I want to understand what is meant by "dimensionality" in word embeddings.
When I embed a word in the form of a matrix for NLP tasks, what role does dimensionality play? Is there a visual example which can help me understand this concept?
I want to understand what is meant by "dimensionality" in word embeddings.
When I embed a word in the form of a matrix for NLP tasks, what role does dimensionality play? Is there a visual example which can help me understand this concept?
A Word Embedding is just a mapping from words to vectors. Dimensionality in word embeddings refers to the length of these vectors.
These mappings come in different formats. Most pre-trained embeddings are
available as a space-separated text file, where each line contains a word in the
first position, and its vector representation next to it. If you were to split
these lines, you would find out that they are of length 1 + dim, where dim
is the dimensionality of the word vectors, and 1 corresponds to the word being represented. See the GloVe pre-trained
vectors for a real example.
For example, if you download glove.twitter.27B.zip, unzip it, and run the following python code:
#!/usr/bin/python3
with open('glove.twitter.27B.50d.txt') as f:
lines = f.readlines()
lines = [line.rstrip().split() for line in lines]
print(len(lines)) # number of words (aka vocabulary size)
print(len(lines[0])) # length of a line
print(lines[130][0]) # word 130
print(lines[130][1:]) # vector representation of word 130
print(len(lines[130][1:])) # dimensionality of word 130
you would get the output
1193514
51
people
['1.4653', '0.4827', ..., '-0.10117', '0.077996'] # shortened for illustration purposes
50
Somewhat unrelated, but equally important, is that lines in these files are sorted according to the word frequency found in the corpus in which the embeddings were trained (most frequent words first).
You could also represent these embeddings as a dictionary where the keys are the words and the values are lists representing word vectors. The length of these lists would be the dimensionality of your word vectors.
A more common practice is to represent them as matrices (also called lookup
tables), of dimension (V x D), where V is the vocabulary size (i.e., how
many words you have), and D is the dimensionality of each word vector. In
this case you need to keep a separate dictionary mapping each word to its
corresponding row in the matrix.
Regarding your question about the role dimensionality plays, you'll need some theoretical background. But in a few words, the space in which words are embedded presents nice properties that allow NLP systems to perform better. One of these properties is that words that have similar meaning are spatially close to each other, that is, have similar vector representations, as measured by a distance metric such as the Euclidean distance or the cosine similarity.
You can visualize a 3D projection of several word embeddings here, and see, for example, that the closest words to "roads" are "highways", "road", and "routes" in the Word2Vec 10K embedding.
For a more detailed explanation I recommend reading the section "Word Embeddings" of this post by Christopher Olah.
For more theory on why using word embeddings, which are an instance of distributed representations, is better than using, for example, one-hot encodings (local representations), I recommend reading the first sections of Distributed Representations by Geoffrey Hinton et al.
The "dimensionality" in word embeddings represent the total number of features that it encodes. Actually, it is over simplification of the definition, but will come to that bit later.
The selection of features is usually not manual, it is automatic by using hidden layer in the training process. Depending on the corpus of literature the most useful dimensions (features) are selected. For example if the literature is about romantic fictions, the dimension for gender is much more likely to be represented compared to the literature of mathematics.
Once you have the word embedding vector of 100 dimensions (for example) generated by neural network for 100,000 unique words, it is not generally much useful to investigate the purpose of each dimension and try to label each dimension by "feature name". Because the feature(s) that each dimension represents may not be simple and orthogonal and since the process is automatic no body knows exactly what each dimension represents.
For more insight to understand this topic you may find this post useful.
Word embeddings like word2vec or GloVe don't embed words in two-dimensional matrices, they use one-dimensional vectors. "Dimensionality" refers to the size of these vectors. It is separate from the size of the vocabulary, which is the number of words you actually keep vectors for instead of just throwing out.
In theory larger vectors can store more information since they have more possible states. In practice there's not much benefit beyond a size of 300-500, and in some applications even smaller vectors work fine.
