recursive algorithm
To count all partitions of an integer n with m parts, a recursive algorithm is the obvious choice. For the case n, m, the algorithm runs through every option k = 1, 2, 3... for the first part, and for each of these options it recurses with the case n - k, m - 1. For example:
n = 16, m = 4
first part = 1 => recurse with n = 15, m = 3
first part = 2 => recurse with n = 14, m = 3
first part = 3 => recurse with n = 13, m = 3
etc...
After a number of recursions, the point is reached where m = 2; then the solutions are:
first part = 1 => second part = n - 1
first part = 2 => second part = n - 2
first part = 3 => second part = n - 3
etc...
So the number of solutions for m = 2 equals the number of options for the first part.
rising sequence
To count only unique solutions and discard duplicates, so that 2+4 and 4+2 are not both counted, only consider solutions where the parts form a non-decreasing sequence; for example:
n = 9, m = 3
partitions: 1+1+7 1+2+6 1+3+5 1+4+4
2+2+5 2+3+4
3+3+3
In a rising sequence, the value of the first part can never be greater than n / m.
recursion with minimum value of 1
To maintain a rising sequence, every recursion must use the value of the previous part as the minimum value for its parts; for example:
n = 9, m = 3
k = 1 => recurse with n = 8, m = 2, k >= 1 => 1+7 2+6 3+5 4+4
k = 2 => recurse with n = 7, m = 2, k >= 2 => 2+5 3+4
k = 3 => recurse with n = 6, m = 2, k >= 3 => 3+3
To avoid having to pass the minimum value with every recursion, every recursion n - k, m - 1, k is replaced with n - k - (m - 1) * (k - 1), m - 1, 1, which has the same number of solutions. For example:
n = 9, m = 3
k = 1 => recurse with n = 8, m = 2, k >= 1 => 1+7 2+6 3+5 4+4
k = 2 => recurse with n = 5, m = 2, k >= 1 => 1+4 2+3
k = 3 => recurse with n = 2, m = 2, k >= 1 => 1+1
Not only does this simplify the code, it also helps improve efficiency when using memoization, because sequences like 2+2+3, 3+3+4 and 5+5+6 are all replaced by their canonical form 1+1+2, and a smaller set of intermediate calculations are repeated more often.
memoization
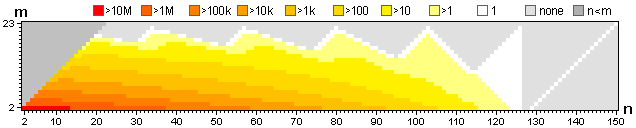
When partitioning with a recursive algorithm, many calculations are repeated numerous times. And with increasing values for n and m, the number of recursions quickly becomes huge; e.g. to solve case 150, 23 (illustrated below), case 4, 2 is calculated 23,703,672 times.
![recursion heatmap for n,m = 150,23]()
However, the number of unique calculations can never be greater than n * m. So by caching the result of each calculation in an n*m-sized array, no more than n * m calculation ever need be done; after having calculated a case once, the algorithm can use the stored value. This hugely improves the algorithm's efficiency; e.g. without memoization, 422,910,232 recursions are needed to solve the case 150, 23; with memoization, only 15,163 recursions are needed.
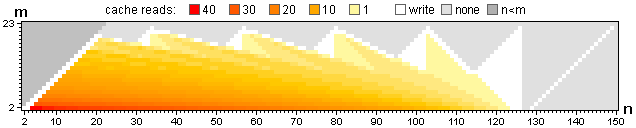
The illustration below shows cache reads and writes for this case. The grey cells are unused, the white cells are written but never read. There are a total of 2042 writes and 12697 reads.
![cache heatmap for n,m = 150,23]()
reducing cache size
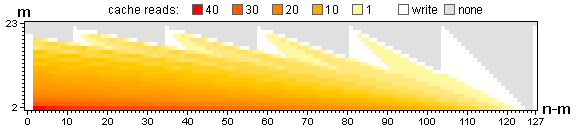
You'll notice that the triangles at the top left and bottom right are never used; and the closer the value of m is to n, the bigger the unused zones become. To avoid this waste of space, the parallellogram inbetween those two triangles can be skewed by 45°, by storing the value for n, m in n - m, m. The cache size is thus reduced from (n - 1) * (m - 1) to (n - m) * (m - 1), and the worst case for n,m <= 150 is no longer 149 * 149 = 22201, but 75 * 74 = 5550, less than 25% the size.
![skewed cache heatmap for n,m = 150,23]()
code example 1: without memoization
function partition(n, m) {
if (m < 2) return m;
if (n < m) return 0;
if (n <= m + 1) return 1;
var max = Math.floor(n / m);
if (m == 2) return max;
var count = 0;
for (; max--; n -= m) count += partition(n - 1, m - 1);
return count;
}
document.write(partition(6, 1) + "<br>"); // 1
document.write(partition(6, 2) + "<br>"); // 3
document.write(partition(9, 3) + "<br>"); // 7
document.write(partition(16, 4) + "<br>"); // 34
document.write(partition(150, 75) + "<br>"); // 8,118,264
// document.write(partition(150, 23)); // 1,901,740,434 (maximum for 150, takes > 10s)
code example 2: fast version with memoization
This version, which caches intermediate results, is much faster than the basic algorithm. Even this Javascript implementation solves the worst-case scenario for n=150 in less than a millisecond.
function partition(n, m) {
if (m < 2) return m;
if (n < m) return 0;
var memo = [];
for (var i = 0; i < n - 1; i++) memo[i] = [];
return p(n, m);
function p(n, m) {
if (n <= m + 1) return 1;
if (memo[n - 2][m - 2]) return memo[n - 2][m - 2];
var max = Math.floor(n / m);
if (m == 2) return max;
var count = 0;
for (; max--; n -= m) count += (memo[n - 3][m - 3] = p(n - 1, m - 1));
return count;
}
}
document.write(partition(150, 23) + "<br>"); // 1,901,740,434
// document.write(partition(1000, 81)); // 4.01779428811641e+29
(The worst case for n = 1000, which is m = 81, solves to 4.01779428811641e+29, and this result is also returned nearly instantly. Because it exceeds Javascript's maximum safe integer of 253-1, this is of course not an exact result.)
code example 3: fast version with memoization and smaller cache
This version uses the skewed cache indexes to reduces memory requirements.
function partition(n, m) {
if (m < 2) return m;
if (n < m) return 0;
var memo = [];
for (var i = 0; i <= n - m; i++) memo[i] = [];
return p(n, m);
function p(n, m) {
if (n <= m + 1) return 1;
if (memo[n - m][m - 2]) return memo[n - m][m - 2];
var max = Math.floor(n / m);
if (m == 2) return max;
var count = 0;
for (; max--; n -= m) count += (memo[n - m][m - 3] = p(n - 1, m - 1));
return count;
}
}
document.write(partition(150, 23) + "<br>"); // 1,901,740,434
document.write(partition(150, 75) + "<br>"); // 8,118,264
document.write(partition(150, 127) + "<br>"); // 1255