If you want a simple one-liner, a list comprehension could be used.
train, test = [df.iloc[ind] for ind in next(kf.split(df))]
However, if you want to split a dataframe into two, train_test_split is probably a simpler option because it is really a wrapper for next(ShuffleSplit().split(df)).
If you want to recover all splits of a KFold (perhaps to pass of to another model), then a loop could be useful. Here, in each iteration, one fold will be the validation set.
kf = KFold(n_splits=5, shuffle=True)
for i, (t_ind, v_ind) in enumerate(kf.split(df)):
train = df.iloc[t_ind] # train set
valid = df.iloc[v_ind] # validation set
result = my_model(train, valid)
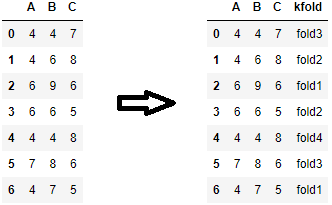
Another use case for a loop over the splits generator is to create a new column for folds.
import numpy as np
import pandas as pd
from sklearn.model_selection import KFold
np.random.seed(100)
df = pd.DataFrame(np.random.randint(4,10, size=(7,3)), columns=list('ABC'))
kf = KFold(n_splits=4, shuffle=True, random_state=0)
for i, (_, v_ind) in enumerate(kf.split(df)):
df.loc[df.index[v_ind], 'kfold'] = f"fold{i+1}"
![result]()