Here's a graphic from the GloVe homepage.
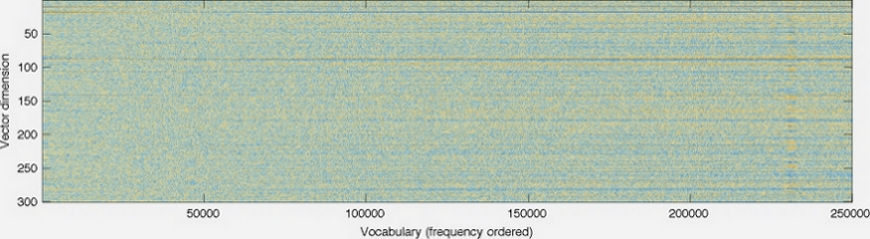
The dimensionality of the vectors is shown on the left axis; decreasing it would make the graph shorter, for example. Each column is an individual vector with color at each pixel determined by the number at that position in the vector.
Textual data has to be converted into numeric data before feeding into any Machine Learning algorithm. Word Embedding is an approach for this where each word is mapped to a vector.
In algebra, A Vector is a point in space with scale & direction. In simpler term Vector is a 1-Dimensional vertical array ( or say a matrix having single column) and Dimensionality is the number of elements in that 1-D vertical array.
Pre-trained word embedding models like Glove, Word2vec provides multiple dimensional options for each word, for instance 50, 100, 200, 300. Each word represents a point in D dimensionality space and synonyms word are points closer to each other. Higher the dimension better shall be the accuracy but computation needs would also be higher.
I'm not an expert, but I think the dimensions just represent the variables (aka attributes or features) which have been assigned to the words, although there may be more to it than that. The meaning of each dimension and total number of dimensions will be specific to your model.
I recently saw this embedding visualisation from the Tensor Flow library: https://www.tensorflow.org/get_started/embedding_viz
This particularly helps reduce high-dimensional models down to something human-perceivable. If you have more than three variables it's extremely difficult to visualise the clustering (unless you are Stephen Hawking apparently).
This wikipedia article on dimensional reduction and related pages discuss how features are represented in dimensions, and the problems of having too many.
According to the book Neural Network Methods for Natural Language Processing by Goldenberg, dimensionality in word embeddings (demb) refers to number of columns in first weight matrix (weights between input layer and hidden layer) of embedding algorithms such as word2vec. N in the image is dimensionality in word embedding:
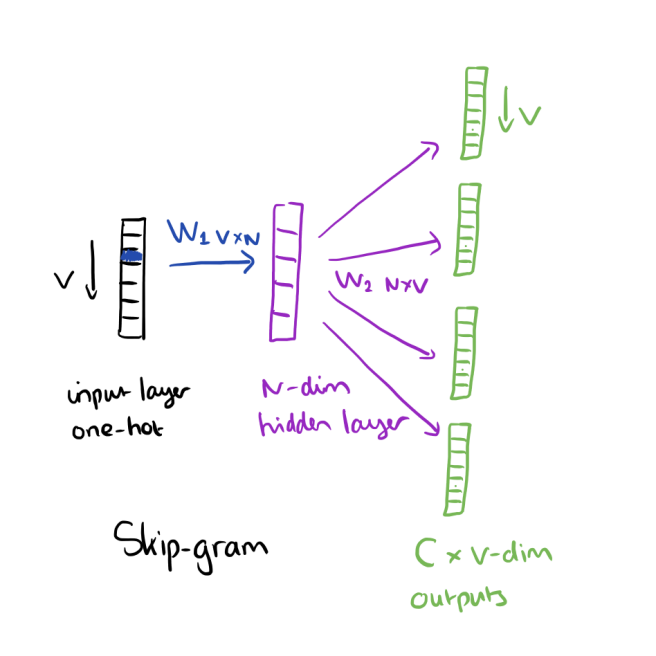
For more information you can refer to this link: https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
© 2022 - 2024 — McMap. All rights reserved.