How can I write a stored procedure that imports data from a CSV file and populates the table?
How to import CSV file data into a PostgreSQL table
Asked Answered
Why a stored procedure? COPY does the trick –
Bil
I have a user interface that uploads the csv file, to hook up this i need the stored procedure that actually copies the data from the cvs file –
Achromatin
That's what COPY does... –
Bil
could you elaborate on how to use the COPY ? –
Achromatin
Bozhidar Batsov already gave you a link to an example, the fine manual could also help: postgresql.org/docs/8.4/interactive/sql-copy.html –
Bil
Current manual: postgresql.org/docs/current/static/sql-copy.html –
Apoplectic
Related: #17663131 –
Casino
See this answer: https://mcmap.net/q/55280/-postgresql-csv-import-from-command-line –
Allyce
If you have IntelliJ you may try right click on a table and "Import data from file". It's much better than import from pgAdmin and doesn't have limitations of the COPY statement –
Taitaichung
Take a look at this short article.
The solution is paraphrased here:
Create your table:
CREATE TABLE zip_codes
(ZIP char(5), LATITUDE double precision, LONGITUDE double precision,
CITY varchar, STATE char(2), COUNTY varchar, ZIP_CLASS varchar);
Copy data from your CSV file to the table:
COPY zip_codes FROM '/path/to/csv/ZIP_CODES.txt' WITH (FORMAT csv);
actually use \copy would do the same trick if you do not have the super user access; it complaints on my Fedora 16 when using COPY with a non-root account. –
Vesiculate
TIP: you can indicate what columns you have in the CSV using zip_codes(col1, col2, col3). The columns must be listed in the same order that they appear in the file. –
Bandolier
@Vesiculate does \copy have the same syntax? bcoz I'm getting a syntax error with \copy –
Indamine
Should I include the header row? –
Catechol
You can easily include the header row -- just add HEADER in the options:
COPY zip_codes FROM '/path/to/csv/ZIP_CODES.txt' DELIMITER ',' CSV HEADER; postgresql.org/docs/9.1/static/sql-copy.html –
Exorbitant This is REALLY COOL... I typed the copy statement in a query window using PGAdmin and it works beautifully. –
Prismoid
How to use (at client
psql) FROM ./relativePath/file ? Not works for me –
Transceiver Will this overwrite data in an existing table, or append it? –
Eldridge
@AndyRay " while COPY FROM copies data from a file to a table (appending the data to whatever is in the table already)" from the manual on the link above. postgresql.org/docs/current/static/sql-copy.html. –
Agostino
If you have NULL values in your CSV, define them using the
NULL AS flag: COPY zip_codes FROM '/path/to/csv/ZIP_CODES.txt' DELIMITER ',' CSV NULL AS '<your null value>';. Replace <your null value> with whatever you have in your CSV, often "NULL" or "". –
Gratian If you don't have permission to use COPY (which work on the db server), you can use \copy instead (which works in the db client). Using the same example as Bozhidar Batsov:
Create your table:
CREATE TABLE zip_codes
(ZIP char(5), LATITUDE double precision, LONGITUDE double precision,
CITY varchar, STATE char(2), COUNTY varchar, ZIP_CLASS varchar);
Copy data from your CSV file to the table:
\copy zip_codes FROM '/path/to/csv/ZIP_CODES.txt' DELIMITER ',' CSV
Mind that \copy ... must be written in one line and without a ; at the end!
You can also specify the columns to read:
\copy zip_codes(ZIP,CITY,STATE) FROM '/path/to/csv/ZIP_CODES.txt' DELIMITER ',' CSV
See the documentation for COPY:
Do not confuse COPY with the psql instruction \copy. \copy invokes COPY FROM STDIN or COPY TO STDOUT, and then fetches/stores the data in a file accessible to the psql client. Thus, file accessibility and access rights depend on the client rather than the server when \copy is used.
And note:
For identity columns, the COPY FROM command will always write the column values provided in the input data, like the INSERT option OVERRIDING SYSTEM VALUE.
