Quick Answer:
The simplest way to get row counts per group is by calling .size(), which returns a Series:
df.groupby(['col1','col2']).size()
Usually you want this result as a DataFrame (instead of a Series) so you can do:
df.groupby(['col1', 'col2']).size().reset_index(name='counts')
If you want to find out how to calculate the row counts and other statistics for each group continue reading below.
Detailed example:
Consider the following example dataframe:
In [2]: df
Out[2]:
col1 col2 col3 col4 col5 col6
0 A B 0.20 -0.61 -0.49 1.49
1 A B -1.53 -1.01 -0.39 1.82
2 A B -0.44 0.27 0.72 0.11
3 A B 0.28 -1.32 0.38 0.18
4 C D 0.12 0.59 0.81 0.66
5 C D -0.13 -1.65 -1.64 0.50
6 C D -1.42 -0.11 -0.18 -0.44
7 E F -0.00 1.42 -0.26 1.17
8 E F 0.91 -0.47 1.35 -0.34
9 G H 1.48 -0.63 -1.14 0.17
First let's use .size() to get the row counts:
In [3]: df.groupby(['col1', 'col2']).size()
Out[3]:
col1 col2
A B 4
C D 3
E F 2
G H 1
dtype: int64
Then let's use .size().reset_index(name='counts') to get the row counts:
In [4]: df.groupby(['col1', 'col2']).size().reset_index(name='counts')
Out[4]:
col1 col2 counts
0 A B 4
1 C D 3
2 E F 2
3 G H 1
Including results for more statistics
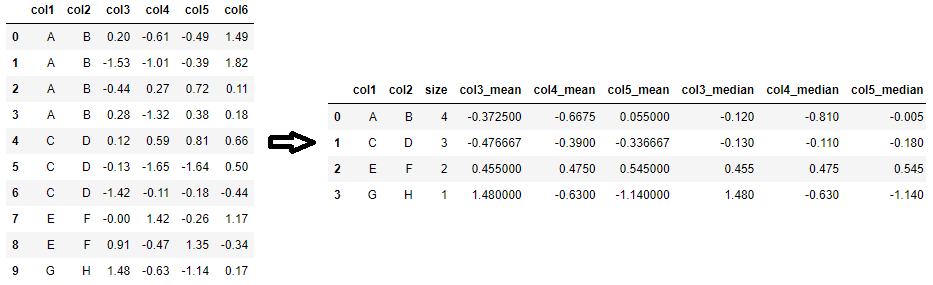
When you want to calculate statistics on grouped data, it usually looks like this:
In [5]: (df
...: .groupby(['col1', 'col2'])
...: .agg({
...: 'col3': ['mean', 'count'],
...: 'col4': ['median', 'min', 'count']
...: }))
Out[5]:
col4 col3
median min count mean count
col1 col2
A B -0.810 -1.32 4 -0.372500 4
C D -0.110 -1.65 3 -0.476667 3
E F 0.475 -0.47 2 0.455000 2
G H -0.630 -0.63 1 1.480000 1
The result above is a little annoying to deal with because of the nested column labels, and also because row counts are on a per column basis.
