Update:
TL;DR: I think how to treat the SettingWithCopyWarning depends on the purposes. If one wants to avoid modifying df, then working on df.copy() is safe and the warning is redundant. If one wants to modify df, then using .copy() means wrong way and the warning need to be respected.
Disclaimer: I don't have private/personal communications with Pandas' experts like other answerers. So this answer is based on the official Pandas docs, what a typical user would base on, and my own experiences.
SettingWithCopyWarning is not the real problem, it warns about the real problem. User need to understand and solve the real problem, not bypass the warning.
The real problem is that, indexing a dataframe may return a copy, then modifying this copy will not change the original dataframe. The warning asks users to check and avoid that logical bug. For example:
import pandas as pd, numpy as np
np.random.seed(7) # reproducibility
df = pd.DataFrame(np.random.randint(1, 10, (3,3)), columns=['a', 'b', 'c'])
print(df)
a b c
0 5 7 4
1 4 8 8
2 8 9 9
# Setting with chained indexing: not work & warning.
df[df.a>4]['b'] = 1
print(df)
a b c
0 5 7 4
1 4 8 8
2 8 9 9
# Setting with chained indexing: *may* work in some cases & no warning, but don't rely on it, should always avoid chained indexing.
df['b'][df.a>4] = 2
print(df)
a b c
0 5 2 4
1 4 8 8
2 8 2 9
# Setting using .loc[]: guarantee to work.
df.loc[df.a>4, 'b'] = 3
print(df)
a b c
0 5 3 4
1 4 8 8
2 8 3 9
About wrong way to bypass the warning:
df1 = df[df.a>4]['b']
df1.is_copy = None
df1[0] = -1 # no warning because you trick pandas, but will not work for assignment
print(df)
a b c
0 5 7 4
1 4 8 8
2 8 9 9
df1 = df[df.a>4]['b']
df1 = df1.copy()
df1[0] = -1 # no warning because df1 is a separate dataframe now, but will not work for assignment
print(df)
a b c
0 5 7 4
1 4 8 8
2 8 9 9
So, setting df1.is_copy to False or None is just a way to bypass the warning, not to solve the real problem when assigning. Setting df1 = df1.copy() also bypass the warning in another even more wrong way, because df1 is not a weakref of df, but a totally independent dataframe. So if the users want to change values in df, they will receive no warning, but a logical bug. The inexperienced users will not understand why df does not change after being assigned new values. That is why it is advisable to avoid these approaches completely.
If the users only want to work on the copy of the data, that is, strictly not modifying the original df, then it's perfectly correct to call .copy() explicitly. But if they want to modify the data in the original df, they need to respect the warning. The point is, users need to understand what they are doing.
In case of warning because of chained indexing assignment, the correct solution is to avoid assigning values to a copy produced by df[cond1][cond2], but to use the view produced by df.loc[cond1, cond2] instead.
More examples of setting with copy warning/error and solutions are shown in the docs: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
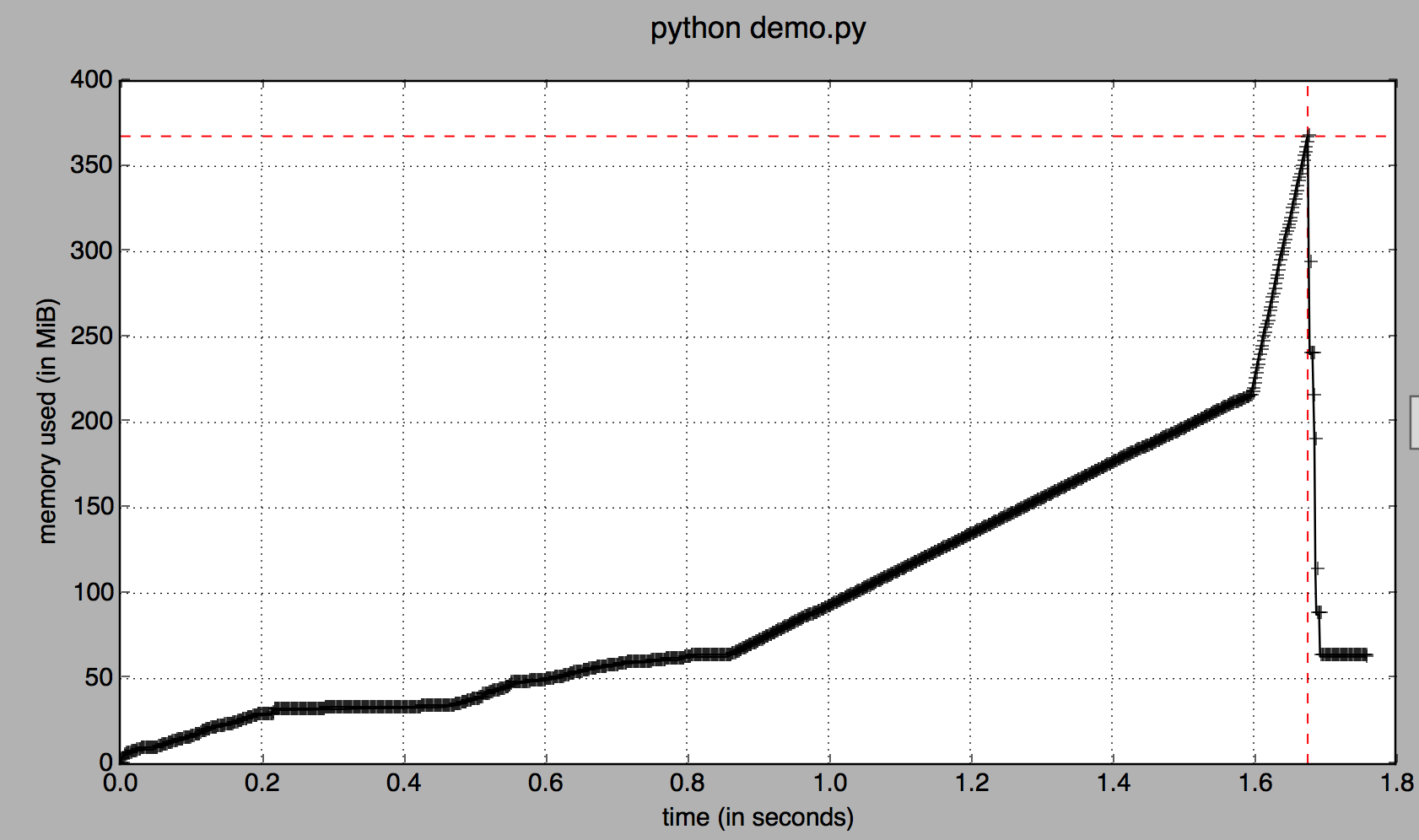
df = df.copy()to bypass the warning a bad idea"? One is about the "difference between views and (temporary) copies" the other is only about "when a possible way to avoid the problem goes haywire". These are loosly connected issues but the answer to these questions will be completly different. – Dinnydf = df.copy()is a bad idea? You mentioned others talking about this, maybe provide some links. I think this question may actually boil down to some general programming best-practice and not a pandas specific issue. – Disarticulatedf = df.copy()blows up. As @thn pointed out, it completely depends on whether you want to work on a copy or not. However, consideroriginal = df; df = df.copy(). This will yield two instances in memory. The original df is not cleaned up by the GC because there is still a reference (original) to it. In a production system this might eventually result in aMemoryError. – Disarticulatedf = df.copy(deep = True)? – Haiphong