There are different ways to log messages, in order of fatality:
FATALERRORWARNINFODEBUGTRACE
How do I decide when to use which?
What's a good heuristic to use?
There are different ways to log messages, in order of fatality:
FATAL
ERROR
WARN
INFO
DEBUG
TRACE
How do I decide when to use which?
What's a good heuristic to use?
I generally subscribe to the following convention:
Debug - Information that is diagnostically helpful to people more than just developers (IT, sysadmins, etc.).. Logger.Debug is only for developers to track down very nasty issues in production e.g. If you want to print the value of a variable at any given point inside a for loop against a condition –
Nocturn Would you want the message to get a system administrator out of bed in the middle of the night?
FATAL is when the sysadmin wakes up, decides he's not paid enough for this, and goes back to sleep. –
Harner It's an old topic, but still relevant. This week, I wrote a small article about it, for my colleagues. For that purpose, I also created this cheat sheet, because I couldn't find any online.
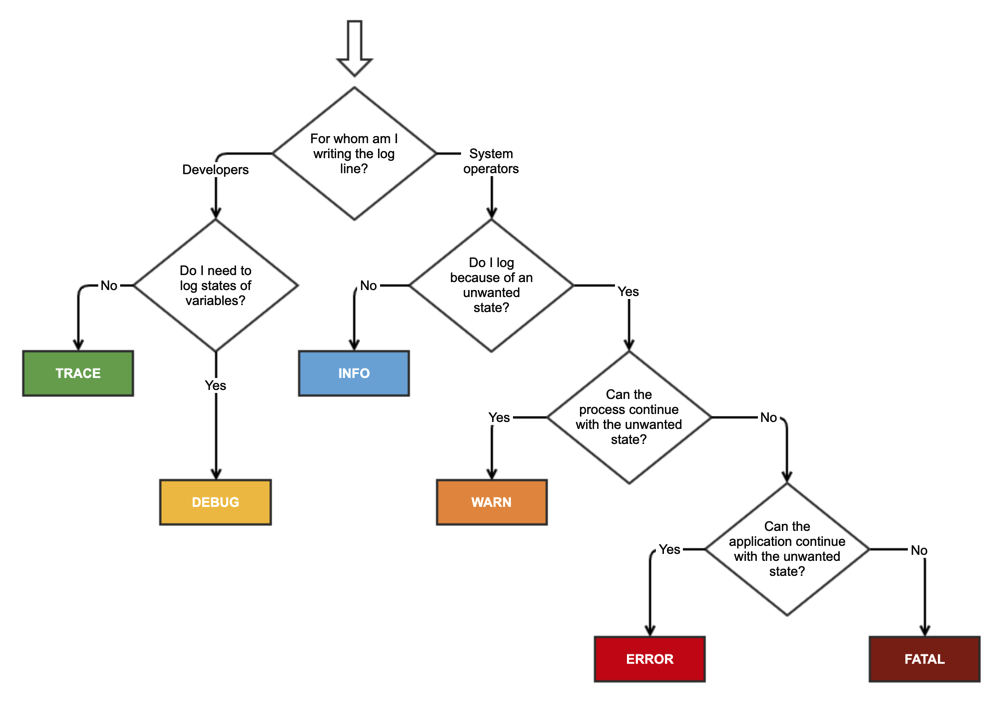
I find it more helpful to think about severities from the perspective of viewing the log file.
Fatal/Critical: Overall application or system failure that should be investigated immediately. Yes, wake up the SysAdmin. Since we prefer our SysAdmins alert and well-rested, this severity should be used very infrequently. If it's happening daily and that's not a BFD, it has lost its meaning. Typically, a Fatal error only occurs once in the process lifetime, so if the log file is tied to the process, this is typically the last message in the log.
Error: Definitely a problem that should be investigated. SysAdmin should be notified automatically, but doesn't need to be dragged out of bed. By filtering a log to look at errors and above you get an overview of error frequency and can quickly identify the initiating failure that might have resulted in a cascade of additional errors. Tracking error rates as versus application usage can yield useful quality metrics such as MTBF which can be used to assess overall quality. For example, this metric might help inform decisions about whether or not another beta testing cycle is needed before a release.
