Trying to do doc classification in Spark. I am not sure what the hashing does in HashingTF; does it sacrifice any accuracy? I doubt it, but I don't know. The spark doc says it uses the "hashing trick"... just another example of really bad/confusing naming used by engineers (I'm guilty as well). CountVectorizer also requires setting the vocabulary size, but it has another parameter, a threshold param that can be used to exclude words or tokens that appear below some threshold in the text corpus. I do not understand the difference between these two Transformers. What makes this important is the subsequent steps in the algorithm. For example, if I wanted to perform SVD on the resulting tfidf matrix, then vocabulary size will determine the size of the matrix for SVD, which impacts the running time of the code, and the model performance etc. I am having a difficulty in general finding any source about Spark Mllib beyond API documentation and really trivial examples with no depth.
A few important differences:
- partially reversible (
CountVectorizer) vs irreversible (HashingTF) - since hashing is not reversible you cannot restore original input from a hash vector. From the other hand count vector with model (index) can be used to restore unordered input. As a consequence models created using hashed input can be much harder to interpret and monitor. - memory and computational overhead -
HashingTFrequires only a single data scan and no additional memory beyond original input and vector.CountVectorizerrequires additional scan over the data to build a model and additional memory to store vocabulary (index). In case of unigram language model it is usually not a problem but in case of higher n-grams it can be prohibitively expensive or not feasible. - hashing depends on a size of the vector , hashing function and a document. Counting depends on a size of the vector, training corpus and a document.
- a source of the information loss - in case of
HashingTFit is dimensionality reduction with possible collisions.CountVectorizerdiscards infrequent tokens. How it affects downstream models depends on a particular use case and data.
As per the Spark 2.1.0 documentation,
Both HashingTF and CountVectorizer can be used to generate the term frequency vectors.
HashingTF
HashingTF is a Transformer which takes sets of terms and converts those sets into fixed-length feature vectors. In text processing, a “set of terms” might be a bag of words. HashingTF utilizes the hashing trick. A raw feature is mapped into an index (term) by applying a hash function. The hash function used here is MurmurHash 3. Then term frequencies are calculated based on the mapped indices. This approach avoids the need to compute a global term-to-index map, which can be expensive for a large corpus, but it suffers from potential hash collisions, where different raw features may become the same term after hashing.
To reduce the chance of collision, we can increase the target feature dimension, i.e. the number of buckets of the hash table. Since a simple modulo is used to transform the hash function to a column index, it is advisable to use a power of two as the feature dimension, otherwise the features will not be mapped evenly to the columns. The default feature dimension is 2^18=262,144. An optional binary toggle parameter controls term frequency counts. When set to true all nonzero frequency counts are set to 1. This is especially useful for discrete probabilistic models that model binary, rather than integer, counts.
CountVectorizer
CountVectorizer and CountVectorizerModel aim to help convert a collection of text documents to vectors of token counts. When an a-priori dictionary is not available, CountVectorizer can be used as an Estimator to extract the vocabulary, and generates a CountVectorizerModel. The model produces sparse representations for the documents over the vocabulary, which can then be passed to other algorithms like LDA.
During the fitting process, CountVectorizer will select the top vocabSize words ordered by term frequency across the corpus. An optional parameter minDF also affects the fitting process by specifying the minimum number (or fraction if < 1.0) of documents a term must appear in to be included in the vocabulary. Another optional binary toggle parameter controls the output vector. If set to true all nonzero counts are set to 1. This is especially useful for discrete probabilistic models that model binary, rather than integer, counts.