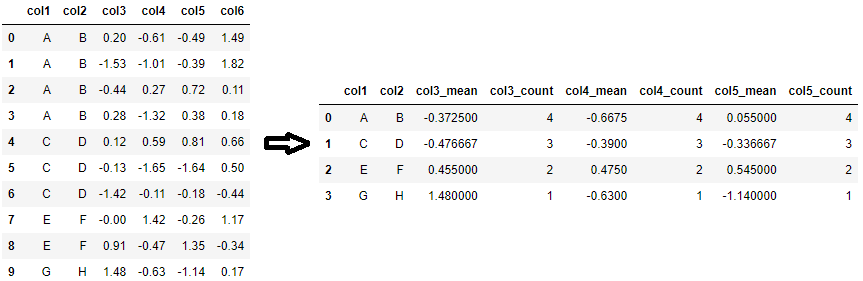
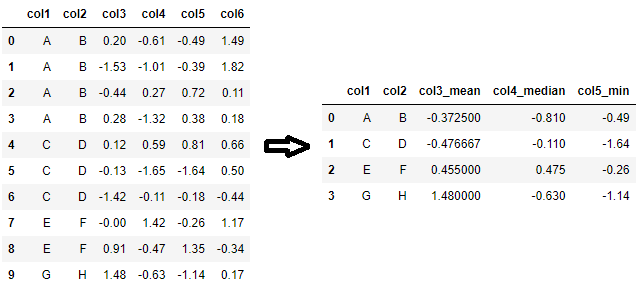
To gain more control over the output I usually split the statistics into individual aggregations that I then combine using join. It looks like this:
In [6]: gb = df.groupby(['col1', 'col2'])
...: counts = gb.size().to_frame(name='counts')
...: (counts
...: .join(gb.agg({'col3': 'mean'}).rename(columns={'col3': 'col3_mean'}))
...: .join(gb.agg({'col4': 'median'}).rename(columns={'col4': 'col4_median'}))
...: .join(gb.agg({'col4': 'min'}).rename(columns={'col4': 'col4_min'}))
...: .reset_index()
...: )
...:
Out[6]:
col1 col2 counts col3_mean col4_median col4_min
0 A B 4 -0.372500 -0.810 -1.32
1 C D 3 -0.476667 -0.110 -1.65
2 E F 2 0.455000 0.475 -0.47
3 G H 1 1.480000 -0.630 -0.63
Footnotes
The code used to generate the test data is shown below:
In [1]: import numpy as np
...: import pandas as pd
...:
...: keys = np.array([
...: ['A', 'B'],
...: ['A', 'B'],
...: ['A', 'B'],
...: ['A', 'B'],
...: ['C', 'D'],
...: ['C', 'D'],
...: ['C', 'D'],
...: ['E', 'F'],
...: ['E', 'F'],
...: ['G', 'H']
...: ])
...:
...: df = pd.DataFrame(
...: np.hstack([keys,np.random.randn(10,4).round(2)]),
...: columns = ['col1', 'col2', 'col3', 'col4', 'col5', 'col6']
...: )
...:
...: df[['col3', 'col4', 'col5', 'col6']] = \
...: df[['col3', 'col4', 'col5', 'col6']].astype(float)
...:
Disclaimer:
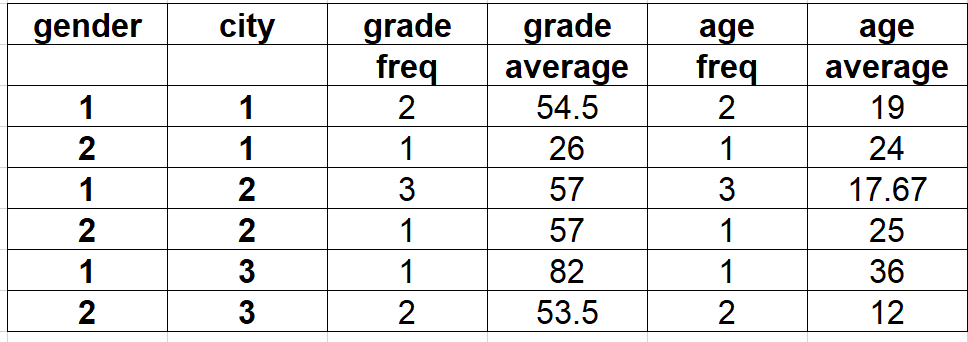
If some of the columns that you are aggregating have null values, then you really want to be looking at the group row counts as an independent aggregation for each column. Otherwise you may be misled as to how many records are actually being used to calculate things like the mean because pandas will drop NaN entries in the mean calculation without telling you about it.