\copy voters(ZIP,CITY) FROM '/Users/files/Downloads/WOOD.TXT' DELIMITER ',' CSV HEADER; ERROR: extra data after last expected column CONTEXT: COPY voters, line 2: "OH0012781511,87,26953,HOUSEHOLDER,SHERRY,LEIGH,,11/26/1965,08/19/1988,,211 N GARFIELD ST , ,BLOOMD..." –
Dolhenty
@Dolhenty I had a similar error. It was because I had extra blank columns. Check your csv and if you have blank columns, that could be the reason. –
Yankeeism
This is somewhat misleading: the difference between
COPY and \copy is much more than just permissions, and you can't simply add a `` to make it magically work. See the description (in the context of export) here: https://mcmap.net/q/45638/-save-pl-pgsql-output-from-postgresql-to-a-csv-file –
Thermolabile @IMSoP: you're right, I added a mention of server and client to clarify –
Refit
@Refit is \copy slower than copy? I have a 1.5MB file and a db.m4.large instance on RDS and it's been hours that this copy command has been running (at least 3). –
Indophenol
@Sebastian: the important difference is that \copy works from the client. so you still have to transmit all the data to the server. with COPY (no slash) you first upload all the data to the server with other means (sftp, scp) and then do the import on the server. but transmitting 1.5 MB does not sound like it should talk 3 hours - no matter which way you do it. –
Refit
This worked for me, and I use Windows OS - just change the (absolute) path formatting style. It's good to know that this method is easy to learn and implement as I have been trying to do the same procedure with SQL and it does not work as easy as this method. –
Accolade
I am very confused about the distinction of \copy on client and copy on server, since mysql, mariadb do not have such concepts to trouble users. –
Grandniece
I tried to import 16Gb but I got error: ERROR: out of memory DETAIL: Cannot enlarge string buffer containing 1073725476 bytes by 65536 more bytes. –
Learnt
@Learnt this is a separate question, answered here: #56714774 –
Refit
This gives me ERROR: syntax error at or near "\" Position: 1 –
We
Mind that
\copy ... must be written in one line and without a ; at the end. This should at best be included in the answer since some comments here show that this is not always clear. My edit got rejected. [Another thing: if you have a header row, add HEADER at the end.] –
Sulphonamide One quick way of doing this is with the Python Pandas library (version 0.15 or above works best). This will handle creating the columns for you - although obviously the choices it makes for data types might not be what you want. If it doesn't quite do what you want you can always use the 'create table' code generated as a template.
Here's a simple example:
import pandas as pd
df = pd.read_csv('mypath.csv')
df.columns = [c.lower() for c in df.columns] # PostgreSQL doesn't like capitals or spaces
from sqlalchemy import create_engine
engine = create_engine('postgresql://username:password@localhost:5432/dbname')
df.to_sql("my_table_name", engine)
And here's some code that shows you how to set various options:
# Set it so the raw SQL output is logged
import logging
logging.basicConfig()
logging.getLogger('sqlalchemy.engine').setLevel(logging.INFO)
df.to_sql("my_table_name2",
engine,
if_exists="append", # Options are ‘fail’, ‘replace’, ‘append’, default ‘fail’
index = False, # Do not output the index of the dataframe
dtype = {'col1': sqlalchemy.types.NUMERIC,
'col2': sqlalchemy.types.String}) # Datatypes should be SQLAlchemy types
In addition, the
if_exists parameter can be set to replace or append to an existing table, e.g. df.to_sql("fhrs", engine, if_exists='replace') –
Sheilasheilah username and password : need to create Login and assign DB to user. If uses pgAdmin, then create "Login/Group role" using GUI –
Reade
Pandas is a super slow way of loading to sql (vs csv files). Can be orders of magnitude slower. –
Sciatica
This could be a way to write data but it is super slow even with batch and good computing power. Using CSVs is a good way to accomplish this. –
Thenceforth
df.to_sql() is really slow, you can use d6tstack.utils.pd_to_psql() from d6tstack see performance comparison –
Acreinch Most other solutions here require that you create the table in advance/manually. This may not be practical in some cases (e.g., if you have a lot of columns in the destination table). So, the approach below may come handy.
