I have a quite simple ANN using Tensorflow and AdamOptimizer for a regression problem and I am now at the point to tune all the hyperparameters.
For now, I saw many different hyperparameters that I have to tune :
- Learning rate : initial learning rate, learning rate decay
- The AdamOptimizer needs 4 arguments (learning-rate, beta1, beta2, epsilon) so we need to tune them - at least epsilon
- batch-size
- nb of iterations
- Lambda L2-regularization parameter
- Number of neurons, number of layers
- what kind of activation function for the hidden layers, for the output layer
- dropout parameter
I have 2 questions :
1) Do you see any other hyperparameter I might have forgotten ?
2) For now, my tuning is quite "manual" and I am not sure I am not doing everything in a proper way. Is there a special order to tune the parameters ? E.g learning rate first, then batch size, then ... I am not sure that all these parameters are independent - in fact, I am quite sure that some of them are not. Which ones are clearly independent and which ones are clearly not independent ? Should we then tune them together ? Is there any paper or article which talks about properly tuning all the parameters in a special order ?
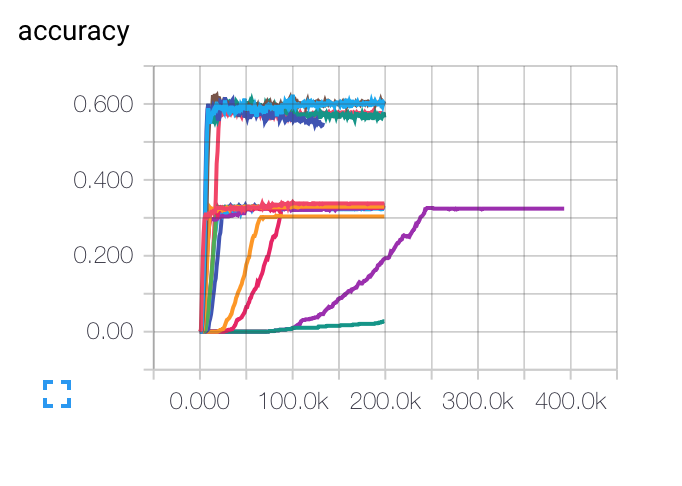
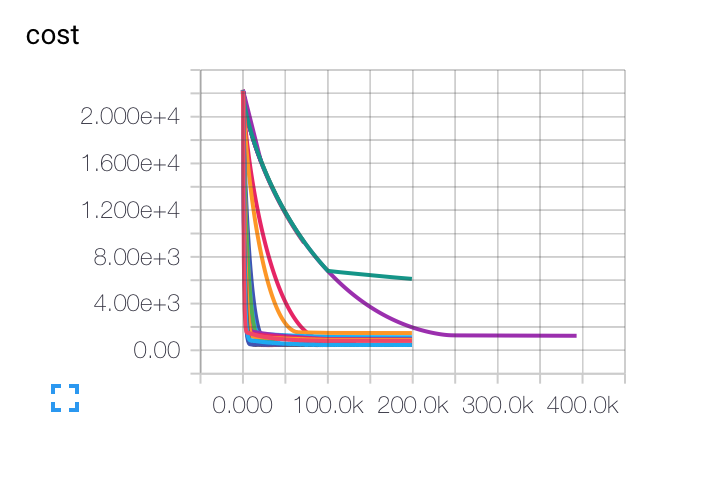
EDIT : Here are the graphs I got for different initial learning rates, batch sizes and regularization parameters. The purple curve is completely weird for me... Because the cost decreases like way slowly that the others, but it got stuck at a lower accuracy rate. Is it possible that the model is stuck in a local minimum ?
{kind=link}
{kind=link}
For the learning rate, I used the decay : LR(t) = LRI/sqrt(epoch)
Thanks for your help ! Paul
LRI/sqrt(epoch)as the learning rate decay? I'm usingLRI/max(epoch_0, epoch), where I have setepoch_0to the epoch in which I want the decay to start, but maybe you get faster convergence if you take the squarer root of the denominator like you do. Do you have any reference for that learning rate decay or did you come up with it more or less yourself? – Bebeeru