As per John Fouhy's answer, don't optimize unless you have to, but if you're here and asking this question, it may be precisely because you have to.
In my case, I needed to assemble some URLs from string variables... fast. I noticed no one (so far) seems to be considering the string format method, so I thought I'd try that and, mostly for mild interest, I thought I'd toss the string interpolation operator in there for good measure.
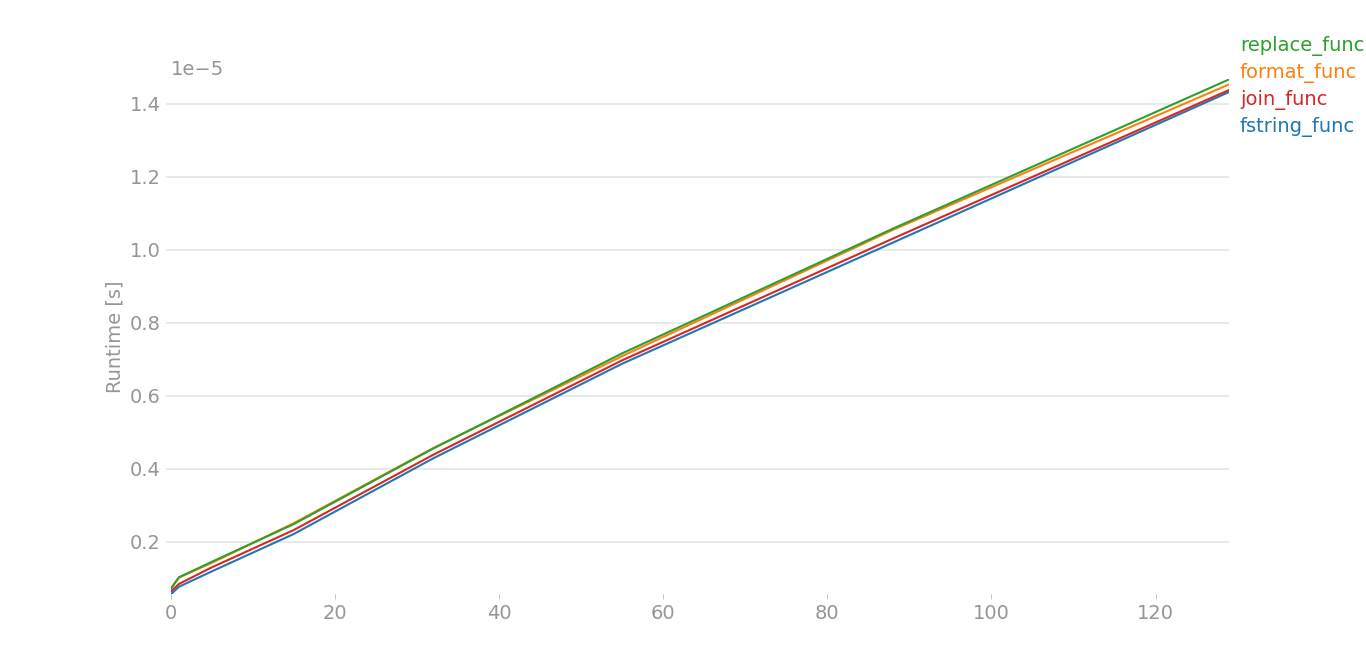
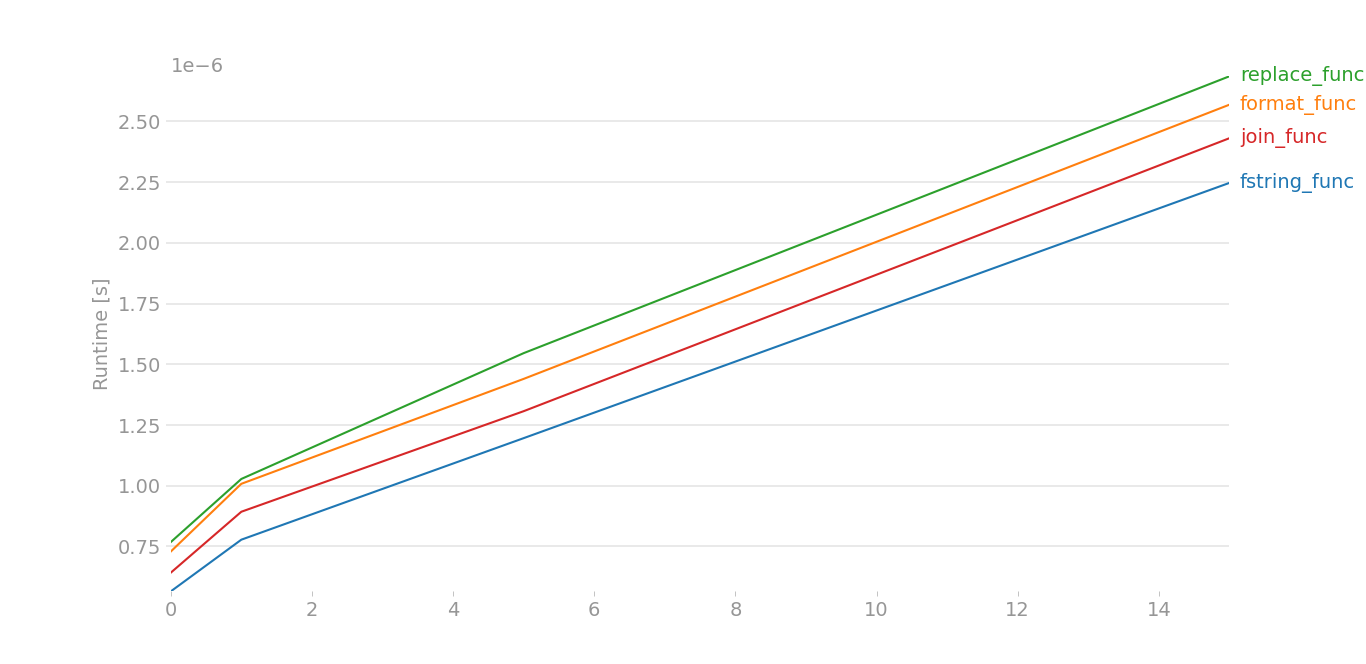
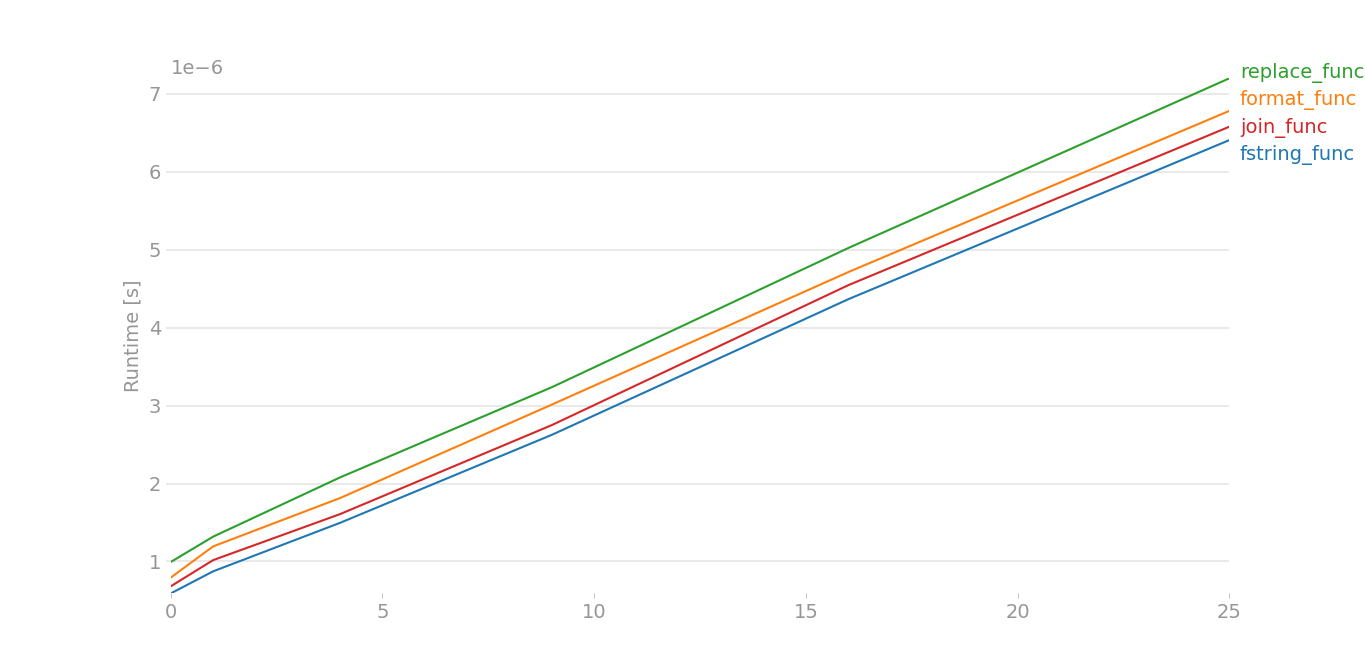
To be honest, I didn't think either of these would stack up to a direct '+' operation or a ''.join(). But guess what? On my Python 2.7.5 system, the string interpolation operator rules them all and string.format() is the worst performer:
# concatenate_test.py
from __future__ import print_function
import timeit
domain = 'some_really_long_example.com'
lang = 'en'
path = 'some/really/long/path/'
iterations = 1000000
def meth_plus():
'''Using + operator'''
return 'http://' + domain + '/' + lang + '/' + path
def meth_join():
'''Using ''.join()'''
return ''.join(['http://', domain, '/', lang, '/', path])
def meth_form():
'''Using string.format'''
return 'http://{0}/{1}/{2}'.format(domain, lang, path)
def meth_intp():
'''Using string interpolation'''