Providing the path and column count of your CSV file, you can use the following function to load your table to a temp table that will be named as target_table:
The top row is assumed to have the column names.
create or replace function data.load_csv_file
(
target_table text,
csv_path text,
col_count integer
)
returns void as $$
declare
iter integer; -- dummy integer to iterate columns with
col text; -- variable to keep the column name at each iteration
col_first text; -- first column name, e.g., top left corner on a csv file or spreadsheet
begin
create table temp_table ();
-- add just enough number of columns
for iter in 1..col_count
loop
execute format('alter table temp_table add column col_%s text;', iter);
end loop;
-- copy the data from csv file
execute format('copy temp_table from %L with delimiter '','' quote ''"'' csv ', csv_path);
iter := 1;
col_first := (select col_1 from temp_table limit 1);
-- update the column names based on the first row which has the column names
for col in execute format('select unnest(string_to_array(trim(temp_table::text, ''()''), '','')) from temp_table where col_1 = %L', col_first)
loop
execute format('alter table temp_table rename column col_%s to %s', iter, col);
iter := iter + 1;
end loop;
-- delete the columns row
execute format('delete from temp_table where %s = %L', col_first, col_first);
-- change the temp table name to the name given as parameter, if not blank
if length(target_table) > 0 then
execute format('alter table temp_table rename to %I', target_table);
end if;
end;
$$ language plpgsql;
Hi Mehmet, thanks for the answer you posted but when I run your code I get the following error message : ERROR: schema "data" does not exist –
Ruthanneruthe
user2867432 you need to change schema name that you use accordingly (e.g.,
public) –
Malay Hi Mehmet, Thanks for solution, it's perfect but This works only if the postgres DB user is superuser, is ther any way to make it work without superuser? –
Fixity
Geeme: read "security definer" here, but I have not used it myself. –
Malay
Beautiful answer! I am not going to too generic though in my code for readability for others. –
Lebeau
Dear @mehmet, thank you for great function! Indeed, other answers are neglecting that importing csv file should include step of creating table schema, not only inserting data. I would suggest you to correct the code with quote_ident(col) and quote_ident(col_first) for situations where column names in csv file have mixed case. –
Yesima
and one info - if import is not working due to insufficient user rights for COPY command, then in Windows, files to be uploaded should be placed into C:\Users\Public\, while in Linux similarly into /tmp. –
Yesima
You could also use pgAdmin, which offers a GUI to do the import. That's shown in this SO thread. The advantage of using pgAdmin is that it also works for remote databases.
Much like the previous solutions though, you would need to have your table on the database already. Each person has his own solution, but I usually open the CSV file in Excel, copy the headers, paste special with transposition on a different worksheet, place the corresponding data type on the next column, and then just copy and paste that to a text editor together with the appropriate SQL table creation query like so:
CREATE TABLE my_table (
/* Paste data from Excel here for example ... */
col_1 bigint,
col_2 bigint,
/* ... */
col_n bigint
)
pls show a couple of sample rows of your pasted data –
Outdated
Create a table first
Then use the copy command to copy the table details:
copy table_name (C1,C2,C3....) from 'path to your CSV file' delimiter ',' csv header;
NOTE:
- columns and order are specified by
C1,C2,C3..in SQL - The
headeroption just skips one line from the input, not according to columns' name.
How is this not the accepted answer? Why would I write a python script when the database already has a command to do this? –
Maryannmaryanna
COPY table_name FROM 'path/to/data.csv' DELIMITER ',' CSV HEADER;
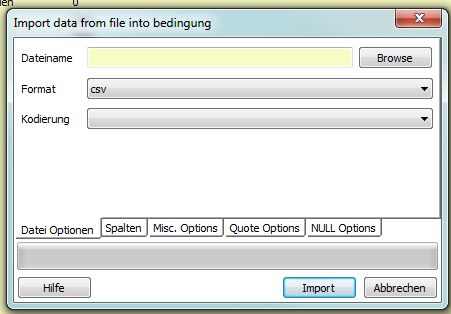
As Paul mentioned, import works in pgAdmin:
Right-click on table → Import
Select a local file, format and coding.
Here is a German pgAdmin GUI screenshot:
A similar thing you can do with DbVisualizer (I have a license and am not sure about free version).
Right-click on a table → Import Table Data...
