I found this previous question on SO: N-grams: Explanation + 2 applications. The OP gave this example and asked if it was correct:
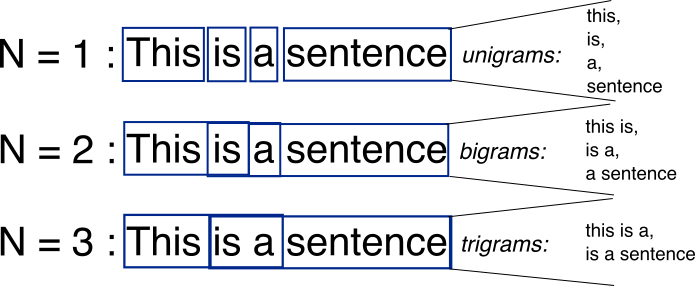
Sentence: "I live in NY."
word level bigrams (2 for n): "# I', "I live", "live in", "in NY", 'NY #'
character level bigrams (2 for n): "#I", "I#", "#l", "li", "iv", "ve", "e#", "#i", "in", "n#", "#N", "NY", "Y#"
When you have this array of n-gram-parts, you drop the duplicate ones and add a counter for each part giving the frequency:
word level bigrams: [1, 1, 1, 1, 1]
character level bigrams: [2, 1, 1, ...]
Someone in the answer section confirmed this was correct, but unfortunately I'm a bit lost beyond that as I didn't fully understand everything else that was said! I'm using LingPipe and following a tutorial which stated I should choose a value between 7 and 12 - but without stating why.
What is a good nGram value and how should I take it into account when using a tool like LingPipe?
Edit: This was the tutorial: http://cavajohn.blogspot.co.uk/2013/05/how-to-sentiment-analysis-of-tweets.html