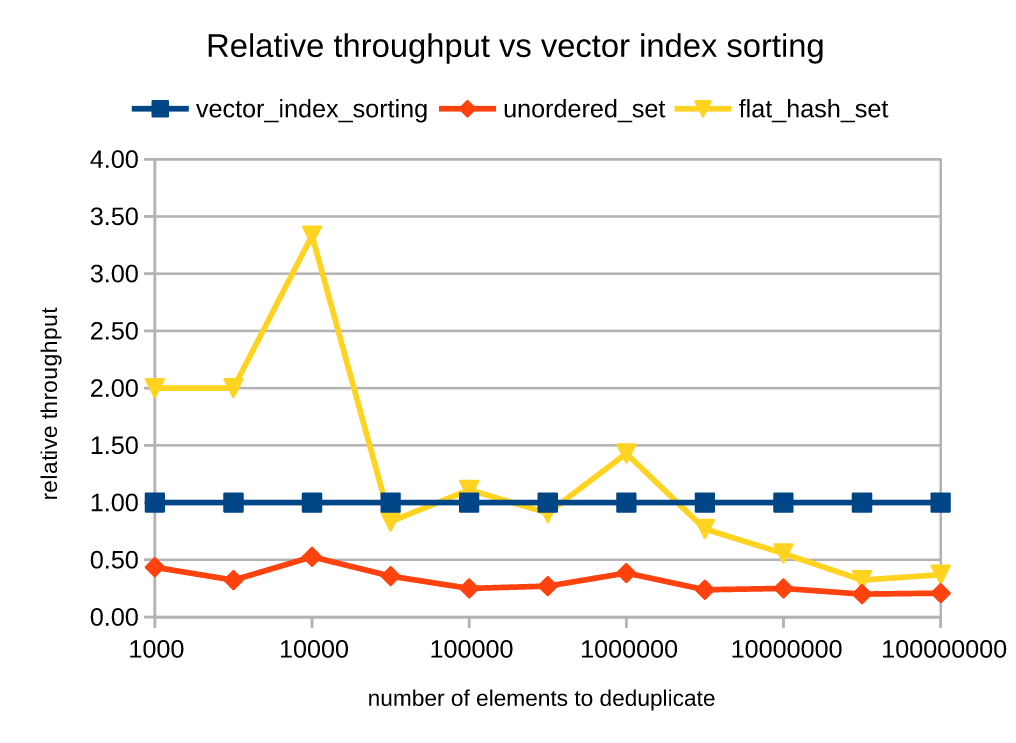
To verify the performance of the proposed solutions, I've tested three of them, listed below. The tests are using random vectors with 1 mln elements and different ratio of duplicates (0%, 1%, 2%, ..., 10%, ..., 90%, 100%).
Mehrdad's solution, currently the accepted answer:
void uniquifyWithOrder_sort(const vector<int>&, vector<int>& output)
{
using It = vector<int>::iterator;
struct target_less
{
bool operator()(It const &a, It const &b) const { return *a < *b; }
};
struct target_equal
{
bool operator()(It const &a, It const &b) const { return *a == *b; }
};
auto begin = output.begin();
auto const end = output.end();
{
vector<It> v;
v.reserve(static_cast<size_t>(distance(begin, end)));
for (auto i = begin; i != end; ++i)
{
v.push_back(i);
}
sort(v.begin(), v.end(), target_less());
v.erase(unique(v.begin(), v.end(), target_equal()), v.end());
sort(v.begin(), v.end());
size_t j = 0;
for (auto i = begin; i != end && j != v.size(); ++i)
{
if (i == v[j])
{
using std::iter_swap; iter_swap(i, begin);
++j;
++begin;
}
}
}
output.erase(begin, output.end());
}
juanchopanza's solution
void uniquifyWithOrder_set_copy_if(const vector<int>& input, vector<int>& output)
{
struct NotADuplicate
{
bool operator()(const int& element)
{
return _s.insert(element).second;
}
private:
set<int> _s;
};
vector<int> uniqueNumbers;
NotADuplicate pred;
output.clear();
output.reserve(input.size());
copy_if(
input.begin(),
input.end(),
back_inserter(output),
ref(pred));
}
Leviathan's solution
void uniquifyWithOrder_set_remove_if(const vector<int>& input, vector<int>& output)
{
set<int> seen;
auto newEnd = remove_if(output.begin(), output.end(), [&seen](const int& value)
{
if (seen.find(value) != end(seen))
return true;
seen.insert(value);
return false;
});
output.erase(newEnd, output.end());
}
They are slightly modified for simplicity, and to allow comparing in-place solutions with not in-place ones. The full code used to test is available here.
The results suggest that if you know you'll have at least 1% duplicates the remove_if solution with std::set is the best one. Otherwise, you should go with the sort solution:
// Intel(R) Core(TM) i7-2600 CPU @ 3.40 GHz 3.40 GHz
// 16 GB RAM, Windows 7, 64 bit
//
// cl 19
// /GS /GL /W3 /Gy /Zc:wchar_t /Zi /Gm- /O2 /Zc:inline /fp:precise /D "NDEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /WX- /Zc:forScope /Gd /Oi /MD /EHsc /nologo /Ot
//
// 1000 random vectors with 1 000 000 elements each.
// 11 tests: with 0%, 10%, 20%, ..., 90%, 100% duplicates in vectors.