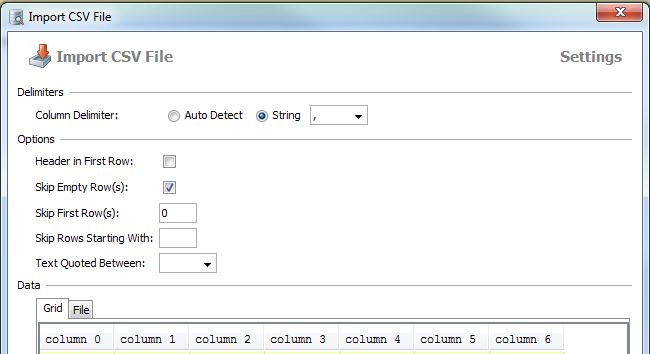
DBVisualizer took 50 seconds to import 1400 rows with three fields -- and I had to cast everything back from a String to whatever it was supposed to be. –
Magneto
How to import CSV file data into a PostgreSQL table
Steps:
Need to connect a PostgreSQL database in the terminal
psql -U postgres -h localhostNeed to create a database
create database mydb;Need to create a user
create user siva with password 'mypass';Connect with the database
\c mydb;Need to create a schema
create schema trip;Need to create a table
create table trip.test(VendorID int,passenger_count int,trip_distance decimal,RatecodeID int,store_and_fwd_flag varchar,PULocationID int,DOLocationID int,payment_type decimal,fare_amount decimal,extra decimal,mta_tax decimal,tip_amount decimal,tolls_amount int,improvement_surcharge decimal,total_amount );Import csv file data to postgresql
COPY trip.test(VendorID int,passenger_count int,trip_distance decimal,RatecodeID int,store_and_fwd_flag varchar,PULocationID int,DOLocationID int,payment_type decimal,fare_amount decimal,extra decimal,mta_tax decimal,tip_amount decimal,tolls_amount int,improvement_surcharge decimal,total_amount) FROM '/home/Documents/trip.csv' DELIMITER ',' CSV HEADER;Find the given table data
select * from trip.test;
Why do we need datatype on the copy command? I mean on step 7 –
Deodar
Use this SQL code:
copy table_name(atribute1,attribute2,attribute3...)
from 'E:\test.csv' delimiter ',' csv header
The header keyword lets the DBMS know that the CSV file have a header with attributes.
For more, visit Import CSV File Into PostgreSQL Table.
This is a personal experience with PostgreSQL, and I am still waiting for a faster way.
Create a table skeleton first if the file is stored locally:
drop table if exists ur_table; CREATE TABLE ur_table ( id serial NOT NULL, log_id numeric, proc_code numeric, date timestamp, qty int, name varchar, price money ); COPY ur_table(id, log_id, proc_code, date, qty, name, price) FROM '\path\xxx.csv' DELIMITER ',' CSV HEADER;When the \path\xxx.csv file is on the server, PostgreSQL doesn't have the permission to access the server. You will have to import the .csv file through the pgAdmin built in functionality.
Right click the table name and choose import.
![Enter image description here]()
If you still have the problem, please refer this tutorial: Import CSV File Into PostgreSQL Table
You can also use pgfutter, or, even better, pgcsv.
These tools create the table columns from you, based on the CSV header.
pgfutter is quite buggy, and I'd recommend pgcsv.
Here's how to do it with pgcsv:
sudo pip install pgcsv
pgcsv --db 'postgresql://localhost/postgres?user=postgres&password=...' my_table my_file.csv
In Python, you can use this code for automatic PostgreSQL table creation with column names:
import pandas, csv
from io import StringIO
from sqlalchemy import create_engine
def psql_insert_copy(table, conn, keys, data_iter):
dbapi_conn = conn.connection
with dbapi_conn.cursor() as cur:
s_buf = StringIO()
writer = csv.writer(s_buf)
writer.writerows(data_iter)
s_buf.seek(0)
columns = ', '.join('"{}"'.format(k) for k in keys)
if table.schema:
table_name = '{}.{}'.format(table.schema, table.name)
else:
table_name = table.name
sql = 'COPY {} ({}) FROM STDIN WITH CSV'.format(table_name, columns)
cur.copy_expert(sql=sql, file=s_buf)
engine = create_engine('postgresql://user:password@localhost:5432/my_db')
df = pandas.read_csv("my.csv")
df.to_sql('my_table', engine, schema='my_schema', method=psql_insert_copy)
It's also relatively fast. I can import more than 3.3 million rows in about 4 minutes.
