Why are there no ++ and -- operators in Python?
Why are there no ++ and -- operators in Python?
Related post - Behaviour of increment and decrement operators in Python –
Himelman
because there redundent –
Subside
theres like 4 different ++ operators that all do the same thing. Oh and there removing the "++" from "C++" now that seems like a degeneration –
Subside
It's not because it doesn't make sense; it makes perfect sense to define "x++" as "x += 1, evaluating to the previous binding of x".
If you want to know the original reason, you'll have to either wade through old Python mailing lists or ask somebody who was there (eg. Guido), but it's easy enough to justify after the fact:
Simple increment and decrement aren't needed as much as in other languages. You don't write things like for(int i = 0; i < 10; ++i) in Python very often; instead you do things like for i in range(0, 10).
Since it's not needed nearly as often, there's much less reason to give it its own special syntax; when you do need to increment, += is usually just fine.
It's not a decision of whether it makes sense, or whether it can be done--it does, and it can. It's a question of whether the benefit is worth adding to the core syntax of the language. Remember, this is four operators--postinc, postdec, preinc, predec, and each of these would need to have its own class overloads; they all need to be specified, and tested; it would add opcodes to the language (implying a larger, and therefore slower, VM engine); every class that supports a logical increment would need to implement them (on top of += and -=).
This is all redundant with += and -=, so it would become a net loss.
It is often useful to use something like array[i++], which is not tidily done with +=/-=. –
Prima
@thayes: That's not a common pattern in Python. –
Vasty
@thayes Since that will be inside a loop, you might as well loop over
i directly - if you actually need it and can't just e.g. use array.append() –
Tourneur I see the much bigger concern being readability and predictability. Back in my C days, I saw more than enough bugs stemming from misunderstandings about the distinction between
i++ and ++i... –
Webber I believe in the "C" world it is most effectively used (not most commonly) with pointers. There is a direct mapping to some instructions sets that support pre- or post-increment of address registers - M68K comes to mind as an early supporter of this. Since there are no pointers in Python it is redundant. –
Jacynth
Adding to justifying after-the-fact: on a project I work on, I've encountered (more than anyone should in their life) a fair amount of C++ code suffering from problems with
++ and -- being used in ways that result in undefined or unspecified behavior. They make it possible to write complicated, difficult-to-correctly-parse code. –
Communalize Unbundling something like
return a[i++] is really ugly. You can not replace it directly for i+=1 or i=i+1 and must change a number of lines of code. –
Saveall @LuísdeSousa I'm not sure if you understood the answer. The point is that, unlike in C, you don't need to increment-by-one in Python very often. If you find you're doing it all the time, you might not be using the language fully yet (for, xrange, enumerate, etc.). –
Vasty
Glenn, I am not sure you understood my comment. If you are using
xrange, enumerate, for, etc when you do not know beforehand the number of items to process, you might not be programming correctly. –
Saveall Sorry, that doesn't make sense. You don't need postincrement to write "for item in some_list", or in most of the other cases you typically need it in C. –
Vasty
I would contend that
array[i++] is less painful to lose than array[i]++ -- the former could probably be accomplished elsewhere in your loop, but the latter requires creation of a throwaway temp variable and at least two extra lines of code. –
Canica There's no reason they would require additional opcodes. –
Poleyn
@GlennMaynard inside iterator
return self.vertices[self.current++] - would be nice. –
Tarbes I know this is an old thread, but the situation where you're using a foreach construct to iterate over a collection - and thus aren't being provided indices, and therefore must provide them yourself if you need them - is incredibly common and ++i or i++ is a widely used way to resolve this. This situation is especially common when you need to make every member of an unordered set unique. The work-around for this python provides is enumerate, and I don't see that discussed enough in this thread. –
Lordinwaiting
I like not having ++ & --. They are just syntactic sugar. And some times they are used in such horrendous way that instead of bringing clarity it messes up the code even more. Also, I have seen some question specifically testing candidates this kind of things in MCQs when good developer won't use these much in ways these questions are constructed. Better to leave them. Helps in reading code for beginners without thinking will the increment happen now of after execution of this line. –
Accessible
" It's a question of whether the benefit is worth adding to the core syntax of the language." - To me, study if it's worth mean that there is a cost. Right ? What is the cost of adding ++ and -- to the language ? Use these operator mean that we dont use the language optimally. True, but what about allow ++ operator, to help python newbies to feel comfortable with the language while learning to do so ? To me the cost of adding it is None (except 10 lines in py-interpreter code maybe ?). So why don't add it and let people use it or not as they want ? Thanks a lot ^^ –
Spurry
This original answer I wrote is a myth from the folklore of computing: debunked by Dennis Ritchie as "historically impossible" as noted in the letters to the editors of Communications of the ACM July 2012 doi:10.1145/2209249.2209251
The C increment/decrement operators were invented at a time when the C compiler wasn't very smart and the authors wanted to be able to specify the direct intent that a machine language operator should be used which saved a handful of cycles for a compiler which might do a
load memory
load 1
add
store memory
instead of
inc memory
and the PDP-11 even supported "autoincrement" and "autoincrement deferred" instructions corresponding to *++p and *p++, respectively. See section 5.3 of the manual if horribly curious.
