I have a data frame and some columns have NA values.
How do I replace these NA values with zeroes?
I have a data frame and some columns have NA values.
How do I replace these NA values with zeroes?
See my comment in @gsk3 answer. A simple example:
> m <- matrix(sample(c(NA, 1:10), 100, replace = TRUE), 10)
> d <- as.data.frame(m)
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
1 4 3 NA 3 7 6 6 10 6 5
2 9 8 9 5 10 NA 2 1 7 2
3 1 1 6 3 6 NA 1 4 1 6
4 NA 4 NA 7 10 2 NA 4 1 8
5 1 2 4 NA 2 6 2 6 7 4
6 NA 3 NA NA 10 2 1 10 8 4
7 4 4 9 10 9 8 9 4 10 NA
8 5 8 3 2 1 4 5 9 4 7
9 3 9 10 1 9 9 10 5 3 3
10 4 2 2 5 NA 9 7 2 5 5
> d[is.na(d)] <- 0
> d
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
1 4 3 0 3 7 6 6 10 6 5
2 9 8 9 5 10 0 2 1 7 2
3 1 1 6 3 6 0 1 4 1 6
4 0 4 0 7 10 2 0 4 1 8
5 1 2 4 0 2 6 2 6 7 4
6 0 3 0 0 10 2 1 10 8 4
7 4 4 9 10 9 8 9 4 10 0
8 5 8 3 2 1 4 5 9 4 7
9 3 9 10 1 9 9 10 5 3 3
10 4 2 2 5 0 9 7 2 5 5
There's no need to apply apply. =)
EDIT
You should also take a look at norm package. It has a lot of nice features for missing data analysis. =)
df[19:28][is.na(df[19:28])] <- 0 –
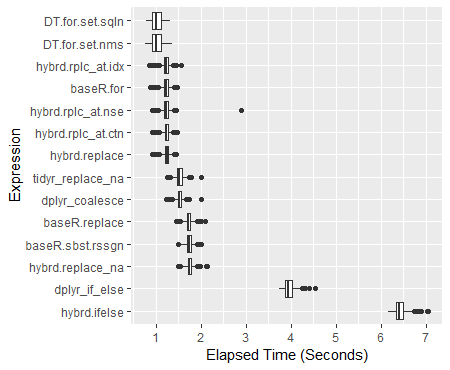
Lautrec The dplyr hybridized options are now around 30% faster than the Base R subset reassigns. On a 100M datapoint dataframe mutate_all(~replace(., is.na(.), 0)) runs a half a second faster than the base R d[is.na(d)] <- 0 option. What one wants to avoid specifically is using an ifelse() or an if_else(). (The complete 600 trial analysis ran to over 4.5 hours mostly due to including these approaches.) Please see benchmark analyses below for the complete results.
If you are struggling with massive dataframes, data.table is the fastest option of all: 40% faster than the standard Base R approach. It also modifies the data in place, effectively allowing you to work with nearly twice as much of the data at once.
Locationally:
mutate_at(c(5:10), ~replace(., is.na(.), 0))mutate_at(vars(var5:var10), ~replace(., is.na(.), 0))mutate_at(vars(contains("1")), ~replace(., is.na(.), 0))contains(), try ends_with(),starts_with()mutate_at(vars(matches("\\d{2}")), ~replace(., is.na(.), 0))Conditionally:
(change just single type and leave other types alone.)
mutate_if(is.integer, ~replace(., is.na(.), 0))mutate_if(is.numeric, ~replace(., is.na(.), 0))mutate_if(is.character, ~replace(., is.na(.), 0))##The Complete Analysis -
Updated for dplyr 0.8.0: functions use purrr format ~ symbols: replacing deprecated funs() arguments.