DBeaver Community Edition (dbeaver.io) makes it trivial to connect to a database, then import a CSV file for upload to a PostgreSQL database. It also makes it easy to issue queries, retrieve data, and download result sets to CSV, JSON, SQL, or other common data formats.
It is a FOSS multi-platform database tool for SQL programmers, DBAs and analysts that supports all popular databases: MySQL, PostgreSQL, SQLite, Oracle, DB2, SQL Server, Sybase, MS Access, Teradata, Firebird, Hive, Presto, etc. It's a viable FOSS competitor to TOAD for Postgres, TOAD for SQL Server, or Toad for Oracle.
I have no affiliation with DBeaver. I love the price (FREE!) and full functionality, but I wish they would open up this DBeaver/Eclipse application more and make it easy to add analytics widgets to DBeaver / Eclipse, rather than requiring users to pay for the $199 annual subscription just to create graphs and charts directly within the application. My Java coding skills are rusty and I don't feel like taking weeks to relearn how to build Eclipse widgets, (only to find that DBeaver has probably disabled the ability to add third-party widgets to the DBeaver Community Edition.)
It would have been nice to understand how to actually use DBeaver to import a CSV file. Anyway, this might help: dbeaver.com/docs/wiki/Data-transfer –
Benediction
Peter suggested that I move this question to comments: "Can DBeaver power users who are Java developers provide some insight about the steps to create analytics widgets to add into the Community Edition of DBeaver? " I would like to know if the analytics plugins are also open source, and how to create them. –
Doctrine
You can create a Bash file as import.sh (that your CSV format is a tab delimiter):
#!/usr/bin/env bash
USER="test"
DB="postgres"
TBALE_NAME="user"
CSV_DIR="$(pwd)/csv"
FILE_NAME="user.txt"
echo $(psql -d $DB -U $USER -c "\copy $TBALE_NAME from '$CSV_DIR/$FILE_NAME' DELIMITER E'\t' csv" 2>&1 |tee /dev/tty)
And then run this script.
What do you mean by "your CSV format is a tab delimiter"? –
Cohbert
You can use the Pandas library if the file is not very large.
Be careful when using iter over Pandas dataframes. I am doing this here to demonstrate the possibility. One could also consider the pd.Dataframe.to_sql() function when copying from a dataframe to an SQL table.
Assuming you have created the table you want, you could:
import psycopg2
import pandas as pd
data=pd.read_csv(r'path\to\file.csv', delimiter=' ')
#prepare your data and keep only relevant columns
data.drop(['col2', 'col4','col5'], axis=1, inplace=True)
data.dropna(inplace=True)
print(data.iloc[:3])
conn=psycopg2.connect("dbname=db user=postgres password=password")
cur=conn.cursor()
for index,row in data.iterrows():
cur.execute('''insert into table (col1,col3,col6)
VALUES (%s,%s,%s)''', (row['col1'], row['col3'], row['col6'])
cur.close()
conn.commit()
conn.close()
print('\n db connection closed.')
