I have run the below code for 522 gzip files of size 100 GB and after decompressing, it will be around 320 GB data and data in protobuf format and write the output to GCS. I have used n1 standard machines and region for input, output all taken care and job cost me around 17$, this is for half-hour data and so I really need to do some cost optimization here very badly.
Cost I get from the below query
SELECT l.value AS JobID, ROUND(SUM(cost),3) AS JobCost
FROM `PROJECT.gcp_billing_data.gcp_billing_export_v1_{}` bill,
UNNEST(bill.labels) l
WHERE service.description = 'Cloud Dataflow' and l.key = 'goog-dataflow-job-id' and
extract(date from _PARTITIONTIME) > "2020-12-31"
GROUP BY 1
Complete code
import time
import sys
import argparse
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
import csv
import base64
from google.protobuf import timestamp_pb2
from google.protobuf.json_format import MessageToDict
from google.protobuf.json_format import MessageToJson
import io
import logging
from io import StringIO
from google.cloud import storage
import json
###PROTOBUF CLASS
from otherfiles import processor_pb2
class ConvertToJson(beam.DoFn):
def process(self, message, *args, **kwargs):
import base64
from otherfiles import processor_pb2
from google.protobuf.json_format import MessageToDict
from google.protobuf.json_format import MessageToJson
import json
if (len(message) >= 4):
b64ProtoData = message[2]
totalProcessorBids = int(message[3] if message[3] and message[3] is not None else 0);
b64ProtoData = b64ProtoData.replace('_', '/')
b64ProtoData = b64ProtoData.replace('*', '=')
b64ProtoData = b64ProtoData.replace('-', '+')
finalbunary = base64.b64decode(b64ProtoData)
log = processor_pb2.ProcessorLogProto()
log.ParseFromString(finalbunary)
#print(log)
jsonObj = MessageToDict(log,preserving_proto_field_name=True)
jsonObj["totalProcessorBids"] = totalProcessorBids
#wjdata = json.dumps(jsonObj)
print(jsonObj)
return [jsonObj]
else:
pass
class ParseFile(beam.DoFn):
def process(self, element, *args, **kwargs):
import csv
for line in csv.reader([element], quotechar='"', delimiter='\t', quoting=csv.QUOTE_ALL, skipinitialspace=True):
#print (line)
return [line]
def run():
parser = argparse.ArgumentParser()
parser.add_argument("--input", dest="input", required=False)
parser.add_argument("--output", dest="output", required=False)
parser.add_argument("--bucket", dest="bucket", required=True)
parser.add_argument("--bfilename", dest="bfilename", required=True)
app_args, pipeline_args = parser.parse_known_args()
#pipeline_args.extend(['--runner=DirectRunner'])
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = True
bucket_input=app_args.bucket
bfilename=app_args.bfilename
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_input)
blob = bucket.blob(bfilename)
blob = blob.download_as_string()
blob = blob.decode('utf-8')
blob = StringIO(blob)
pqueue = []
names = csv.reader(blob)
for i,filename in enumerate(names):
if filename and filename[0]:
pqueue.append(filename[0])