# Base R:
baseR.sbst.rssgn <- function(x) { x[is.na(x)] <- 0; x }
baseR.replace <- function(x) { replace(x, is.na(x), 0) }
baseR.for <- function(x) { for(j in 1:ncol(x))
x[[j]][is.na(x[[j]])] = 0 }
# tidyverse
## dplyr
dplyr_if_else <- function(x) { mutate_all(x, ~if_else(is.na(.), 0, .)) }
dplyr_coalesce <- function(x) { mutate_all(x, ~coalesce(., 0)) }
## tidyr
tidyr_replace_na <- function(x) { replace_na(x, as.list(setNames(rep(0, 10), as.list(c(paste0("var", 1:10)))))) }
## hybrid
hybrd.ifelse <- function(x) { mutate_all(x, ~ifelse(is.na(.), 0, .)) }
hybrd.replace_na <- function(x) { mutate_all(x, ~replace_na(., 0)) }
hybrd.replace <- function(x) { mutate_all(x, ~replace(., is.na(.), 0)) }
hybrd.rplc_at.idx<- function(x) { mutate_at(x, c(1:10), ~replace(., is.na(.), 0)) }
hybrd.rplc_at.nse<- function(x) { mutate_at(x, vars(var1:var10), ~replace(., is.na(.), 0)) }
hybrd.rplc_at.stw<- function(x) { mutate_at(x, vars(starts_with("var")), ~replace(., is.na(.), 0)) }
hybrd.rplc_at.ctn<- function(x) { mutate_at(x, vars(contains("var")), ~replace(., is.na(.), 0)) }
hybrd.rplc_at.mtc<- function(x) { mutate_at(x, vars(matches("\\d+")), ~replace(., is.na(.), 0)) }
hybrd.rplc_if <- function(x) { mutate_if(x, is.numeric, ~replace(., is.na(.), 0)) }
# data.table
library(data.table)
DT.for.set.nms <- function(x) { for (j in names(x))
set(x,which(is.na(x[[j]])),j,0) }
DT.for.set.sqln <- function(x) { for (j in seq_len(ncol(x)))
set(x,which(is.na(x[[j]])),j,0) }
DT.nafill <- function(x) { nafill(df, fill=0)}
DT.setnafill <- function(x) { setnafill(df, fill=0)}
library(microbenchmark)
# 20% NA filled dataframe of 10 Million rows and 10 columns
set.seed(42) # to recreate the exact dataframe
dfN <- as.data.frame(matrix(sample(c(NA, as.numeric(1:4)), 1e7*10, replace = TRUE),
dimnames = list(NULL, paste0("var", 1:10)),
ncol = 10))
# Running 600 trials with each replacement method
# (the functions are excecuted locally - so that the original dataframe remains unmodified in all cases)
perf_results <- microbenchmark(
hybrd.ifelse = hybrd.ifelse(copy(dfN)),
dplyr_if_else = dplyr_if_else(copy(dfN)),
hybrd.replace_na = hybrd.replace_na(copy(dfN)),
baseR.sbst.rssgn = baseR.sbst.rssgn(copy(dfN)),
baseR.replace = baseR.replace(copy(dfN)),
dplyr_coalesce = dplyr_coalesce(copy(dfN)),
tidyr_replace_na = tidyr_replace_na(copy(dfN)),
hybrd.replace = hybrd.replace(copy(dfN)),
hybrd.rplc_at.ctn= hybrd.rplc_at.ctn(copy(dfN)),
hybrd.rplc_at.nse= hybrd.rplc_at.nse(copy(dfN)),
baseR.for = baseR.for(copy(dfN)),
hybrd.rplc_at.idx= hybrd.rplc_at.idx(copy(dfN)),
DT.for.set.nms = DT.for.set.nms(copy(dfN)),
DT.for.set.sqln = DT.for.set.sqln(copy(dfN)),
times = 600L
)
> print(perf_results) Unit: milliseconds expr min lq mean median uq max neval hybrd.ifelse 6171.0439 6339.7046 6425.221 6407.397 6496.992 7052.851 600 dplyr_if_else 3737.4954 3877.0983 3953.857 3946.024 4023.301 4539.428 600 hybrd.replace_na 1497.8653 1706.1119 1748.464 1745.282 1789.804 2127.166 600 baseR.sbst.rssgn 1480.5098 1686.1581 1730.006 1728.477 1772.951 2010.215 600 baseR.replace 1457.4016 1681.5583 1725.481 1722.069 1766.916 2089.627 600 dplyr_coalesce 1227.6150 1483.3520 1524.245 1519.454 1561.488 1996.859 600 tidyr_replace_na 1248.3292 1473.1707 1521.889 1520.108 1570.382 1995.768 600 hybrd.replace 913.1865 1197.3133 1233.336 1238.747 1276.141 1438.646 600 hybrd.rplc_at.ctn 916.9339 1192.9885 1224.733 1227.628 1268.644 1466.085 600 hybrd.rplc_at.nse 919.0270 1191.0541 1228.749 1228.635 1275.103 2882.040 600 baseR.for 869.3169 1180.8311 1216.958 1224.407 1264.737 1459.726 600 hybrd.rplc_at.idx 839.8915 1189.7465 1223.326 1228.329 1266.375 1565.794 600 DT.for.set.nms 761.6086 915.8166 1015.457 1001.772 1106.315 1363.044 600 DT.for.set.sqln 787.3535 918.8733 1017.812 1002.042 1122.474 1321.860 600
