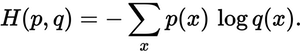Short version:
Suppose you have two tensors, where y_hat contains computed scores for each class (for example, from y = W*x +b) and y_true contains one-hot encoded true labels.
y_hat = ... # Predicted label, e.g. y = tf.matmul(X, W) + b
y_true = ... # True label, one-hot encoded
If you interpret the scores in y_hat as unnormalized log probabilities, then they are logits.
Additionally, the total cross-entropy loss computed in this manner:
y_hat_softmax = tf.nn.softmax(y_hat)
total_loss = tf.reduce_mean(-tf.reduce_sum(y_true * tf.log(y_hat_softmax), [1]))
is essentially equivalent to the total cross-entropy loss computed with the function softmax_cross_entropy_with_logits():
total_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true))
Long version:
In the output layer of your neural network, you will probably compute an array that contains the class scores for each of your training instances, such as from a computation y_hat = W*x + b. To serve as an example, below I've created a y_hat as a 2 x 3 array, where the rows correspond to the training instances and the columns correspond to classes. So here there are 2 training instances and 3 classes.
import tensorflow as tf
import numpy as np
sess = tf.Session()
# Create example y_hat.
y_hat = tf.convert_to_tensor(np.array([[0.5, 1.5, 0.1],[2.2, 1.3, 1.7]]))
sess.run(y_hat)
# array([[ 0.5, 1.5, 0.1],
# [ 2.2, 1.3, 1.7]])
Note that the values are not normalized (i.e. the rows don't add up to 1). In order to normalize them, we can apply the softmax function, which interprets the input as unnormalized log probabilities (aka logits) and outputs normalized linear probabilities.
y_hat_softmax = tf.nn.softmax(y_hat)
sess.run(y_hat_softmax)
# array([[ 0.227863 , 0.61939586, 0.15274114],
# [ 0.49674623, 0.20196195, 0.30129182]])
It's important to fully understand what the softmax output is saying. Below I've shown a table that more clearly represents the output above. It can be seen that, for example, the probability of training instance 1 being "Class 2" is 0.619. The class probabilities for each training instance are normalized, so the sum of each row is 1.0.
Pr(Class 1) Pr(Class 2) Pr(Class 3)
,--------------------------------------
Training instance 1 | 0.227863 | 0.61939586 | 0.15274114
Training instance 2 | 0.49674623 | 0.20196195 | 0.30129182
So now we have class probabilities for each training instance, where we can take the argmax() of each row to generate a final classification. From above, we may generate that training instance 1 belongs to "Class 2" and training instance 2 belongs to "Class 1".
Are these classifications correct? We need to measure against the true labels from the training set. You will need a one-hot encoded y_true array, where again the rows are training instances and columns are classes. Below I've created an example y_true one-hot array where the true label for training instance 1 is "Class 2" and the true label for training instance 2 is "Class 3".
y_true = tf.convert_to_tensor(np.array([[0.0, 1.0, 0.0],[0.0, 0.0, 1.0]]))
sess.run(y_true)
# array([[ 0., 1., 0.],
# [ 0., 0., 1.]])
Is the probability distribution in y_hat_softmax close to the probability distribution in y_true? We can use cross-entropy loss to measure the error.
![Formula for cross-entropy loss]()
We can compute the cross-entropy loss on a row-wise basis and see the results. Below we can see that training instance 1 has a loss of 0.479, while training instance 2 has a higher loss of 1.200. This result makes sense because in our example above, y_hat_softmax showed that training instance 1's highest probability was for "Class 2", which matches training instance 1 in y_true; however, the prediction for training instance 2 showed a highest probability for "Class 1", which does not match the true class "Class 3".
loss_per_instance_1 = -tf.reduce_sum(y_true * tf.log(y_hat_softmax), reduction_indices=[1])
sess.run(loss_per_instance_1)
# array([ 0.4790107 , 1.19967598])
What we really want is the total loss over all the training instances. So we can compute:
total_loss_1 = tf.reduce_mean(-tf.reduce_sum(y_true * tf.log(y_hat_softmax), reduction_indices=[1]))
sess.run(total_loss_1)
# 0.83934333897877944
Using softmax_cross_entropy_with_logits()
We can instead compute the total cross entropy loss using the tf.nn.softmax_cross_entropy_with_logits() function, as shown below.
loss_per_instance_2 = tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true)
sess.run(loss_per_instance_2)
# array([ 0.4790107 , 1.19967598])
total_loss_2 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true))
sess.run(total_loss_2)
# 0.83934333897877922
Note that total_loss_1 and total_loss_2 produce essentially equivalent results with some small differences in the very final digits. However, you might as well use the second approach: it takes one less line of code and accumulates less numerical error because the softmax is done for you inside of softmax_cross_entropy_with_logits().