return 'http://%s/%s/%s' % (domain, lang, path)
plus = timeit.Timer(stmt="meth_plus()", setup="from __main__ import meth_plus")
join = timeit.Timer(stmt="meth_join()", setup="from __main__ import meth_join")
form = timeit.Timer(stmt="meth_form()", setup="from __main__ import meth_form")
intp = timeit.Timer(stmt="meth_intp()", setup="from __main__ import meth_intp")
plus.val = plus.timeit(iterations)
join.val = join.timeit(iterations)
form.val = form.timeit(iterations)
intp.val = intp.timeit(iterations)
min_val = min([plus.val, join.val, form.val, intp.val])
print('plus %0.12f (%0.2f%% as fast)' % (plus.val, (100 * min_val / plus.val), ))
print('join %0.12f (%0.2f%% as fast)' % (join.val, (100 * min_val / join.val), ))
print('form %0.12f (%0.2f%% as fast)' % (form.val, (100 * min_val / form.val), ))
print('intp %0.12f (%0.2f%% as fast)' % (intp.val, (100 * min_val / intp.val), ))
The results:
# Python 2.7 concatenate_test.py
plus 0.360787868500 (90.81% as fast)
join 0.452811956406 (72.36% as fast)
form 0.502608060837 (65.19% as fast)
intp 0.327636957169 (100.00% as fast)
If I use a shorter domain and shorter path, interpolation still wins out. The difference is more pronounced, though, with longer strings.
