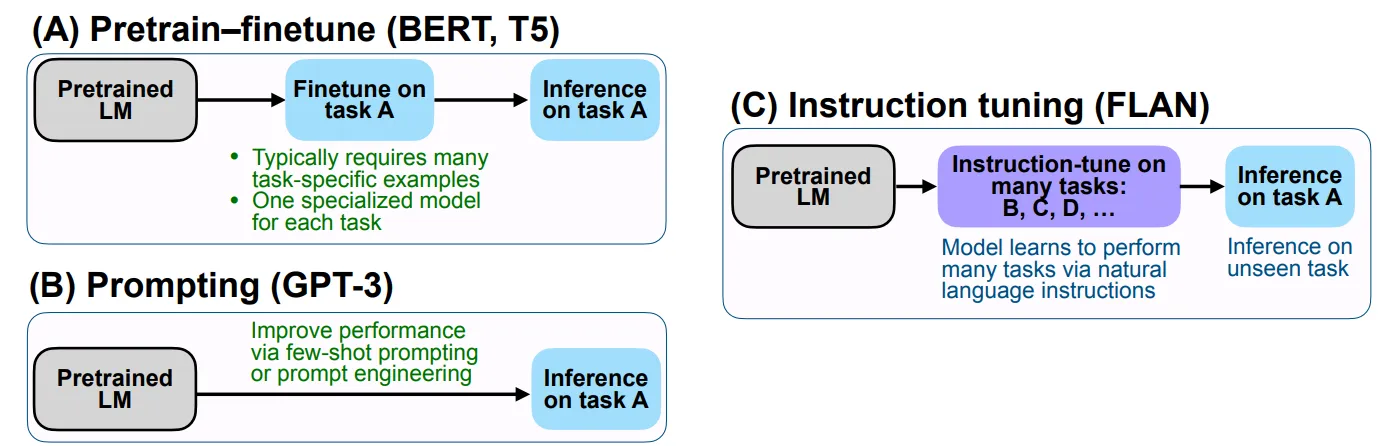
As you said, fine-tuning and instruction tuning are not mutually exclusive, but instruction tuning is a form of (supervised) fine-tuning, so there is no distinguishing feature of fine-tuning that differentiates it from instruction tuning, but only the other way around. So the answer to your first question is "No" (I read it as "Is every dataset an instruction dataset?", not as "Do instruction datasets even exist?").
What is special about instruction tuning is that the model is fine-tuned for an instruction-following task, which involves instructing the instruction receiver to perform another task, i.e. you have a second "level" of tasks (e.g. "Split the following number into digits") that is defined only in the instructions, which are part of the model's input sequence.
In classical types of supervised fine-tuning, you have no instructions, but directly tune the model to perform a single downstream task, e.g. to split an input number into digits, without being explicitly told to do so in the model input. (However, there are also hybrid approaches that involve both fine-tuning and explicit instructions.)
So although the word "task" is often used to refer to either, it is essential to conceptually distinguish between:
- the task the model is fine-tuned to (if at all),
- the task the end-user wants the model to perform, and
- the way inputs for either of these tasks are presented to the model
- (and also the corresponding datasets and statistical distributions)
In summary, one could say that in instruction following, the actual task is determined dynamically, at inference time, while in the classical fine-tuning approach without instructions or similar devices, the actual task is determined statically, at training time.
Your confusion might be connected to the fact that prompting, which is another widespread adaptation technique, can involve an abstract description of the task (e.g. in zero-shot prompting), which can be formulated as an instruction.
But again, this is not necessary: Few-shot prompting does not necessarily involve an abstract description of the task, but the prompt may consist only of input-output examples of the task, plus the input for which the model should predict the output.
To answer your second question: You can find many datasets/benchmarks on the Hugging Face Hub. If you randomly click at a few of them, you will see in the preview that most of them don't contain any instructions.
EDIT: I forgot to mention one important aspect of instruction tuning: Depending on the application or research question, it often is a goal of instruction tuning to generalize instruction following across tasks. That is, the model should learn to follow instructions based on the implicit knowledge it accumulated during pre-training, and not only based on the instructions it saw during instruction tuning. To measure this cross-task generalization capability, instruction datasets are often divided into multiple tasks. Some of these tasks (not only some split of each task) are held out during instruction tuning and they are used during evaluation only.