As compilers are smart enough to handle the high-level optimization tricks built into the syntax of C, they are just a syntactic convenience now.
Python doesn't have tricks to convey intentions to the assembler because it doesn't use one.
Javascript has ++. I don't think that's a "trick to convey intentions to the assembler." Plus, Python does have bytecode. So I think the reason is something else. –
Barnum
This "providing hints to the compiler" business is indeed a myth. Frankly, it's a dumb addition to any language and it violates the following two precepts: 1. You don't code for the computer to read, you code for another engineer to read. And 2. You don't code for a competent engineer to read, you code for a competent engineer to read while exhausted at 3am and hopped up on caffeine. –
Laundrywoman
@tgm1024 To be fair, when coding on a 10–30 character per second, half-duplex teletype, you code so that you can key it in before next week. –
Bawl
@tgm1024 Unix and C saw the bulk of their initial development on PDP-11s which used incredibly slow teletypes for user communication. While you are dead right that today coding for the machine is mostly silly, back then it was the Human/Machine interface which was the bottleneck. It is hard to imagine working that slowly if you never had to. –
Bawl
Here's an archived copy of Dennis Ritchie's writings cited in that ACM source. –
Quirt
I always assumed it had to do with this line of the zen of python:
There should be one — and preferably only one — obvious way to do it.
x++ and x+=1 do the exact same thing, so there is no reason to have both.
one-- is one in the sentence, but zero immediately afterwards. So this 'koan' also hints that increment/decrement operators are non-obvious. –
Bitterroot An em dash is typically written in ascii as two hyphens, but @VictorK's explanation is more fun. –
Ananna
@GSto: If x++ and x+=1 do the same thing, can you tell me the values of (x++) and (x+=1) ? I think the latter has no value in python -- rather, asking for one would give a syntax error. I would like to keep count of a subset of types within an in-line for loop. x++ would do the trick nicely. –
Lowrance
@EralpB If you delete +=, then you cannot do things like x += 10. += is a more general case of ++ –
Acuity
Also: "Explicit is better than implicit". –
Tearing
@VictorK: Actually, "one--" is one in the sentence, but MINUS one afterwards. Because it happens twice. Even more nonobvious :) Although, the second might be predecrementing "obvious"... –
Stephniestepladder
Definitely not the same, because x+=1 is NOT an expression - it's a statement - and it doesn't evaluate to anything. You can't do stuff like: 'row[col++] = a; row[col++] = b'. Not to mention the pre-inc and post-inc stuff that c++ has. –
Solis
These are not the same... how can I do "if a++ == 3" using += ? –
Oren
@CPBL, please clarify. I understand we're talking about python, but a=x++; and a=(x++); of course yield the exact same result in C. –
Laundrywoman
@tgm1024, wow... (long ago, now..) I meant just what Uri said, above. –
Lowrance
About x+=1 not being an expression? Python, perhaps. But in both C and C++, I believe that all assignments, even the weird compound ones, are expressions. That's what makes a=b=c; work in the first place in those languages (along with grouping from right to left). –
Laundrywoman
x++ and x+=1 are not the same thing. –
Saveall @Rory If you delete += then you can do things like x += 10 still. You can do x = x + 10. –
Takashi
By that logic,
+= shouldn't exist either, because you can just use x = x + n. But += is more convenient. Similarly, ++ is a more convenient way of adding 1. –
Congou Both may be more convenient but it's a matter of benefit vs cost. For example, Go has increment/decrement statements but not expressions. Their justification is "Without pointer arithmetic, the convenience value of pre- and postfix increment operators drops. By removing them from the expression hierarchy altogether, expression syntax is simplified and the messy issues around order of evaluation of
++ and -- are eliminated as well". This makes the syntax less convenient but more consistent and readable. It's easy to extrapolate this idea to Python. –
Refectory "exact" means they are mutually swappable, and in this case they are not since they don't have the same return values. –
Nedry
Of course, we could say "Guido just decided that way", but I think the question is really about the reasons for that decision. I think there are several reasons:
- It mixes together statements and expressions, which is not good practice. See http://norvig.com/python-iaq.html
- It generally encourages people to write less readable code
- Extra complexity in the language implementation, which is unnecessary in Python, as already mentioned
Glad someone finally mentioned the statement vs expression aspect. In C assignment is an expression and so it the ++ operator. In Python assignment is a statement, so if it had a ++, it would likely need to be an assignment statement, too (and even less useful or needed). –
Companionship
Agreed - if they were statements, then at a minimum it would become absolutely meaningless to talk about the difference between post- and pre- operators. –
Cultigen
Because, in Python, integers are immutable (int's += actually returns a different object).