with beam.Pipeline(options=pipeline_options) as p:
if(len(pqueue)>0):
input_list=app_args.input
output_list=app_args.output
events = ( p | "create PCol from list" >> beam.Create(pqueue)
| "read files" >> beam.io.textio.ReadAllFromText()
| "Transform" >> beam.ParDo(ParseFile())
| "Convert To JSON" >> beam.ParDo(ConvertToJson())
| "Write to BQ" >> beam.io.WriteToBigQuery(
table='TABLE',
dataset='DATASET',
project='PROJECT',
schema="dataevent:STRING",
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
insert_retry_strategy=RetryStrategy.RETRY_ON_TRANSIENT_ERROR,
custom_gcs_temp_location='gs://BUCKET/gcs-temp-to-bq/',
method='FILE_LOADS'))
##bigquery failed rows NOT WORKING so commented
#(events[beam.io.gcp.bigquery.BigQueryWriteFn.FAILED_ROWS] | "Bad lines" >> beam.io.textio.WriteToText("error_log.txt"))
##WRITING TO GCS
#printFileConetent | "Write TExt" >> beam.io.WriteToText(output_list+"file_",file_name_suffix=".json",num_shards=1, append_trailing_newlines = True)
if __name__ == '__main__':
logging.getLogger().setLevel(logging.INFO)
run()
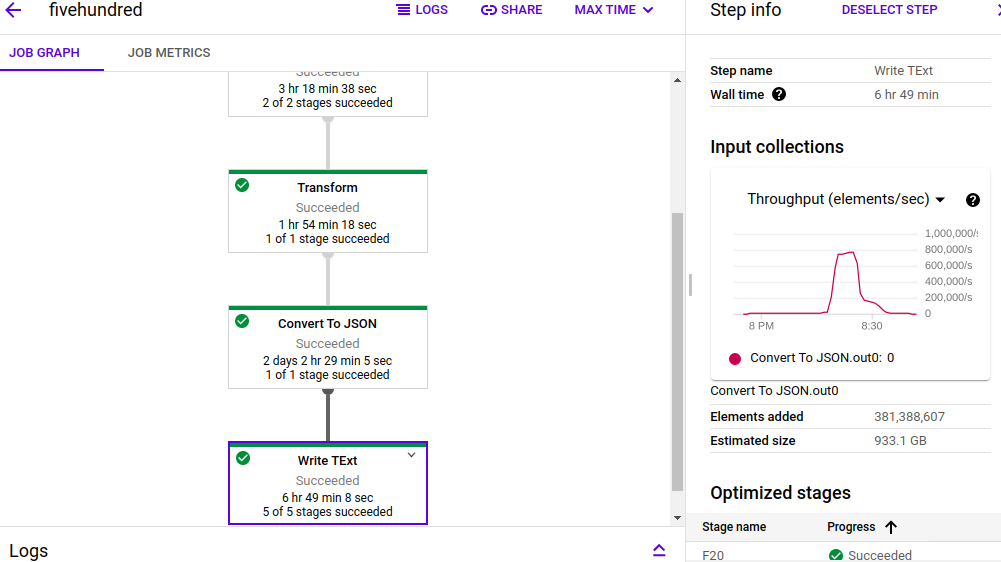
The job took around 49 mins
Things I tried: 1) For avro, generated schema that needs to be in JSON for proto file and tried below code to convert a dictionary to avro msg, but it is taking time as the size of the dictionary is more. schema_separated= is an avro JSON schema and it is working fine
with beam.Pipeline(options=pipeline_options) as p:
if(len(pqueue)>0):
input_list=app_args.input
output_list=app_args.output
p1 = p | "create PCol from list" >> beam.Create(pqueue)
readListofFiles=p1 | "read files" >> beam.io.textio.ReadAllFromText()
parsingProtoFile = readListofFiles | "Transform" >> beam.ParDo(ParseFile())
printFileConetent = parsingProtoFile | "Convert To JSON" >> beam.ParDo(ConvertToJson())
compressIdc=True
use_fastavro=True
printFileConetent | 'write_fastavro' >> WriteToAvro(
output_list+"file_",
# '/tmp/dataflow/{}/{}'.format(
# 'demo', 'output'),
# parse_schema(json.loads(SCHEMA_STRING)),
parse_schema(schema_separated),
use_fastavro=use_fastavro,
file_name_suffix='.avro',
codec=('deflate' if compressIdc else 'null'),
)
In the main code, I tried to insert JSON record as a string to bigquery table and so that I can use JSON functions in bigquery to extract the data and that also didn't go well and getting this below error.
message: 'Error while reading data, error message: JSON table encountered too many errors, giving up. Rows: 1; errors: 1. Please look into the errors[] collection for more details.' reason: 'invalid'> [while running 'Write to BQ/BigQueryBatchFileLoads/WaitForDestinationLoadJobs']
Tried to insert the above JSON dictionary to bigquery providing JSON schema to table and is working fine as well
Now the challenge is size after deserialising the proto to JSON dict is doubled and cost will be calculated in dataflow by how much data processed
I'm trying and reading a lot to make this work and if it works, then I can make it stable for production.
Sample JSON record.