// Ratio: 0
// set_copy_if : Time : 618.162 ms +- 18.7261 ms
// set_remove_if : Time : 650.453 ms +- 10.0107 ms
// sort : Time : 212.366 ms +- 5.27977 ms
// Ratio : 0.1
// set_copy_if : Time : 34.1907 ms +- 1.51335 ms
// set_remove_if : Time : 24.2709 ms +- 0.517165 ms
// sort : Time : 43.735 ms +- 1.44966 ms
// Ratio : 0.2
// set_copy_if : Time : 29.5399 ms +- 1.32403 ms
// set_remove_if : Time : 20.4138 ms +- 0.759438 ms
// sort : Time : 36.4204 ms +- 1.60568 ms
// Ratio : 0.3
// set_copy_if : Time : 32.0227 ms +- 1.25661 ms
// set_remove_if : Time : 22.3386 ms +- 0.950855 ms
// sort : Time : 38.1551 ms +- 1.12852 ms
// Ratio : 0.4
// set_copy_if : Time : 30.2714 ms +- 1.28494 ms
// set_remove_if : Time : 20.8338 ms +- 1.06292 ms
// sort : Time : 35.282 ms +- 2.12884 ms
// Ratio : 0.5
// set_copy_if : Time : 24.3247 ms +- 1.21664 ms
// set_remove_if : Time : 16.1621 ms +- 1.27802 ms
// sort : Time : 27.3166 ms +- 2.12964 ms
// Ratio : 0.6
// set_copy_if : Time : 27.3268 ms +- 1.06058 ms
// set_remove_if : Time : 18.4379 ms +- 1.1438 ms
// sort : Time : 30.6846 ms +- 2.52412 ms
// Ratio : 0.7
// set_copy_if : Time : 30.3871 ms +- 0.887492 ms
// set_remove_if : Time : 20.6315 ms +- 0.899802 ms
// sort : Time : 33.7643 ms +- 2.2336 ms
// Ratio : 0.8
// set_copy_if : Time : 33.3077 ms +- 0.746272 ms
// set_remove_if : Time : 22.9459 ms +- 0.921515 ms
// sort : Time : 37.119 ms +- 2.20924 ms
// Ratio : 0.9
// set_copy_if : Time : 36.0888 ms +- 0.763978 ms
// set_remove_if : Time : 24.7002 ms +- 0.465711 ms
// sort : Time : 40.8233 ms +- 2.59826 ms
// Ratio : 1
// set_copy_if : Time : 21.5609 ms +- 1.48986 ms
// set_remove_if : Time : 14.2934 ms +- 0.535431 ms
// sort : Time : 24.2485 ms +- 0.710269 ms
// Ratio: 0
// set_copy_if : Time: 666.962 ms +- 23.7445 ms
// set_remove_if : Time: 736.088 ms +- 39.8122 ms
// sort : Time: 223.796 ms +- 5.27345 ms
// Ratio: 0.01
// set_copy_if : Time: 60.4075 ms +- 3.4673 ms
// set_remove_if : Time: 43.3095 ms +- 1.31252 ms
// sort : Time: 70.7511 ms +- 2.27826 ms
// Ratio: 0.02
// set_copy_if : Time: 50.2605 ms +- 2.70371 ms
// set_remove_if : Time: 36.2877 ms +- 1.14266 ms
// sort : Time: 62.9786 ms +- 2.69163 ms
// Ratio: 0.03
// set_copy_if : Time: 46.9797 ms +- 2.43009 ms
// set_remove_if : Time: 34.0161 ms +- 0.839472 ms
// sort : Time: 59.5666 ms +- 1.34078 ms
// Ratio: 0.04
// set_copy_if : Time: 44.3423 ms +- 2.271 ms
// set_remove_if : Time: 32.2404 ms +- 1.02162 ms
// sort : Time: 57.0583 ms +- 2.9226 ms
// Ratio: 0.05
// set_copy_if : Time: 41.758 ms +- 2.57589 ms
// set_remove_if : Time: 29.9927 ms +- 0.935529 ms
// sort : Time: 54.1474 ms +- 1.63311 ms
// Ratio: 0.06
// set_copy_if : Time: 40.289 ms +- 1.85715 ms
// set_remove_if : Time: 29.2604 ms +- 0.593869 ms
// sort : Time: 57.5436 ms +- 5.52807 ms
// Ratio: 0.07
// set_copy_if : Time: 40.5035 ms +- 1.80952 ms
// set_remove_if : Time: 29.1187 ms +- 0.63127 ms
// sort : Time: 53.622 ms +- 1.91357 ms
// Ratio: 0.08
// set_copy_if : Time: 38.8139 ms +- 1.9811 ms
// set_remove_if : Time: 27.9989 ms +- 0.600543 ms
// sort : Time: 50.5743 ms +- 1.35296 ms
// Ratio: 0.09
// set_copy_if : Time: 39.0751 ms +- 1.71393 ms
// set_remove_if : Time: 28.2332 ms +- 0.607895 ms
// sort : Time: 51.2829 ms +- 1.21077 ms
// Ratio: 0.1
// set_copy_if : Time: 35.6847 ms +- 1.81495 ms
// set_remove_if : Time: 25.204 ms +- 0.538245 ms
// sort : Time: 46.4127 ms +- 2.66714 ms