Also, with ++/-- you need to worry about pre- versus post- increment/decrement, and it takes only one more keystroke to write x+=1. In other words, it avoids potential confusion at the expense of very little gain.
ints are immutable in C as well. If you don't think so, try to get your C compiler to generate code for
42++... Something like this (modifying a literal constant) was actually possible in some old Fortran compilers (or so I've read): All future uses of that literal in that program run would then really have a different value. Happy debugging! –
Bootblack Right. 42 is a literal constant. Constants are (or at least should be) immutable. That doesn't mean C
ints in general are immutable. An int in C simply designates a place in memory. And the bits in that place is very much mutable. You can, for instance, create a reference of an int and change the referent of that reference. This change is visible in all references (including the original int variable) to that place. The same doesn't hold for a Python integer object. –
Barnum "it takes only one more keystroke to write x+=1" except that a[x+=1] doesn't work, which is quite a common pattern in other languages. If there's a more fundamental reason why that doesn't work, then it seems like bad language design being spun as a way to prevent people from making mistakes - is Python reeally known/used as a "safe" language in that way? The explanation you've given doesn't seem consistent with the rest of Python's language design choices. –
Steak
@Steak In your example, should the increment happen before or after the array index? It's certainly not clear with the
a[x+=1] syntax (which is not allowed in python because x+=1 is a statement, not an expression). With x++ / ++x it's unambiguous, but there is the cognitive overhead of differentiating between the two, which ultimately makes the code less readable. Readable code certainly is a consistent with Python's design decisions. But anyway, integers are immutable objects in Python, so implementing auto-increment operators on them is impossible as that requires mutation. –
Barnum I don't really see the cognitive overhead being that significant - at least not significant enough to outweigh the negatives of not having this feature in certain use cases (IMO). Primitives are immutable in JS, and yet it has increment and decrement operators (statement vs expression, etc.). But it seems hard to claim it's impossible, since Python is such a high-level language. If people can hack it in with decorators (github.com/borzunov/plusplus), then using the word "impossible" seems a little too strong. –
Steak
@NathanDavis (your last comment) You say "certainly not clear". To me, personally, in languages such as C or C#, it is very obvious what
a[x+=1] does. This is allowed in these languages. Have you ever met any coders that were unsure what the return value of a compound assignment was? But I always have to think twice before I am sure if it is a[x++] or a[++x] that is equivalent to a[x+=1]. I think many people find it difficult to remember which is which, x++ and ++x. But maybe I am repeating your point ("cognitive overload")? –
Tam Clarity!
Python is a lot about clarity and no programmer is likely to correctly guess the meaning of --a unless s/he's learned a language having that construct.
Python is also a lot about avoiding constructs that invite mistakes and the ++ operators are known to be rich sources of defects.
These two reasons are enough not to have those operators in Python.
The decision that Python uses indentation to mark blocks rather than syntactical means such as some form of begin/end bracketing or mandatory end marking is based largely on the same considerations.
For illustration, have a look at the discussion around introducing a conditional operator (in C: cond ? resultif : resultelse) into Python in 2005.
Read at least the first message and the decision message of that discussion (which had several precursors on the same topic previously).