{'timestamp': '1609286400', 'bidResponseId': '5febc300000115cd054b9fd6840a5af1', 'aggregatorId': '1', 'userId': '7567d74e-2e43-45f4-a42a-8224798bb0dd', 'uniqueResponseId': '', 'adserverId': '1002418', 'dataVersion': '1609285802', 'geoInfo': {'country': '101', 'region': '122', 'city': '11605', 'timezone': '420'}, 'clientInfo': {'os': '4', 'browser': '1', 'remoteIp': '36.70.64.0'}, 'adRequestInfo': {'requestingPage': 'com.opera.mini.native', 'siteId': '557243954', 'foldPosition': '2', 'adSlotId': '1', 'isTest': False, 'opType': 'TYPE_LEARNING', 'mediaType': 'BANNER'}, 'userSegments': [{'id': '2029660', 'weight': -1.0, 'recency': '1052208'}, {'id': '2034588', 'weight': -1.0, 'recency': '-18101'}, {'id': '2029658', 'weight': -1.0, 'recency': '744251'}, {'id': '2031067', 'weight': -1.0, 'recency': '1162398'}, {'id': '2029659', 'weight': -1.0, 'recency': '862833'}, {'id': '2033498', 'weight': -1.0, 'recency': '802749'}, {'id': '2016729', 'weight': -1.0, 'recency': '1620540'}, {'id': '2034584', 'weight': -1.0, 'recency': '111571'}, {'id': '2028182', 'weight': -1.0, 'recency': '744251'}, {'id': '2016726', 'weight': -1.0, 'recency': '1620540'}, {'id': '2028183', 'weight': -1.0, 'recency': '744251'}, {'id': '2028178', 'weight': -1.0, 'recency': '862833'}, {'id': '2016722', 'weight': -1.0, 'recency': '1675814'}, {'id': '2029587', 'weight': -1.0, 'recency': '38160'}, {'id': '2028177', 'weight': -1.0, 'recency': '862833'}, {'id': '2016719', 'weight': -1.0, 'recency': '1675814'}, {'id': '2027404', 'weight': -1.0, 'recency': '139031'}, {'id': '2028172', 'weight': -1.0, 'recency': '1052208'}, {'id': '2028173', 'weight': -1.0, 'recency': '1052208'}, {'id': '2034058', 'weight': -1.0, 'recency': '1191459'}, {'id': '2016712', 'weight': -1.0, 'recency': '1809526'}, {'id': '2030025', 'weight': -1.0, 'recency': '1162401'}, {'id': '2015235', 'weight': -1.0, 'recency': '139031'}, {'id': '2027712', 'weight': -1.0, 'recency': '139031'}, {'id': '2032447', 'weight': -1.0, 'recency': '7313670'}, {'id': '2034815', 'weight': -1.0, 'recency': '586825'}, {'id': '2034811', 'weight': -1.0, 'recency': '659366'}, {'id': '2030004', 'weight': -1.0, 'recency': '139031'}, {'id': '2027316', 'weight': -1.0, 'recency': '1620540'}, {'id': '2033141', 'weight': -1.0, 'recency': '7313670'}, {'id': '2034736', 'weight': -1.0, 'recency': '308252'}, {'id': '2029804', 'weight': -1.0, 'recency': '307938'}, {'id': '2030188', 'weight': -1.0, 'recency': '3591519'}, {'id': '2033449', 'weight': -1.0, 'recency': '1620540'}, {'id': '2029672', 'weight': -1.0, 'recency': '1441083'}, {'id': '2029664', 'weight': -1.0, 'recency': '636630'}], 