Sample code
from pyspark.ml.feature import HashingTF, IDF, Tokenizer
from pyspark.ml.feature import CountVectorizer
sentenceData = spark.createDataFrame([
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")],
["label", "sentence"])
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
wordsData = tokenizer.transform(sentenceData)
hashingTF = HashingTF(inputCol="words", outputCol="Features", numFeatures=100)
hashingTF_model = hashingTF.transform(wordsData)
print "Out of hashingTF function"
hashingTF_model.select('words',col('Features').alias('Features(vocab_size,[index],[tf])')).show(truncate=False)
# fit a CountVectorizerModel from the corpus.
cv = CountVectorizer(inputCol="words", outputCol="Features", vocabSize=20)
cv_model = cv.fit(wordsData)
cv_result = model.transform(wordsData)
print "Out of CountVectorizer function"
cv_result.select('words',col('Features').alias('Features(vocab_size,[index],[tf])')).show(truncate=False)
print "Vocabulary from CountVectorizerModel is \n" + str(cv_model.vocabulary)
Output is as below
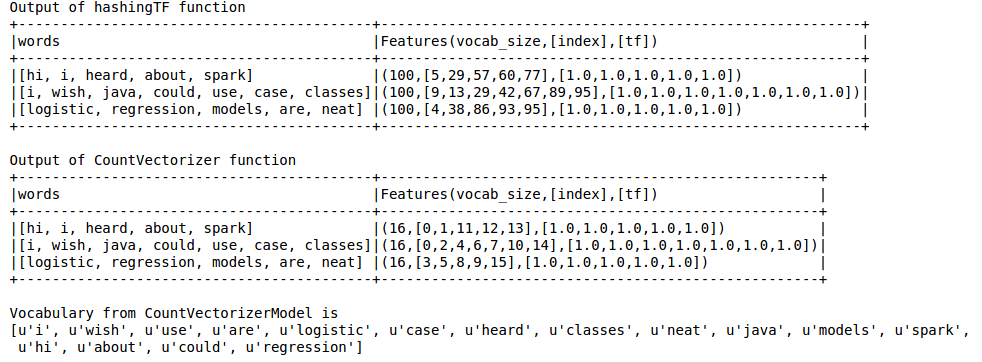
Hashing TF misses the vocabulary which is essential for techniques like LDA. For this one has to use CountVectorizer function. Irrespective of the vocab size, CountVectorizer function estimates the term frequency without any approximation involved unlike in HashingTF.
Reference:
https://spark.apache.org/docs/latest/ml-features.html#tf-idf
https://spark.apache.org/docs/latest/ml-features.html#countvectorizer
CountVectorizer, after fitting, returns a CountVectorizerModel, which has a vocabulary member so you can see the vocab it extracted . HashingTF does not. Maybe this is why HashingTF is less "reversible" per the accepted answer "As a consequence models created using hashed input can be much harder to interpret and monitor." –
Rizal The hashing trick is actually the other name of feature hashing.
I'm citing Wikipedia's definition :
In machine learning, feature hashing, also known as the hashing trick, by analogy to the kernel trick, is a fast and space-efficient way of vectorizing features, i.e. turning arbitrary features into indices in a vector or matrix. It works by applying a hash function to the features and using their hash values as indices directly, rather than looking the indices up in an associative array.
You can read more about it in this paper.
So actually actually for space efficient features vectorizing.
Whereas CountVectorizer performs just a vocabulary extraction and it transforms into Vectors.
indexOf is hash modulo numFeatures (https://mcmap.net/q/538462/-what-hashing-function-does-spark-use-for-hashingtf-and-how-do-i-duplicate-it) –
Andean The answers are great. Just adding a bit more context & code examples:
Similarities/Importance of CountVectorizer and HashingTF
First, the Spark website describes "TF-IDF"
Term frequency-inverse document frequency (TF-IDF) is a feature vectorization method widely used in text mining
...and goes on to say...
TF: Both
HashingTFandCountVectorizercan be used to generate the term frequency vectors.
So that's why we should ask "what is the difference between CountVectorizer and HashingTF",or " when should we use one or the other?"
I tried to learn and demonstrate some difference between CountVectorizer and HashingTF in this Google Colab
API difference: CountVectorizer must be fit
CountVectorizermust befit, which produces a newCountVectorizerModel, which cantransform- vs
HashingTFdoes not need to befit,HashingTFinstance can transform directly
For example
CountVectorizer(inputCol="words", outputCol="features") \
.fit(words_data_frame) \
.transform(words_data_frame)
vs:
HashingTF(inputCol="words", outputCol="features") \
.transform(words_data_frame)
In this API difference CountVectorizer has an extra fit API step. Maybe this is because CountVectorizer does extra work to create a vocabulary (see accepted answer):
CountVectorizer requires additional scan over the data to build a model and additional memory to store vocabulary (index).
