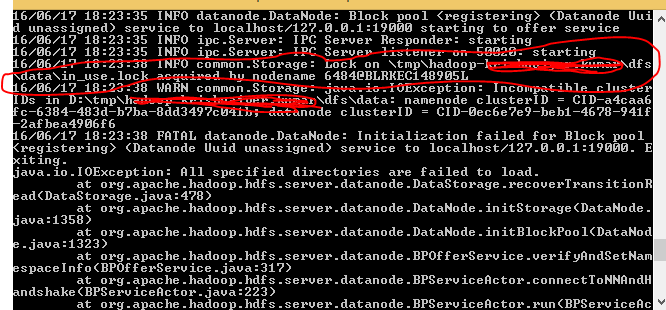
I have 3 data nodes running, while running a job i am getting the following given below error ,
java.io.IOException: File /user/ashsshar/olhcache/loaderMap9b663bd9 could only be replicated to 0 nodes instead of minReplication (=1). There are 3 datanode(s) running and 3 node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget(BlockManager.java:1325)
This error mainly comes when our DataNode instances have ran out of space or if DataNodes are not running. I tried restarting the DataNodes but still getting the same error.
dfsadmin -reports at my cluster nodes clearly shows a lots of space is available.
I am not sure why this is happending.

dfs.datanode.addressport address is open. I had a similar error happen to me and it turned out that out of the several ports I needed to open, I neglected50010. – Soapwort