Repeatable read isolation level guarantees that each transaction will read from the consistent snapshot of the database. In other words, a row is retrieved twice within the same transaction always has the same values.
Many databases such as Postgres, SQLServer in repeatable read isolation levels can detect lost update (a special case of write skew) but others don't. (i.e: InnoDB engine in MySQL)
We're back to write skew phenomena problem. There are situations that most database engines cannot detect in the repeatable read isolation. One case is when 2 concurrent transactions modifies 2 different objects and making race conditions.
I take an example from the book Designing Data-Intensive Application. Here is the scenario:
You are writing an application for doctors to manage their on-call
shifts at a hospital. The hospital usually tries to have several
doctors on call at any one time, but it absolutely must have at least
one doctor on call. Doctors can give up their shifts (e.g., if they
are sick themselves), provided that at least one colleague remains on
call in that shift
The next interesting question is how we can implement this under databases. Here is pseudocode SQL code:
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 1234;
if (current_on_call >= 2) {
UPDATE doctors
SET on_call = false WHERE name = 'Alice' AND shift_id = 1234;
}
COMMIT;
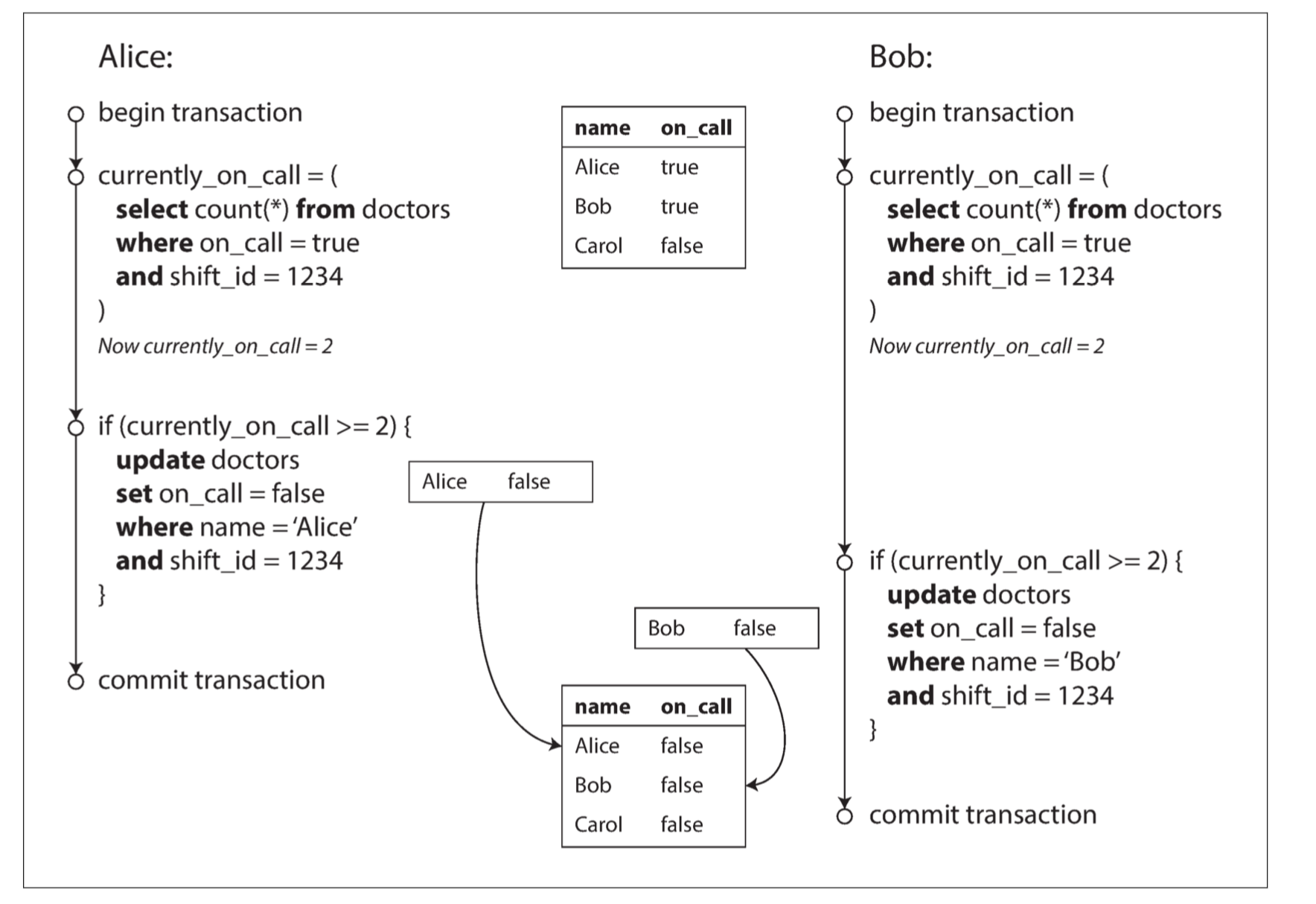
Here is the illustration:
![Flow Data]()
As the above illustration, we see that Bob and Alice run above SQL code concurrently. However Bob and Alice modify different data, Bob modified Bob's record and Alice modified Alice's record. Databases at repeatable-read isolation level no way can know and check the condition (total doctor >= 2) has been violated. Write skew phenomena has happened.
To solve this problem, there are 2 methods proposed:
- locks all records that are being called manually. So either Bob or Alice will wait until other finishes transaction.
Here is some pseudocode using SELECT .. FOR UPDATE query.
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 1234 FOR UPDATE; // important here: locks all records that satisfied requirements.
if (current_on_call >= 2) {
UPDATE doctors
SET on_call = false WHERE name = 'Alice' AND shift_id = 1234;
}
COMMIT;
- Using a more strict isolation level. Both MySQL, Postgres T-SQL provides serialize isolation level.
InnoDB implicitly converts all plain SELECT statements to SELECT ... FOR SHARE. I think that means that even with Serializeable IL in MySQL, pure 2PL shared lock can't prevent the write skew in the described scenario as both transactions can still read the rows and evaluate the if statement in parallel – Baptism