If you need a simple mechanism to import from text/parse multiline CSV content, you could use:
CREATE TABLE t -- OR INSERT INTO tab(col_names)
AS
SELECT
t.f[1] AS col1
,t.f[2]::int AS col2
,t.f[3]::date AS col3
,t.f[4] AS col4
FROM (
SELECT regexp_split_to_array(l, ',') AS f
FROM regexp_split_to_table(
$$a,1,2016-01-01,bbb
c,2,2018-01-01,ddd
e,3,2019-01-01,eee$$, '\n') AS l) t;
I created a small tool that imports csv file into PostgreSQL super easy. It is just a command and it will create and populate the tables, but unfortunately, at the moment, all fields automatically created uses the type TEXT:
csv2pg users.csv -d ";" -H 192.168.99.100 -U postgres -B mydatabase
The tool can be found on https://github.com/eduardonunesp/csv2pg
You made a separate tool for the equivalent of
psql -h 192.168.99.100 -U postgres mydatabase -c "COPY users FROM 'users.csv' DELIMITER ';' CSV"? I guess the part where it creates the table is nice, but since every field is text it's not super useful –
Starstarboard Ops, thanks for the heads up. Yes, I did it, well it took just a few hours and I learned cool stuff in Go and pq and database API in Go. –
Caterpillar
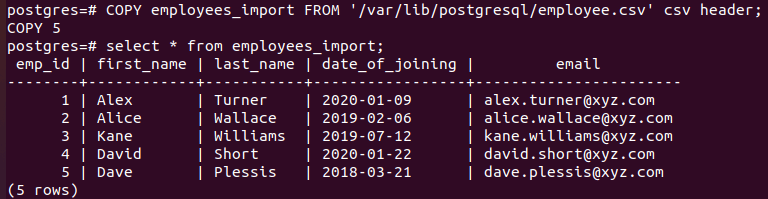
You have 3 options to import CSV files to PostgreSQL: First, using the COPY command through the command line.
Second, using the pgAdmin tool’s import/export.
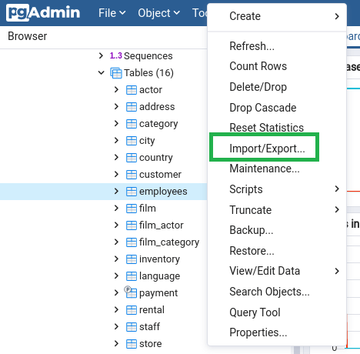
Third, using a cloud solution like Skyvia which gets the CSV file from an online location like an FTP source or a cloud storage like Google Drive.
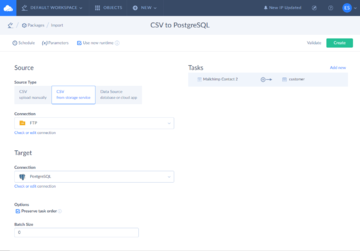
You can check out the article that explains all of these from here.
Please review Why not upload images of code/errors when asking a question? (e.g., "Images should only be used to illustrate problems that can't be made clear in any other way, such as to provide screenshots of a user interface.) and take the appropriate action (it covers answers as well). Thanks in advance. –
Cohbert
It applies at least to the first image. The last image is unreadable (possibly lost fidelity due to falsely being converted to JPEG (unsuitable for screenshots)). –
Cohbert
Create a table and have the required columns that are used for creating a table in the CSV file.
Open postgres and right click on the target table which you want to load. Select import and Update the following steps in the file options section
Now browse your file for the filename
Select CSV in format
Encoding as ISO_8859_5
Now go to Misc. options. Check header and click on import.
These are some great answers but over complicated for me. I just need to load in a CSV file into postgreSQL without creating a table first.
Here is my way:
libraries
import pandas as pd
import os
import psycopg2 as pg
from sqlalchemy import create_engine
Use environmental Variable to get your password
password = os.environ.get('PSW')
create our engine
engine = create_engine(f"postgresql+psycopg2://postgres:{password}@localhost:5432/postgres")
The break down of engine requirements:
- engine = create_engine(dialect+driver://username:password@host:port/database)
Break Down
- postgresql+psycopg2 = dialect+driver
- postgres = username
- password = password from my environmental variable. You can type in password if needed but not recommended
- localhost = host
- 5432 = port
- postgres = database
Get your CSV file path, I had to use an encoding aspect. reason why can be found Here
data = pd.read_csv(r"path, encoding= 'unicode_escape')
Send data to Postgress SQL:
data.to_sql('test', engine, if_exists='replace')
Break Down
- test = table name you want table to be
- engine = engine created above. AKA our connection
- if_exsists = will replace old table if there. Use this with caution.
All Together:
import pandas as pd
import os
import psycopg2 as pg
from sqlalchemy import create_engine
password = os.environ.get('PSW')
engine = create_engine(f"postgresql+psycopg2://postgres:{password}@localhost:5432/postgres")
data = pd.read_csv(r"path, encoding= 'unicode_escape')
data.to_sql('test', engine, if_exists='replace')
© 2022 - 2024 — McMap. All rights reserved.