Skip the CountVectorizer.fit() step
You can skip the fitting step if you can create a CountVectorizerModel "with a-priori vocabulary", as shown in example:
# alternatively, define CountVectorizerModel with a-priori vocabulary
# spark website shows Scala syntax, here is Python syntax
cvm = CountVectorizerModel \
.from_vocabulary(["a", "b", "c"], "words") \
.setOutputCol("features")
cvm.transform(words_data_frame).show()
CountVectorizer vocabulary means it is reversible
CountVectorizer builds a vocabulary, which is why you can reverse the process of transform as mentioned in the accepted answer. In other words, when you use CountVectorizer, you can "get the words back from the hash"
Collision Difference: HashingTF Collision Potential
HashingTF may create collisions! This means two different features/words are treated as the same term. Accepted answer says this:
... a source of the information loss - in case of HashingTF it is dimensionality reduction with possible collisions
Collisions are a problem regardless of the value of numFeatures, but are especially a problem the lower the value of numFeatures, like pow(2,4) or pow(2,8)). In this example:
words_data_frame = spark.createDataFrame([([
'one', 'two', 'three', 'four', 'five',
'six', 'seven', 'eight', 'nine', 'ten'],)], ['words'])
hashing = HashingTF() \
.setInputCol("words") \
.setOutputCol("features") \
.setNumFeatures(pow(2,4))
hashed_df = hashing.transform(words_data_frame)
hashed_df[['features']].show(truncate=False)
+-----------------------------------------------------------+
|features |
+-----------------------------------------------------------+
|(16,[0,1,2,6,8,11,12,13],[1.0,1.0,1.0,3.0,1.0,1.0,1.0,1.0])|
+-----------------------------------------------------------+
Let's analyze the "features" output; the output contains 16 "hash buckets" (because I used .setNumFeatures(pow(2,4)))
16...
While my input had 10 unique tokens, and numFeatures was large enough to fit all the unique tokens, the output only creates 8 unique hashes (due to hash collisions);
.... v-------8x--------v....
..., [0,1,2,6,8,11,12,13], ...
Hash collisions mean 3 distinct tokens are given the same hash, (even though all tokens are unique; and should only occur 1x)
...----------------v
..., [1.0,1.0,1.0,3.0,1.0,1.0,1.0,1.0] ...
So if you need to avoid collisions:
- leave the default value of
numFeatures(which is 262,1441), - or increase your
numFeatures
This [Hashing] approach avoids the need to compute a global term-to-index map, which can be expensive for a large corpus, but it suffers from potential hash collisions, where different raw features may become the same term after hashing. To reduce the chance of collision, we can increase the target feature dimension, i.e., the number of buckets of the hash table.
CountVectorizer can have information loss too
CountVectorizer has vocabSize which is analogous to HashingTF's numFeatures1
- That is, if
CountVectorizer.vocabSizeis too small (smaller than the count of unique tokens), certain words won't be captured in your output/features; this is also a form of "information loss" (see example below)! Compare toHashingTFwith a too-smallnumFeatures, which would result in a collision. - However, if your
CountVectorizer.vocabSizeis larger than the number of distinct terms, all the distinct words will be represented in your output/features without collision. That's the significance ofHashingTF"collision" potential;HashingTFcollision is possible even if you give a largenumFeatures(larger than the count of unique tokens)
This example shows how CountVectorizer can result in information loss if your vocabSize is too small. But that's different than a collision:
cvm = CountVectorizer() \
.setInputCol("words") \
.setOutputCol("features") \
.setVocabSize(8) \ # Notice the vocabSize is too small
.fit(words_data_frame)
count_df = cvm \
.transform(words_data_frame)
count_df[['features']].show(truncate=False)
+-------------------------------------------------------+
|features |
+-------------------------------------------------------+
|(8,[0,1,2,3,4,5,6,7],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0])|
+-------------------------------------------------------+
Notice how the cvm.vocabulary does not include the word/token 'four', that's "information loss" -- because we gave too small a vocabSize:
cvm.vocabulary
['two', 'seven', 'eight', 'one', 'nine', 'six', 'three', 'five']
Consistency across corpus (given the same numFeatures / vocabSize)
Within a corpus (a set of documents; i.e. a single dataframe), HashingTF and CountVectorizer will assign the same integer to a given token/word/term.