Warning: This MIGHT be problem, or might not. For example, expected transient environmental conditions such as short loss of network or database connectivity should be logged as Warnings, not Errors. Viewing a log filtered to show only warnings and errors may give quick insight into early hints at the root cause of a subsequent error. Warnings should be used sparingly so that they don't become meaningless. For example, loss of network access should be a warning or even an error in a server application, but might be just an Info in a desktop app designed for occasionally disconnected laptop users.
Info: This is important information that should be logged under normal conditions such as successful initialization, services starting and stopping or successful completion of significant transactions. Viewing a log showing Info and above should give a quick overview of major state changes in the process providing top-level context for understanding any warnings or errors that also occur. Don't have too many Info messages. We typically have < 5% Info messages relative to Trace.
Trace: Trace is by far the most commonly used severity and should provide context to understand the steps leading up to errors and warnings. Having the right density of Trace messages makes software much more maintainable but requires some diligence because the value of individual Trace statements may change over time as programs evolve. The best way to achieve this is by getting the dev team in the habit of regularly reviewing logs as a standard part of troubleshooting customer reported issues. Encourage the team to prune out Trace messages that no longer provide useful context and to add messages where needed to understand the context of subsequent messages. For example, it is often helpful to log user input such as changing displays or tabs.
Debug: We consider Debug < Trace. The distinction being that Debug messages are compiled out of Release builds. That said, we discourage use of Debug messages. Allowing Debug messages tends to lead to more and more Debug messages being added and none ever removed. In time, this makes log files almost useless because it's too hard to filter signal from noise. That causes devs to not use the logs which continues the death spiral. In contrast, constantly pruning Trace messages encourages devs to use them which results in a virtuous spiral. Also, this eliminates the possibility of bugs introduced because of needed side-effects in debug code that isn't included in the release build. Yeah, I know that shouldn't happen in good code, but better safe than sorry.
Here's a list of what "the loggers" have.
FATAL:
[v1.2: ..] very severe error events that will presumably lead the application to abort.
[v2.0: ..] severe error that will prevent the application from continuing.
ERROR:
[v1.2: ..] error events that might still allow the application to continue running.
[v2.0: ..] error in the application, possibly recoverable.
WARN:
[v1.2: ..] potentially harmful situations.
[v2.0: ..] event that might possible [sic] lead to an error.
INFO:
[v1.2: ..] informational messages that highlight the progress of the application at coarse-grained level.
[v2.0: ..] event for informational purposes.
DEBUG:
[v1.2: ..] fine-grained informational events that are most useful to debug an application.
[v2.0: ..] general debugging event.
TRACE:
[v1.2: ..] finer-grained informational events than the
DEBUG.[v2.0: ..] fine-grained debug message, typically capturing the flow through the application.
Apache Httpd (as usual) likes to go for the overkill: §
emerg:
Emergencies – system is unusable.
alert:
Action must be taken immediately [but system is still usable].
crit:
Critical Conditions [but action need not be taken immediately].
- "socket: Failed to get a socket, exiting child"
error:
Error conditions [but not critical].
- "Premature end of script headers"
warn:
Warning conditions. [close to error, but not error]
notice:
Normal but significant [notable] condition.
- "httpd: caught
SIGBUS, attempting to dump core in ..."
info:
Informational [and unnotable].
- ["Server has been running for x hours."]
debug:
Debug-level messages [, i.e. messages logged for the sake of de-bugging)].
- "Opening config file ..."
trace1 → trace6:
Trace messages [, i.e. messages logged for the sake of tracing].
