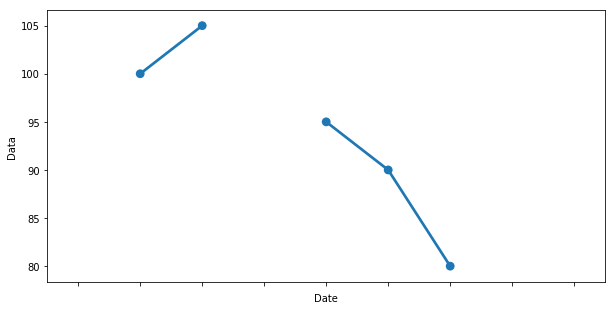
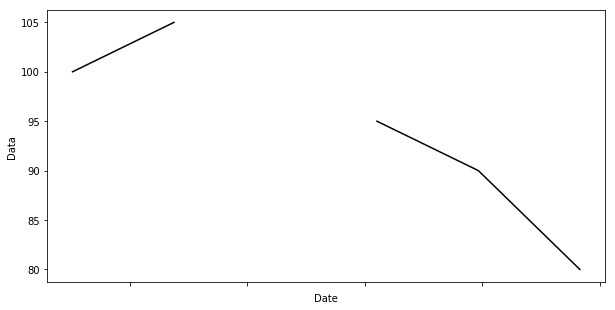
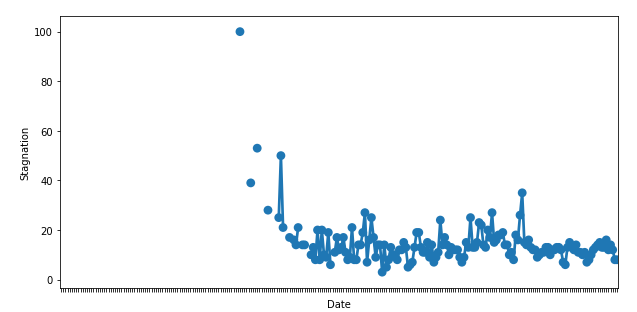
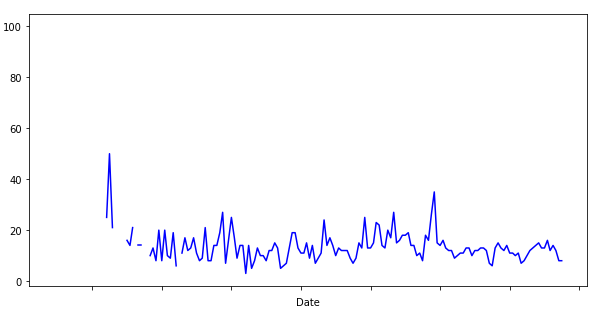
I want a line plot to indicate if a piece of data is missing such as:
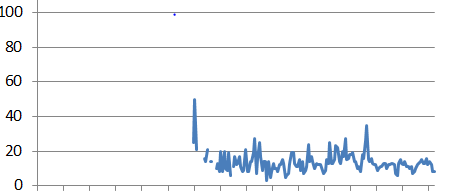
However, the code below fills the missing data, creating a potentially misleading chart:

import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
# load csv
df=pd.read_csv('data.csv')
# plot a graph
g = sns.lineplot(x="Date", y="Data", data=df)
plt.show()
What should I change in my code to avoid filling missing values?
csv looks as following:
Date,Stagnation
01-07-03,
01-08-03,
01-09-03,
01-10-03,
01-11-03,
01-12-03,100
01-01-04,
01-02-04,
01-03-04,
01-04-04,
01-05-04,39
01-06-04,
01-07-04,
01-08-04,53
01-09-04,
01-10-04,
01-11-04,
01-12-04,
01-01-05,28
01-02-05,
01-03-05,
01-04-05,
01-05-05,
01-06-05,25
01-07-05,50
01-08-05,21
01-09-05,
01-10-05,
01-11-05,17
01-12-05,
01-01-06,16
01-02-06,14
01-03-06,21
01-04-06,
01-05-06,14
01-06-06,14
01-07-06,
01-08-06,
01-09-06,10
01-10-06,13
01-11-06,8
01-12-06,20
01-01-07,8
01-02-07,20
01-03-07,10
01-04-07,9
01-05-07,19
01-06-07,6
01-07-07,
01-08-07,11
01-09-07,17
01-10-07,12
01-11-07,13
01-12-07,17
01-01-08,11
01-02-08,8
01-03-08,9
01-04-08,21
01-05-08,8
01-06-08,8
01-07-08,14
01-08-08,14
01-09-08,19
01-10-08,27
01-11-08,7
01-12-08,16
01-01-09,25
01-02-09,17
01-03-09,9
01-04-09,14
01-05-09,14
01-06-09,3
01-07-09,14
01-08-09,5
01-09-09,8
01-10-09,13
01-11-09,10
01-12-09,10
01-01-10,8
01-02-10,12
01-03-10,12
01-04-10,15
01-05-10,13
01-06-10,5
01-07-10,6
01-08-10,7
01-09-10,13
01-10-10,19
01-11-10,19
01-12-10,13
01-01-11,11
01-02-11,11
01-03-11,15
01-04-11,9
01-05-11,14
01-06-11,7
01-07-11,9
01-08-11,11
01-09-11,24
01-10-11,14
01-11-11,17
01-12-11,14
01-01-12,10
01-02-12,13
01-03-12,12
01-04-12,12
01-05-12,12
01-06-12,9
01-07-12,7
01-08-12,9
01-09-12,15
01-10-12,13
01-11-12,25
01-12-12,13
01-01-13,13
01-02-13,15
01-03-13,23
01-04-13,22
01-05-13,14
01-06-13,13
01-07-13,20
01-08-13,17
01-09-13,27
01-10-13,15
01-11-13,16
01-12-13,18
01-01-14,18
01-02-14,19
01-03-14,14
01-04-14,14
01-05-14,10
01-06-14,11
01-07-14,8
01-08-14,18
01-09-14,16
01-10-14,26
01-11-14,35
01-12-14,15
01-01-15,14
01-02-15,16
01-03-15,13
01-04-15,12
01-05-15,12
01-06-15,9
01-07-15,10
01-08-15,11
01-09-15,11
01-10-15,13
01-11-15,13
01-12-15,10
01-01-16,12
01-02-16,12
01-03-16,13
01-04-16,13
01-05-16,12
01-06-16,7
01-07-16,6
01-08-16,13
01-09-16,15
01-10-16,13
01-11-16,12
01-12-16,14
01-01-17,11
01-02-17,11
01-03-17,10
01-04-17,11
01-05-17,7
01-06-17,8
01-07-17,10
01-08-17,12
01-09-17,13
01-10-17,14
01-11-17,15
01-12-17,13
01-01-18,13
01-02-18,16
01-03-18,12
01-04-18,14
01-05-18,12
01-06-18,8
01-07-18,8