However, across different corpus/dataframes, only HashingTF will assign the same integer to a given token/word/term (Thanks @MutasimMim for this point; see the comments), and only if you re-use a HashingTF; or the same value for numFeatures is used for each HashingTF you create
For example, notice how CountVectorizer handles these two dataframes:
In the first dataframe, the token 'apple' is assigned the integer 0
+---------------------+-------------+
|words |features |
+---------------------+-------------+
|[apple, apple, apple]|(1,[0],[3.0])|
+---------------------+-------------+
In the second dataframe, the token 'banana' is assigned the integer 0, the token 'apple' is now assigned 1, a different integer than the previous dataframe!
+-------------------------------+-------------------+
|words |features |
+-------------------------------+-------------------+
|[apple, banana, banana, banana]|(2,[0,1],[3.0,1.0])|
+-------------------------------+-------------------+
In a HashingTF, the token 'apple' is assigned the same integer (13) regardless of the dataframe. This consistency is one possible benefit of a hash function (specifically Austin Appleby's MurmurHash 3 function used by HashingTF):
+---------------------+---------------+
|words |features |
+---------------------+---------------+
|[apple, apple, apple]|(16,[13],[3.0])|
+---------------------+---------------+
+-------------------------------+---------------------+
|words |features |
+-------------------------------+---------------------+
|[apple, banana, banana, banana]|(16,[8,13],[3.0,1.0])|
+-------------------------------+---------------------+
Note within a single dataframe, both CountVectorizer and HashingTF will be consistent in assigning an integer to a given token. The above example is just to illustrate across dataframes (which may never apply to you; merge your dataframes within a single problem?)
Other Concerns
Consider that a TF-IDF vectorizer might be a better approach than a CountVectorizer or HashingTF alone. As it says here:
The problem with (count encoding) is that common words that occur in similar features... observed that tf-idf encoding is marginally better than (count encoding) in terms of accuracy (on average: 0.25-15% higher)...
TfIdfVectorizer is "equivalent to CountVectorizer followed by TfidfTransformer", so it does not have hash collisions like a HashingTF, and does have the API options of the CountVectorizer etc...
Other API differences
CountVectorizerconstructor (i.e. when initializing) supports extra params:minDF: (min document frequency) minimum number of different documents a term must appear in to be included in the vocabularymaxDF: (max document frequency) maximum number of different documents a term could appear in to be included in the vocabularyminTF: (min term frequency) For each document, terms with frequency/count less than the given threshold are ignored- etc...
CountVectorizerModelhas avocabularymember, so you can see thevocabularygenerated (especially useful if youfityourCountVectorizer):countVectorizerModel.vocabulary>>> [u'one', u'two', ...]
CountVectorizeris "reversible" as the main answer says! Use itsvocabularymember, which is an array mapping the term index, to the term (sklearn'sCountVectorizerdoes something similar)
Other Similarities
- 1
HashingTFnumFeaturesdefault value is same asCountVectorizervocabSizedefault value:- the default
numFeaturesforHashingTFispow(2,18) == 1 << 18 == 262144 - the default
vocabSizeforCountVectorizeris the samepow(2,18) == 1 << 18 == 262144
- the default
HashingTF and CountVectorizer, isn't it? If you post it as an answer, I'll upvote your answer! For now I'll mention this difference in my answer in the meantime.... –
Rizal HashingTF, the word "two" is always assigned the hash 8. With CountVectorizer, the word "two" is assigned the hash 0, but not always! CountVectorizer seems to assign a word's integer based on its frequency, then its location in the document? So not consistent across different dataframes. –
Rizal © 2022 - 2024 — McMap. All rights reserved.