Trivia: The PEP frequently mentioned therein is the "Python Enhancement Proposal" PEP 308. LC means list comprehension, GE means generator expression (and don't worry if those confuse you, they are none of the few complicated spots of Python).
Behaviour like f"{1:03}" (pads a string with leading zeros) is totally clear and intuitive, but decades old programming patterns present in almost every programming language aren't. Got it. –
Karlmarxstadt
My understanding of why python does not have ++ operator is following: When you write this in python a=b=c=1 you will get three variables (labels) pointing at same object (which value is 1). You can verify this by using id function which will return an object memory address:
In [19]: id(a)
Out[19]: 34019256
In [20]: id(b)
Out[20]: 34019256
In [21]: id(c)
Out[21]: 34019256
All three variables (labels) point to the same object. Now increment one of variable and see how it affects memory addresses:
In [22] a = a + 1
In [23]: id(a)
Out[23]: 34019232
In [24]: id(b)
Out[24]: 34019256
In [25]: id(c)
Out[25]: 34019256
You can see that variable a now points to another object as variables b and c. Because you've used a = a + 1 it is explicitly clear. In other words you assign completely another object to label a. Imagine that you can write a++ it would suggest that you did not assign to variable a new object but ratter increment the old one. All this stuff is IMHO for minimization of confusion. For better understanding see how python variables works:
In Python, why can a function modify some arguments as perceived by the caller, but not others?
Is Python call-by-value or call-by-reference? Neither.
Does Python pass by value, or by reference?
Is Python pass-by-reference or pass-by-value?
Python: How do I pass a variable by reference?
Understanding Python variables and Memory Management
Emulating pass-by-value behaviour in python
It was just designed that way. Increment and decrement operators are just shortcuts for x = x + 1. Python has typically adopted a design strategy which reduces the number of alternative means of performing an operation. Augmented assignment is the closest thing to increment/decrement operators in Python, and they weren't even added until Python 2.0.
Yeah mate, like, you could replace
return a[i++] with return a[i=i+1]. –
Saveall I'm very new to python but I suspect the reason is because of the emphasis between mutable and immutable objects within the language. Now, I know that x++ can easily be interpreted as x = x + 1, but it LOOKS like you're incrementing in-place an object which could be immutable.
Just my guess/feeling/hunch.
In this aspect,
x++ is closer to x += 1 than to x = x + 1, these two making a difference as well on mutable objects. –
Cameo To complete already good answers on that page:
Let's suppose we decide to do this, prefix (++i) that would break the unary + and - operators.
Today, prefixing by ++ or -- does nothing, because it enables unary plus operator twice (does nothing) or unary minus twice (twice: cancels itself)
>>> i=12
>>> ++i
12
>>> --i
12
So that would potentially break that logic.
now if one needs it for list comprehensions or lambdas, from python 3.8 it's possible with the new := assignment operator (PEP572)
pre-incrementing a and assign it to b:
>>> a = 1
>>> b = (a:=a+1)
>>> b
2
>>> a
2
post-incrementing just needs to make up the premature add by subtracting 1:
>>> a = 1
>>> b = (a:=a+1)-1
>>> b
1
>>> a
2
I believe it stems from the Python creed that "explicit is better than implicit".
Well, you don't explicitly write "begin" and "end" statements in Python, right? Even though I agree with the statement, I think there are boundaries to that. While we can argue on that boundaries, I think we all can agree, that there is a line, which is impractical to cross. And since there are so many opinions and justifications on that decision, I don't think it was a clear choice. At least, I can't find a source, where it is explicitly stated –
Sophisticated
First, Python is only indirectly influenced by C; it is heavily influenced by ABC, which apparently does not have these operators, so it should not be any great surprise not to find them in Python either.
Secondly, as others have said, increment and decrement are supported by += and -= already.
Third, full support for a ++ and -- operator set usually includes supporting both the prefix and postfix versions of them. In C and C++, this can lead to all kinds of "lovely" constructs that seem (to me) to be against the spirit of simplicity and straight-forwardness that Python embraces.
For example, while the C statement while(*t++ = *s++); may seem simple and elegant to an experienced programmer, to someone learning it, it is anything but simple. Throw in a mixture of prefix and postfix increments and decrements, and even many pros will have to stop and think a bit.
The ++ class of operators are expressions with side effects. This is something generally not found in Python.
