I have my website configured to serve static content using gzip compression, like so:
<link rel='stylesheet' href='http://cdn-domain.com/css/style.css.gzip?ver=0.9' type='text/css' media='all' />
I don't see any website doing anything similar. So, the question is, what's wrong with this? Am I to expect shortcomings?
Precisely, as I understand it, most websites are configured to serve normal static files (.css, .js, etc) and gzipped content (.css.gz, .js.gz, etc) only if the request comes with a Accept-Encoding: gzip header. Why should they be doing this when all browsers support gzip just the same?
PS: I am not seeing any performance issues at all because all the static content is gzipped prior to uploading it to the CDN which then simply serves the gzipped files. Therefore, there's no stress/strain on my server.
Just in case it's helpful, here's the HTTP Response Header information for the gzipped CSS file:
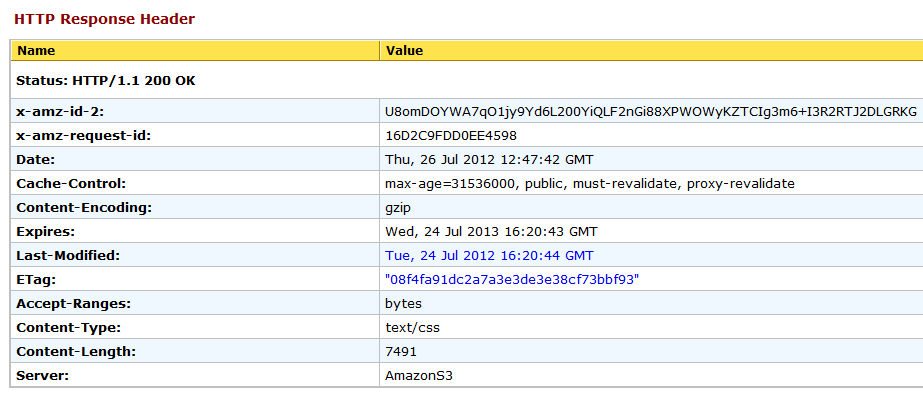
And this for gzipped favicon.ico file:
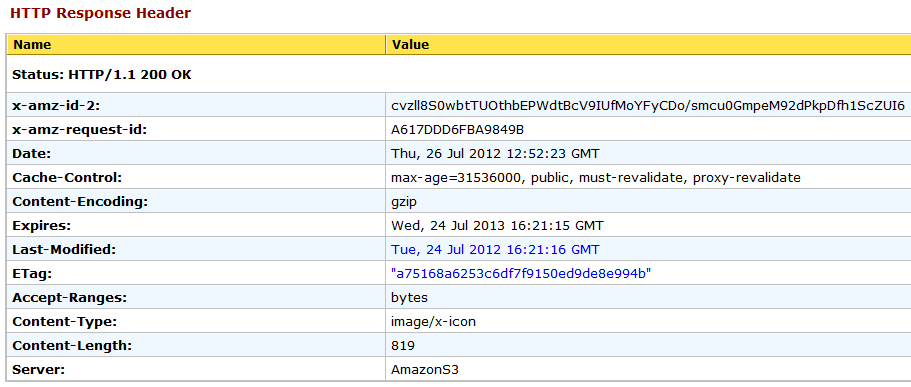
.gzipsuffix (which should technically be only.gz). – ProcurationContent-Encoding: gzip, it's a very highly used mechanism these days. As I already mentioned, preprocessing the files for gzip compression isn't a new idea (think svgz especially), but most hosts will be set up to handle it transparently without relying on a file name suffix as you've used. Are you actually having an issue? If so, could you highlight that? Currently I'm totally missing the question in your question. – Procuration