ggplot(perf_results, aes(x=expr, y=time/10^9)) +
geom_boxplot() +
xlab('Expression') +
ylab('Elapsed Time (Seconds)') +
scale_y_continuous(breaks = seq(0,7,1)) +
coord_flip()
qplot(y=time/10^9, data=perf_results, colour=expr) +
labs(y = "log10 Scaled Elapsed Time per Trial (secs)", x = "Trial Number") +
coord_cartesian(ylim = c(0.75, 7.5)) +
scale_y_log10(breaks=c(0.75, 0.875, 1, 1.25, 1.5, 1.75, seq(2, 7.5)))
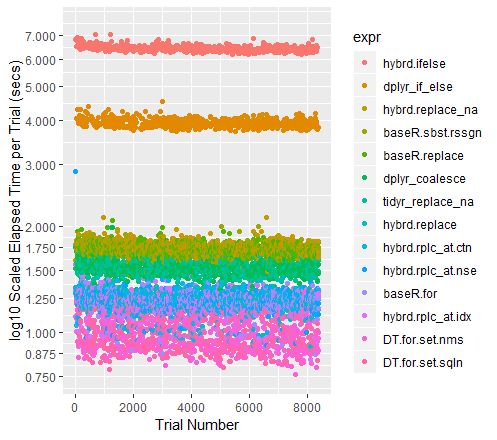
When the datasets get larger, Tidyr''s replace_na had historically pulled out in front. With the current collection of 100M data points to run through, it performs almost exactly as well as a Base R For Loop. I am curious to see what happens for different sized dataframes.
Additional examples for the mutate and summarize _at and _all function variants can be found here: https://rdrr.io/cran/dplyr/man/summarise_all.html
Additionally, I found helpful demonstrations and collections of examples here: https://blog.exploratory.io/dplyr-0-5-is-awesome-heres-why-be095fd4eb8a
With special thanks to:
local(), and (with Frank's patient help, too) the role that silent coercion plays in speeding up many of these approaches.coalesce() function in and update the analysis.data.table functions well enough to finally include them in the lineup.is.numeric() really tests.(Of course, please reach over and give them upvotes, too if you find those approaches useful.)
Note on my use of Numerics: If you do have a pure integer dataset, all of your functions will run faster. Please see alexiz_laz's work for more information. IRL, I can't recall encountering a data set containing more than 10-15% integers, so I am running these tests on fully numeric dataframes.
Hardware Used 3.9 GHz CPU with 24 GB RAM
df1[j][is.na(df1[j])] = 0 is wrong, should be df1[[j]][is.na(df1[[j]])] = 0 –
Scapular forLp_Sbst doesn't seem like a way anyone should consider approaching it vs forLp_smplfSbst –
Scapular z <- c(1,2,3); z[2] <- 0L; str(z) is still num. –
Scapular local() when benchmarking? –
Winsor coalesce() option in and rerun all the times. Thank you for the nudge to update. –
Scrouge data.table works and this would be a good start.) –
Scrouge data.table was skewing the whole analysis. I had firewalled the original dataframe by wrapping all actions in function()s or in local() or both so that every action would be performed on the same unmodified dataframe. Unfortunately, in this case, data.table set and := modify in place. I will have to find a way to rebuild the 50M line dataframe each time if I want to test those functions with the others. That will take a bit more processing (& coding) time... –
Scrouge local use copy before modifying DT in place –
Mirk nafill are officially released. –
Scrouge tilde is doing in this script... it works fine with it but removing it causes and error... why is that? –
Jaguar is.numeric does not necessarily mean double. Manual: «is.numeric is a more general test of an object being interpretable as numbers». –
Italianism mutate_at and mutate_all: function(x) { mutate(across(x, ~replace_na(., 0))) } –
Dynast across also supports inline anonymous functions which might provide a slight performance boost over ~ which has to be converted to a function: mutate(across(everything(), \(x) replace_na(x, 0))). –
Narcotic For a single vector:
x <- c(1,2,NA,4,5)
x[is.na(x)] <- 0
For a data.frame, make a function out of the above, then apply it to the columns.
