Using Spark 1.5.1,
I've been trying to forward fill null values with the last known observation for one column of my DataFrame.
It is possible to start with a null value and for this case I would to backward fill this null value with the first knwn observation. However, If that too complicates the code, this point can be skipped.
In this post, a solution in Scala was provided for a very similar problem by zero323.
But, I don't know Scala and I don't succeed to ''translate'' it in Pyspark API code. It's possible to do it with Pyspark ?
Thanks for your help.
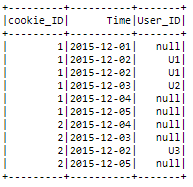
Below, a simple example sample input:
| cookie_ID | Time | User_ID
| ------------- | -------- |-------------
| 1 | 2015-12-01 | null
| 1 | 2015-12-02 | U1
| 1 | 2015-12-03 | U1
| 1 | 2015-12-04 | null
| 1 | 2015-12-05 | null
| 1 | 2015-12-06 | U2
| 1 | 2015-12-07 | null
| 1 | 2015-12-08 | U1
| 1 | 2015-12-09 | null
| 2 | 2015-12-03 | null
| 2 | 2015-12-04 | U3
| 2 | 2015-12-05 | null
| 2 | 2015-12-06 | U4
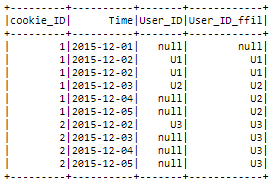
And the expected output:
| cookie_ID | Time | User_ID
| ------------- | -------- |-------------
| 1 | 2015-12-01 | U1
| 1 | 2015-12-02 | U1
| 1 | 2015-12-03 | U1
| 1 | 2015-12-04 | U1
| 1 | 2015-12-05 | U1
| 1 | 2015-12-06 | U2
| 1 | 2015-12-07 | U2
| 1 | 2015-12-08 | U1
| 1 | 2015-12-09 | U1
| 2 | 2015-12-03 | U3
| 2 | 2015-12-04 | U3
| 2 | 2015-12-05 | U3
| 2 | 2015-12-06 | U4