Now that I had a nice test script, I also tested under Python 2.6, 3.3 and 3.4, here's the results. In Python 2.6, the plus operator is the fastest! On Python 3, join wins out. Note: these tests are very repeatable on my system. So, 'plus' is always faster on 2.6, 'intp' is always faster on 2.7 and 'join' is always faster on Python 3.x.
# Python 2.6 concatenate_test.py
plus 0.338213920593 (100.00% as fast)
join 0.427221059799 (79.17% as fast)
form 0.515371084213 (65.63% as fast)
intp 0.378169059753 (89.43% as fast)
# Python 3.3 concatenate_test.py
plus 0.409130576998 (89.20% as fast)
join 0.364938726001 (100.00% as fast)
form 0.621366866995 (58.73% as fast)
intp 0.419064424001 (87.08% as fast)
# Python 3.4 concatenate_test.py
plus 0.481188605998 (85.14% as fast)
join 0.409673971997 (100.00% as fast)
form 0.652010936996 (62.83% as fast)
intp 0.460400978001 (88.98% as fast)
# Python 3.5 concatenate_test.py
plus 0.417167026084 (93.47% as fast)
join 0.389929617057 (100.00% as fast)
form 0.595661019906 (65.46% as fast)
intp 0.404455224983 (96.41% as fast)
Lesson learned:
- Sometimes, my assumptions are dead wrong.
- Test against the system environment. You'll be running in production.
- String interpolation isn't dead yet!
tl;dr:
- If you using Python 2.6, use the '+' operator.
- if you're using Python 2.7, use the '%' operator.
- if you're using Python 3.x, use ''.join().