len(self.value)):
for j in range(len(self.input)):
if i == j:
self.gradient[i] = self.value[i] * (1-self.input[i))
else:
self.gradient[i] = -self.value[i]*self.input[j]
Then self.gradient is the local gradient which is a vector. Is this correct? Is there a better way to write this?