Please provide a reproducible example next time as detailed here:
is.na is generic function, and has methods for objects of data.frame class. so this one will also work on data.frames! –
Bramante methods(is.na) for the first time, I was like whaaa?!?. I love when stuff like that happen! =) –
Bramante dplyr example:
library(dplyr)
df1 <- df1 %>%
mutate(myCol1 = if_else(is.na(myCol1), 0, myCol1))
Note: This works per selected column, if we need to do this for all column, see @reidjax's answer using mutate_each.
It is also possible to use tidyr::replace_na.
library(tidyr)
df <- df %>% mutate_all(funs(replace_na(.,0)))
Edit (dplyr > 1.0.0):
df %>% mutate(across(everything(), .fns = ~replace_na(.,0)))
mutate_* verbs are now superseded by across() –
Snocat replace(is.na(.), 0) function inside mutate().Why not feed it directly to the pipe? –
Tancred mutate enables to create or replace variables. –
Codycoe dplyr 1.1.0 this is how you should write the replacement mutate(data, across(.cols = everything(), \(x) replace_na(x, 0))) –
Ulotrichous If we are trying to replace NAs when exporting, for example when writing to csv, then we can use:
write.csv(data, "data.csv", na = "0")
readr::write_csv and read.csv or readr::read_csv. When reading, can be a vector of possible values. –
Andrea I know the question is already answered, but doing it this way might be more useful to some:
Define this function:
na.zero <- function (x) {
x[is.na(x)] <- 0
return(x)
}
Now whenever you need to convert NA's in a vector to zero's you can do:
na.zero(some.vector)
return(x) is not needed, x is sufficient. –
Adiaphorism More general approach of using replace() in matrix or vector to replace NA to 0
For example:
> x <- c(1,2,NA,NA,1,1)
> x1 <- replace(x,is.na(x),0)
> x1
[1] 1 2 0 0 1 1
This is also an alternative to using ifelse() in dplyr
df = data.frame(col = c(1,2,NA,NA,1,1))
df <- df %>%
mutate(col = replace(col,is.na(col),0))
levels(A$x) <- append(levels(A$x), "notAnswered") A$x <- replace(A$x,which(is.na(A$x)),"notAnswered") –
Pecker which isn't needed here, you can use x1 <- replace(x,is.na(x),1). –
Nineveh NA to 0 in just one specific column in a large data frame and this function replace() worked the most effectively while also the most simply. –
Importation With dplyr 0.5.0, you can use coalesce function which can be easily integrated into %>% pipeline by doing coalesce(vec, 0). This replaces all NAs in vec with 0:
Say we have a data frame with NAs:
library(dplyr)
df <- data.frame(v = c(1, 2, 3, NA, 5, 6, 8))
df
# v
# 1 1
# 2 2
# 3 3
# 4 NA
# 5 5
# 6 6
# 7 8
df %>% mutate(v = coalesce(v, 0))
# v
# 1 1
# 2 2
# 3 3
# 4 0
# 5 5
# 6 6
# 7 8
mutate(across(where(is.character), ~ coalesce(.x, 0))) –
Narcotic To replace all NAs in a dataframe you can use:
df %>% replace(is.na(.), 0)
Would've commented on @ianmunoz's post but I don't have enough reputation. You can combine dplyr's mutate_each and replace to take care of the NA to 0 replacement. Using the dataframe from @aL3xa's answer...
> m <- matrix(sample(c(NA, 1:10), 100, replace = TRUE), 10)
> d <- as.data.frame(m)
> d
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
1 4 8 1 9 6 9 NA 8 9 8
2 8 3 6 8 2 1 NA NA 6 3
3 6 6 3 NA 2 NA NA 5 7 7
4 10 6 1 1 7 9 1 10 3 10
5 10 6 7 10 10 3 2 5 4 6
6 2 4 1 5 7 NA NA 8 4 4
7 7 2 3 1 4 10 NA 8 7 7
8 9 5 8 10 5 3 5 8 3 2
9 9 1 8 7 6 5 NA NA 6 7
10 6 10 8 7 1 1 2 2 5 7
> d %>% mutate_each( funs_( interp( ~replace(., is.na(.),0) ) ) )
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
1 4 8 1 9 6 9 0 8 9 8
2 8 3 6 8 2 1 0 0 6 3
3 6 6 3 0 2 0 0 5 7 7
4 10 6 1 1 7 9 1 10 3 10
5 10 6 7 10 10 3 2 5 4 6
6 2 4 1 5 7 0 0 8 4 4
7 7 2 3 1 4 10 0 8 7 7
8 9 5 8 10 5 3 5 8 3 2
9 9 1 8 7 6 5 0 0 6 7
10 6 10 8 7 1 1 2 2 5 7
We're using standard evaluation (SE) here which is why we need the underscore on "funs_." We also use lazyeval's interp/~ and the . references "everything we are working with", i.e. the data frame. Now there are zeros!