- "proxy: FTP: control connection complete"
- "proxy: CONNECT: sending the CONNECT request to the remote proxy"
- "openssl: Handshake: start"
- "read from buffered SSL brigade, mode 0, 17 bytes"
- "map lookup FAILED:
map=rewritemapkey=keyname"- "cache lookup FAILED, forcing new map lookup"
trace7 → trace8:
Trace messages, dumping large amounts of data
- "
| 0000: 02 23 44 30 13 40 ac 34 df 3d bf 9a 19 49 39 15 |"- "
| 0000: 02 23 44 30 13 40 ac 34 df 3d bf 9a 19 49 39 15 |"
Apache commons-logging: §
fatal:
Severe errors that cause premature termination. Expect these to be immediately visible on a status console.
error:
Other runtime errors or unexpected conditions. Expect these to be immediately visible on a status console.
warn:
Use of deprecated APIs, poor use of API, 'almost' errors, other runtime situations that are undesirable or unexpected, but not necessarily "wrong". Expect these to be immediately visible on a status console.
info:
Interesting runtime events (startup/shutdown). Expect these to be immediately visible on a console, so be conservative and keep to a minimum.
debug:
detailed information on the flow through the system. Expect these to be written to logs only.
trace:
more detailed information. Expect these to be written to logs only.
Apache commons-logging "best practices" for enterprise usage makes a distinction between debug and info based on what kind of boundaries they cross.
Boundaries include:
External Boundaries - Expected Exceptions.
External Boundaries - Unexpected Exceptions.
Internal Boundaries.
Significant Internal Boundaries.
(See commons-logging guide for more info on this.)
I'd recommend adopting Syslog severity levels: DEBUG, INFO, NOTICE, WARNING, ERROR, CRITICAL, ALERT, EMERGENCY.
See http://en.wikipedia.org/wiki/Syslog#Severity_levels
They should provide enough fine-grained severity levels for most use-cases and are recognized by existing log-parsers. While you have of course the freedom to only implement a subset, e.g. DEBUG, ERROR, EMERGENCY depending on your app's requirements.
Let's standardize on something that's been around for ages instead of coming up with our own standard for every different app we make. Once you start aggregating logs and are trying to detect patterns across different ones it really helps.
DEBUG, INFO, WARNING and ERROR. Developers should see all levels. SysAdmins up to INFO, and End Users can see warnings and errors but only if there is a framework to alert them about it. –
Olag DEBUG and TRACE for developers to control the granularity. And ERROR expanded to other levels like CRITICAL, ALERT, EMERGENCY to distinguish the severity of errors and determine the action based on severity. –
Olag If you can recover from the problem then it's a warning. If it prevents continuing execution then it's an error.
Warnings you can recover from. Errors you can't. That's my heuristic, others may have other ideas.
For example, let's say you enter/import the name "Angela Müller" into your application (note the umlaut over the u). Your code/database may be English only (though it probably shouldn't be in this day and age) and could therefore warn that all "unusual" characters had been converted to regular English characters.
Contrast that with trying to write that information to the database and getting back a network down message for 60 seconds straight. That's more of an error than a warning.
From RFC 5424, the Syslog Protocol (IETF) - Page 10:
Each message Priority also has a decimal Severity level indicator. These are described in the following table along with their numerical values. Severity values MUST be in the range of 0 to 7 inclusive.
Numerical Severity Code 0 Emergency: system is unusable 1 Alert: action must be taken immediately 2 Critical: critical conditions 3 Error: error conditions 4 Warning: warning conditions 5 Notice: normal but significant condition 6 Informational: informational messages 7 Debug: debug-level messages Table 2. Syslog Message Severities
Taco Jan Osinga's answer is very good, and very practical, to boot.
I am in partial agreement with him, though with some variations.
On Python, there are only 5 "named" logging levels, so this is how I use them:
DEBUG -- information important for troubleshooting, and usually suppressed in normal day-to-day operationINFO -- day-to-day operation as "proof" that program is performing its function as designedWARN -- out-of-nominal but recoverable situation, *or* coming upon something that may result in future problemsERROR -- something happened that necessitates the program to do recovery, but recovery is successful. Program is likely not in the originally expected state, though, so user of the program will need to adaptCRITICAL -- something happened that cannot be recovered from, and program likely need to terminate lest everyone will be living in a state of sinIt's interesting how Microsoft defines the different LogLevel values in their new "quasi-standard" Microsoft.Extensions.Logging (emphasis mine):
Critical
Logs that describe an unrecoverable application or system crash, or a catastrophic failure that requires immediate attention.