For the same reason an assignment is not an expression in Python, thus preventing the common if (a = f(...)) { /* using a here */ } idiom.
Lastly I suspect that there operator are not very consistent with Pythons reference semantics. Remember, Python does not have variables (or pointers) with the semantics known from C/C++.
nothing prevents from calling a function with a side-effect in a test / expression / list comprehension:
f(a) where a is a list, some immutable object. –
Moderation as i understood it so you won't think the value in memory is changed. in c when you do x++ the value of x in memory changes. but in python all numbers are immutable hence the address that x pointed as still has x not x+1. when you write x++ you would think that x change what really happens is that x refrence is changed to a location in memory where x+1 is stored or recreate this location if doe's not exists.
So what makes this
++ and different from += 1? –
Tearing Other answers have described why it's not needed for iterators, but sometimes it is useful when assigning to increase a variable in-line, you can achieve the same effect using tuples and multiple assignment:
b = ++a becomes:
a,b = (a+1,)*2
and b = a++ becomes:
a,b = a+1, a
Python 3.8 introduces the assignment := operator, allowing us to achievefoo(++a) with
foo(a:=a+1)
foo(a++) is still elusive though.
:= assignement is a disgrace –
Desexualize
Maybe a better question would be to ask why do these operators exist in C. K&R calls increment and decrement operators 'unusual' (Section 2.8page 46). The Introduction calls them 'more concise and often more efficient'. I suspect that the fact that these operations always come up in pointer manipulation also has played a part in their introduction. In Python it has been probably decided that it made no sense to try to optimise increments (in fact I just did a test in C, and it seems that the gcc-generated assembly uses addl instead of incl in both cases) and there is no pointer arithmetic; so it would have been just One More Way to Do It and we know Python loathes that.
This may be because @GlennMaynard is looking at the matter as in comparison with other languages, but in Python, you do things the python way. It's not a 'why' question. It's there and you can do things to the same effect with x+=. In The Zen of Python, it is given: "there should only be one way to solve a problem." Multiple choices are great in art (freedom of expression) but lousy in engineering.
In that case, there shouldn't even be +=. Just always write out x=x+1. –
Vyner
@Vyner Well, the post misquoted The Zen of Python. The relevant line is, "There should be one-- and preferably only one --obvious way to do it." Which of
x += 1 and x = x + 1 is more elegant is pretty obvious. The same isn't true of x += 1 and x++ because having a ++ operator introduces problems that the += operator doesn't have. –
Gaitan I think this relates to the concepts of mutability and immutability of objects. 2,3,4,5 are immutable in python. Refer to the image below. 2 has fixed id until this python process.
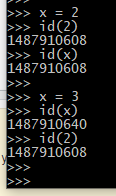
x++ would essentially mean an in-place increment like C. In C, x++ performs in-place increments. So, x=3, and x++ would increment 3 in the memory to 4, unlike python where 3 would still exist in memory.
Thus in python, you don't need to recreate a value in memory. This may lead to performance optimizations.
This is a hunch based answer.
I know this is an old thread, but the most common use case for ++i is not covered, that being manually indexing sets when there are no provided indices. This situation is why python provides enumerate()
Example : In any given language, when you use a construct like foreach to iterate over a set - for the sake of the example we'll even say it's an unordered set and you need a unique index for everything to tell them apart, say
i = 0
stuff = {'a': 'b', 'c': 'd', 'e': 'f'}
uniquestuff = {}
for key, val in stuff.items() :
uniquestuff[key] = '{0}{1}'.format(val, i)
i += 1
In cases like this, python provides an enumerate method, e.g.
for i, (key, val) in enumerate(stuff.items()) :
In addition to the other excellent answers here, ++ and -- are also notorious for undefined behavior. For example, what happens in this code?
foo[bar] = bar++;
It's so innocent-looking, but it's wrong C (and C++), because you don't know whether the first bar will have been incremented or not. One compiler might do it one way, another might do it another way, and a third might make demons fly out of your nose. All would be perfectly conformant with the C and C++ standards.
(EDIT: C++17 has changed the behavior of the given code so that it is defined; it will be equivalent to foo[bar+1] = bar; ++bar; — which nonetheless might not be what the programmer is expecting.)
Undefined behavior is seen as a necessary evil in C and C++, but in Python, it's just evil, and avoided as much as possible.
© 2022 - 2024 — McMap. All rights reserved.