Another example using imputeTS package:
library(imputeTS)
na.replace(yourDataframe, 0)
If you want to replace NAs in factor variables, this might be useful:
n <- length(levels(data.vector))+1
data.vector <- as.numeric(data.vector)
data.vector[is.na(data.vector)] <- n
data.vector <- as.factor(data.vector)
levels(data.vector) <- c("level1","level2",...,"leveln", "NAlevel")
It transforms a factor-vector into a numeric vector and adds another artifical numeric factor level, which is then transformed back to a factor-vector with one extra "NA-level" of your choice.
Dedicated functions, nafill and setnafill, for that purpose is in data.table.
Whenever available, they distribute columns to be computed on multiple threads.
library(data.table)
ans_df <- nafill(df, fill=0)
# or even faster, in-place
setnafill(df, fill=0)
In newer versions of dplyr:
across() supersedes the family of "scoped variants" like summarise_at(), summarise_if(), and summarise_all().
df <- data.frame(a = c(LETTERS[1:3], NA), b = c(NA, 1:3))
library(tidyverse)
df %>%
mutate(across(where(anyNA), ~ replace_na(., 0)))
a b
1 A 0
2 B 1
3 C 2
4 0 3
This code will coerce 0 to be character in the first column. To replace NA based on column type you can use a purrr-like formula in where:
df %>%
mutate(across(where(~ anyNA(.) & is.character(.)), ~ replace_na(., "0")))
No need to use any library.
df <- data.frame(a=c(1,3,5,NA))
df$a[is.na(df$a)] <- 0
df
You can use replace()
For example:
> x <- c(-1,0,1,0,NA,0,1,1)
> x1 <- replace(x,5,1)
> x1
[1] -1 0 1 0 1 0 1 1
> x1 <- replace(x,5,mean(x,na.rm=T))
> x1
[1] -1.00 0.00 1.00 0.00 0.29 0.00 1.00 1.00
NAs in your vector. It's fine for small vectors as in your example. –
Sheelagh x1 <- replace(x,is.na(x),1) will work without explicitly listing the index values. –
Nineveh The cleaner package has an na_replace() generic, that at default replaces numeric values with zeroes, logicals with FALSE, dates with today, etc.:
library(dplyr)
library(cleaner)
starwars %>% na_replace()
na_replace(starwars)
It even supports vectorised replacements:
mtcars[1:6, c("mpg", "hp")] <- NA
na_replace(mtcars, mpg, hp, replacement = c(999, 123))
Documentation: https://msberends.github.io/cleaner/reference/na_replace.html
Another dplyr pipe compatible option with tidyrmethod replace_na that works for several columns:
require(dplyr)
require(tidyr)
m <- matrix(sample(c(NA, 1:10), 100, replace = TRUE), 10)
d <- as.data.frame(m)
myList <- setNames(lapply(vector("list", ncol(d)), function(x) x <- 0), names(d))
df <- d %>% replace_na(myList)
You can easily restrict to e.g. numeric columns:
d$str <- c("string", NA)
myList <- myList[sapply(d, is.numeric)]
df <- d %>% replace_na(myList)
This simple function extracted from Datacamp could help:
replace_missings <- function(x, replacement) {
is_miss <- is.na(x)
x[is_miss] <- replacement
message(sum(is_miss), " missings replaced by the value ", replacement)
x
}
Then
replace_missings(df, replacement = 0)
An easy way to write it is with if_na from hablar:
library(dplyr)
library(hablar)
df <- tibble(a = c(1, 2, 3, NA, 5, 6, 8))
df %>%
mutate(a = if_na(a, 0))
which returns:
a
<dbl>
1 1
2 2
3 3
4 0
5 5
6 6
7 8
Another option is to use collapse::replace_NA. By default, replace_NA replaces NAs with 0s.
library(collapse)
replace_NA(df)
For only some columns:
replace_NA(df, cols = c("V1", "V5"))
#Alternatively, one can use a function, indices or a logical vector to select the columns
It's also faster than any other answer (see this answer for a comparison):
set.seed(42) # to recreate the exact dataframe
dfN <- as.data.frame(matrix(sample(c(NA, as.numeric(1:4)), 1e7*10, replace = TRUE),
dimnames = list(NULL, paste0("var", 1:10)),
ncol = 10))
microbenchmark(collapse = replace_NA(dfN))
# Unit: milliseconds
# expr min lq mean median uq max neval
# collapse 508.9198 621.405 751.3413 714.835 859.5437 1298.69 100
Replace is.na & NULL in data frame.