Error
Logs that highlight when the current flow of execution is stopped due to a failure. These should indicate a failure in the current activity, not an application-wide failure.
Warning
Logs that highlight an abnormal or unexpected event in the application flow, but do not otherwise cause the application execution to stop.
Information
Logs that track the general flow of the application. These logs should have long-term value.
Debug
Logs that are used for interactive investigation during development. These logs should primarily contain information useful for debugging and have no long-term value.
Trace
Logs that contain the most detailed messages. These messages may contain sensitive application data. These messages are disabled by default and should never be enabled in a production environment.
From https://sematext.com/blog/slf4j-tutorial/:
- TRACE – log events with this level are the most fine-grained and are usually not needed unless you need to have the full visibility of what is happening in your application and inside the third-party libraries that you use. You can expect the TRACE logging level to be very verbose.
- DEBUG – less granular compared to the TRACE level, but still more than you will need in everyday use. The DEBUG log level should be used for information that may be needed for deeper diagnostics and troubleshooting.
- INFO – the standard log level indicating that something happened, application processed a request, etc. The information logged using the INFO log level should be purely informative and not looking into them on a regular basis shouldn’t result in missing any important information.
- WARN – the log level that indicates that something unexpected happened in the application. For example a problem, or a situation that might disturb one of the processes, but the whole application is still working.
- ERROR – the log level that should be used when the application hits an issue preventing one or more functionalities from properly functioning. The ERROR log level can be used when one of the payment systems is not available, but there is still the option to check out the basket in the e-commerce application or when your social media logging option is not working for some reason. You can also see the ERROR log level associated with exceptions.
As others have said, errors are problems; warnings are potential problems.
In development, I frequently use warnings where I might put the equivalent of an assertion failure but the application can continue working; this enables me to find out if that case ever actually happens, or if it's my imagination.
But yes, it gets down to the recoverabilty and actuality aspects. If you can recover, it's probably a warning; if it causes something to actually fail, it's an error.
I totally agree with the others, and think that GrayWizardx said it best.
All that I can add is that these levels generally correspond to their dictionary definitions, so it can't be that hard. If in doubt, treat it like a puzzle. For your particular project, think of everything that you might want to log.
Now, can you figure out what might be fatal? You know what fatal means, don't you? So, which items on your list are fatal.
Ok, that's fatal dealt with, now let's look at errors ... rinse and repeat.
Below Fatal, or maybe Error, I would suggest that more information is always better than less, so err "upwards". Not sure if it's Info or Warning? Then make it a warning.
I do think that Fatal and error ought to be clear to all of us. The others might be fuzzier, but it is arguably less vital to get them right.
Here are some examples:
Fatal - can't allocate memory, database, etc - can't continue.
Error - no reply to message, transaction aborted, can't save file, etc.
Warning - resource allocation reaches X% (say 80%) - that is a sign that you might want to re-dimension your.
Info - user logged in/out, new transaction, file crated, new d/b field, or field deleted.
Debug - dump of internal data structure, Anything Trace level with file name & line number.
Trace - action succeeded/failed, d/b updated.
I think that SYSLOG levels NOTICE and ALERT/EMERGENCY are largely superfluous for application-level logging - while CRITICAL/ALERT/EMERGENCY may be useful alert levels for an operator that may trigger different actions and notifications, to an application admin it's all the same as FATAL. And I just cannot sufficiently distinguish between being given a notice or some information. If the information is not noteworthy, it's not really information :)
I like Jay Cincotta's interpretation best - tracing your code's execution is something very useful in tech support, and putting trace statements into the code liberally should be encouraged - especially in combination with a dynamic filtering mechanism for logging the trace messages from specific application components. However DEBUG level to me indicates that we're still in the process of figuring out what's going on - I see DEBUG level output as a development-only option, not as something that should ever show up in a production log.
There is however a logging level that I like to see in my error logs when wearing the hat of a sysadmin as much as that of tech support, or even developer: OPER, for OPERATIONAL messages. This I use for logging a timestamp, the type of operation invoked, the arguments supplied, possibly a (unique) task identifier, and task completion. It's used when e.g. a standalone task is fired off, something that is a true invocation from within the larger long-running app. It's the sort of thing I want always logged, no matter whether anything goes wrong or not, so I consider the level of OPER to be higher than FATAL, so you can only turn it off by going to totally silent mode. And it's much more than mere INFO log data - a log level often abused for spamming logs with minor operational messages of no historical value whatsoever.
As the case dictates this information may be directed to a separate invocation log, or may be obtained by filtering it out of a large log recording more information. But it's always needed, as historical info, to know what was being done - without descending to the level of AUDIT, another totally separate log level that has nothing to do with malfunctions or system operation, doesn't really fit within the above levels (as it needs its own control switch, not a severity classification) and which definitely needs its own separate log file.
G'day,
As a corollary to this question, communicate your interpretations of the log levels and make sure that all people on a project are aligned in their interpretation of the levels.
It's painful to see a vast variety of log messages where the severities and the selected log levels are inconsistent.
Provide examples if possible of the different logging levels. And be consistent in the info to be logged in a message.
HTH
My two cents about FATAL and TRACE error log levels.
ERROR is when some FAULT (exception) occur.
FATAL is actually DOUBLE FAULT: when exception occur while handling exception.
It's easy to understand for web service.
INFO WARNERRORFATALTRACE is when we can trace function entry/exit. This is not about logging, because this message can be generated by some debugger and your code has not call to log at all. So messages that are not from your application are marked like TRACE level. For example your run your application by with strace
So generally in your program you do DEBUG, INFO and WARN logging. And only if you are writing some web service/framework you will use FATAL. And when you are debugging application you will get TRACE logging from this type of software.
An error is something that is wrong, plain wrong, no way around it, it needs to be fixed.
A warning is a sign of a pattern that might be wrong, but then also might not be.
Having said that, I cannot come up with a good example of a warning that isn't also an error. What I mean by that is that if you go to the trouble of logging a warning, you might as well fix the underlying issue.
However, things like "sql execution takes too long" might be a warning, while "sql execution deadlocks" is an error, so perhaps there's some cases after all.
varchar than it is defined for, it warns you that the value was truncated, but still inserts it. But one person's warning may be another's error: In my case, this is an error; it means I made an error in my validation code by defining a length incongruous with the database. And I wouldn't be terribly surprised if another DB engine considered this an error, and I'd have no real right to be indignant, after all, it is erroneous. –
Stabler I've always considered warning the first log level that for sure means there is a problem (for example, perhaps a config file isn't where it should be and we're going to have to run with default settings). An error implies, to me, something that means the main goal of the software is now impossible and we're going to try to shut down cleanly.
Btw, I am a great fan of capturing everything and filtering the information later.
What would happen if you were capturing at Warning level and want some Debug info related to the warning, but were unable to recreate the warning?
Capture everything and filter later!
This holds true even for embedded software unless you find that your processor can't keep up, in which case you might want to re-design your tracing to make it more efficient, or the tracing is interfering with timing (you might consider debugging on a more powerful processor, but that opens up a whole nother can of worms).
Capture everything and filter later!!
(btw, capture everything is also good because it lets you develop tools to do more than just show debug trace (I draw Message Sequence Charts from mine, and histograms of memory usage. It also gives you a basis for comparison if something goes wrong in future (keep all logs, whether pass or fail, and be sure to include build number in the log file)).
I've built systems before that use the following:
In the systems I've built admins were under instruction to react to ERRORs. On the other hand we would watch for WARNINGS and determine for each case whether any system changes, reconfigurations etc. were required.
I suggest using only three levels
© 2022 - 2024 — McMap. All rights reserved.
noticein this collection someone will not ... – Setnoticemight well be missing because some popular logging services like log4j do not use it. – Sarcocarpnoticefalls betweenwarningandinfo. datatracker.ietf.org/doc/html/rfc5424#page-11 – Sturdy