'perfInfo': {'timeTotal': '2171', 'timeBidInitialize': '0', 'timeProcessDatastore': '0', 'timeGetCandidates': '0', 'timeAdFiltering': '0', 'timeEcpmComputation': '0', 'timeBidComputation': '0', 'timeAdSelection': '0', 'timeBidSubmit': '0', 'timeTFQuery': '0', 'timeVWQuery': '8'}, 'learningPercent': 0.10000000149011612, 'pageLanguageId': '0', 'sspUserId': 'CAESECHFlNeuUm16IYThguoQ8ck_1', 'minEcpm': 0.12999999523162842, 'adSpotId': '1', 'creativeSizes': [{'width': '7', 'height': '7'}], 'pageTypeId': '0', 'numSlots': '0', 'eligibleLIs': [{'type': 'TYPE_OPTIMIZED', 'liIds': [{'id': 44005, 'reason': '12', 'creative_id': 121574, 'bid_amount': 8.403361132251052e-08}, {'id': 46938, 'reason': '12', 'creative_id': 124916, 'bid_amount': 8.403361132251052e-06}, {'id': 54450, 'reason': '12', 'creative_id': 124916, 'bid_amount': 2.0117618771650174e-05}, {'id': 54450, 'reason': '12', 'creative_id': 135726, 'bid_amount': 2.4237295484638312e-05}]}, {'type': 'TYPE_LEARNING'}], 'bidType': 4, 'isSecureRequest': True, 'sourceType': 3, 'deviceBrand': 82, 'deviceModel': 1, 'sellerNetworkId': 12814, 'interstitialRequest': False, 'nativeAdRequest': True, 'native': {'mainImg': [{'w': 0, 'h': 0, 'wmin': 1200, 'hmin': 627}, {'w': 0, 'h': 0, 'wmin': 1200, 'hmin': 627}, {'w': 0, 'h': 0, 'wmin': 1200, 'hmin': 627}, {'w': 0, 'h': 0, 'wmin': 1200, 'hmin': 627}], 'iconImg': [{'w': 0, 'h': 0, 'wmin': 0, 'hmin': 0}, {'w': 0, 'h': 0, 'wmin': 100, 'hmin': 100}, {'w': 0, 'h': 0, 'wmin': 0, 'hmin': 0}, {'w': 0, 'h': 0, 'wmin': 100, 'hmin': 100}], 'logoImg': [{'w': 0, 'h': 0, 'wmin': 100, 'hmin': 100}, {'w': 0, 'h': 0, 'wmin': 0, 'hmin': 0}, {'w': 0, 'h': 0, 'wmin': 100, 'hmin': 100}, {'w': 0, 'h': 0, 'wmin': 0, 'hmin': 0}]}, 'throttleWeight': 1, 'isSegmentReceived': False, 'viewability': 46, 'bannerAdRequest': False, 'videoAdRequest': False, 'mraidAdRequest': True, 'jsonModelCallCount': 0, 'totalProcessorBids': 1}
Can someone help me here?
PFA screenshots for reference as well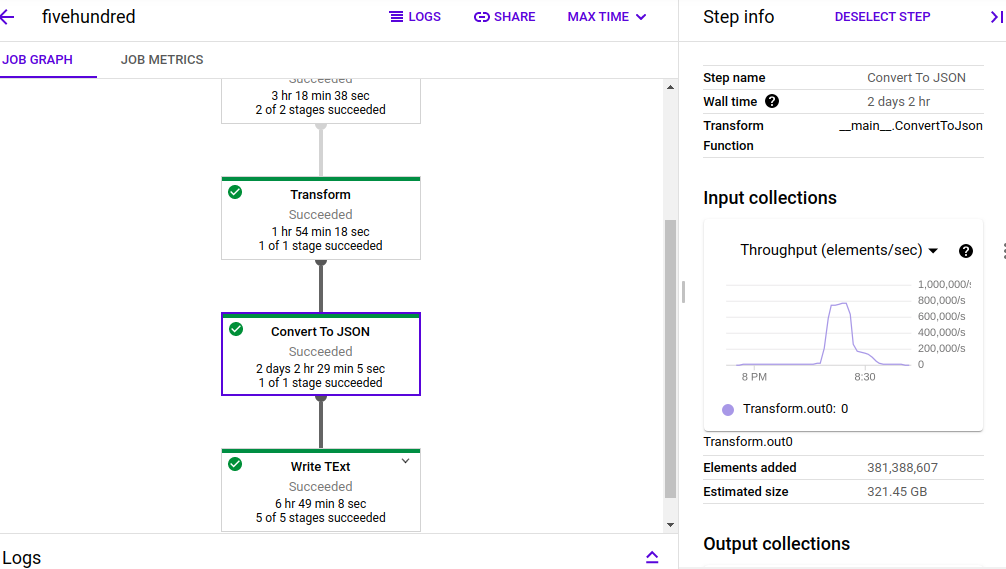
Please look into the errors[] collection for more detail. if you go to the Bigquery page in the GCP console and look at project jobs, you will see the error details. – Conallc2machine family. It costs more per hour but is more cost-effective for cpu-heavy tasks. – ConallConvertToJson.processyou have three calls toreplace. That's inefficient especially ifb64ProtoDatais large as it needs to do three passes over the data. It's more efficient to usetranslatewith a translation table:table = b64ProtoData.maketrans({'_': '/', '*': '=', '-': '+'}); b64ProtoData = b64ProtoData.translate(table). – Commentary