A$name[is.na(A$name)]<-0
OR
A$name[is.na(A$name)]<-"NA"
df[is.na(df)]<-0
df[is.na(df)]<-""
df[is.null(df)] <- NA
if you want to assign a new name after changing the NAs in a specific column in this case column V3, use you can do also like this
my.data.frame$the.new.column.name <- ifelse(is.na(my.data.frame$V3),0,1)
I wan to add a next solution which using a popular Hmisc package.
library(Hmisc)
data(airquality)
# imputing with 0 - all columns
# although my favorite one for simple imputations is Hmisc::impute(x, "random")
> dd <- data.frame(Map(function(x) Hmisc::impute(x, 0), airquality))
> str(dd[[1]])
'impute' Named num [1:153] 41 36 12 18 0 28 23 19 8 0 ...
- attr(*, "names")= chr [1:153] "1" "2" "3" "4" ...
- attr(*, "imputed")= int [1:37] 5 10 25 26 27 32 33 34 35 36 ...
> dd[[1]][1:10]
1 2 3 4 5 6 7 8 9 10
41 36 12 18 0* 28 23 19 8 0*
There could be seen that all imputations metadata are allocated as attributes. Thus it could be used later.
This is not exactly a new solution, but I like to write inline lambdas that handle things that I can't quite get packages to do. In this case,
df %>%
(function(x) { x[is.na(x)] <- 0; return(x) })
Because R does not ever "pass by object" like you might see in Python, this solution does not modify the original variable df, and so will do quite the same as most of the other solutions, but with much less need for intricate knowledge of particular packages.
Note the parens around the function definition! Though it seems a bit redundant to me, since the function definition is surrounded in curly braces, it is required that inline functions are defined within parens for magrittr.
This is a more flexible solution. It works no matter how large your data frame is, or zero is indicated by 0 or zero or whatsoever.
library(dplyr) # make sure dplyr ver is >= 1.00
df %>%
mutate(across(everything(), na_if, 0)) # if 0 is indicated by `zero` then replace `0` with `zero`
Another option using sapply to replace all NA with zeros. Here is some reproducible code (data from @aL3xa):
set.seed(7) # for reproducibility
m <- matrix(sample(c(NA, 1:10), 100, replace = TRUE), 10)
d <- as.data.frame(m)
d
#> V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
#> 1 9 7 5 5 7 7 4 6 6 7
#> 2 2 5 10 7 8 9 8 8 1 8
#> 3 6 7 4 10 4 9 6 8 NA 10
#> 4 1 10 3 7 5 7 7 7 NA 8
#> 5 9 9 10 NA 7 10 1 5 NA 5
#> 6 5 2 5 10 8 1 1 5 10 3
#> 7 7 3 9 3 1 6 7 3 1 10
#> 8 7 7 6 8 4 4 5 NA 8 7
#> 9 2 1 1 2 7 5 9 10 9 3
#> 10 7 5 3 4 9 2 7 6 NA 5
d[sapply(d, \(x) is.na(x))] <- 0
d
#> V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
#> 1 9 7 5 5 7 7 4 6 6 7
#> 2 2 5 10 7 8 9 8 8 1 8
#> 3 6 7 4 10 4 9 6 8 0 10
#> 4 1 10 3 7 5 7 7 7 0 8
#> 5 9 9 10 0 7 10 1 5 0 5
#> 6 5 2 5 10 8 1 1 5 10 3
#> 7 7 3 9 3 1 6 7 3 1 10
#> 8 7 7 6 8 4 4 5 0 8 7
#> 9 2 1 1 2 7 5 9 10 9 3
#> 10 7 5 3 4 9 2 7 6 0 5
Created on 2023-01-15 with reprex v2.0.2
Please note: Since R 4.1.0 you can use \(x) instead of function(x).
in data.frame it is not necessary to create a new column by mutate.
library(tidyverse)
k <- c(1,2,80,NA,NA,51)
j <- c(NA,NA,3,31,12,NA)
df <- data.frame(k,j)%>%
replace_na(list(j=0))#convert only column j, for example
result
k j
1 0
2 0
80 3
NA 31
NA 12
51 0
I used this personally and works fine:
players_wd$APPROVED_WD[is.na(players_wd$APPROVED_WD)] <- 0
© 2022 - 2024 — McMap. All rights reserved.