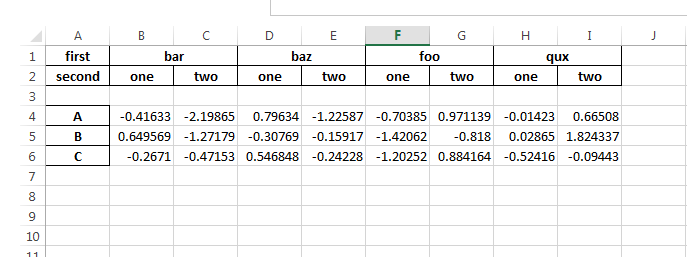
I am trying to save a Pandas dataframe to an excel file using the to_excel function with XlsxWriter.
When I print the dataframe to the terminal then it reads as it should, but when I save it to excel and open the file, there is an extra blank line below the headers which shouldn't be there. This only happens when using MultiIndex for the headers, but I need the layered headers that it offers and I can't find a solution.
Below is code from an online MultiIndex example which produces the same result as the project I'm working on. Any solutions would be greatly appreciated.
import numpy as np
import pandas as pd
import xlsxwriter
tuples = [('bar', 'one'), ('bar', 'two'), ('baz', 'one'), ('baz', 'two'), ('foo', 'one'), ('foo', 'two'), ('qux', 'one'), ('qux', 'two')]
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
iterables = [['bar', 'baz', 'foo', 'qux'], ['one', 'two']]
pd.MultiIndex.from_product(iterables, names=['first', 'second'])
df = pd.DataFrame(np.random.randn(3, 8), index=['A', 'B', 'C'], columns=index)
print(df)
writer = pd.ExcelWriter('test.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='test1')
The excel output created: