There are many papers describing various advanced algorithms for set partitioning. Here are only two of them:
Honestly, I don't know which of them gives more efficient solution. Probably neither of these advanced algorithms are needed to solve that SPOJ problem. Korf's paper is still very useful. Algorithms described there are very simple (to understand and implement). Also he overviews several even simpler algorithms (in section 2). So if you want to know the details of Horowitz-Sahni or Schroeppel-Shamir methods (mentioned below), you can find them in Korf's paper. Also (in section 8) he writes that stochastic approaches do not guarantee good enough solutions. So it is unlikely you get significant improvements with something like hill climbing, simulated annealing, or tabu search.
I tried several simple algorithms and their combinations to solve partitioning problems with size up to 10000, maximum value up to 1014, and time limit 4 sec. They were tested on random uniformly distributed numbers. And optimal solution was found for every problem instance I tried. For some problem instances optimality is guaranteed by algorithm, for others optimality is not 100% guaranteed, but probability of getting sub-optimal solution is very small.
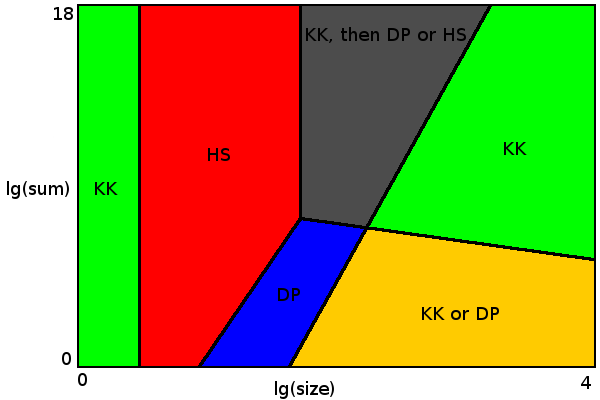
![problem space divided between algorithms]()
For sizes up to 4 (green area to the left) Karmarkar-Karp algorithm always gives optimal result.
For sizes up to 54 a brute force algorithm is fast enough (red area). There is a choice between Horowitz-Sahni or Schroeppel-Shamir algorithms. I used Horowitz-Sahni because it seems more efficient for given limits. Schroeppel-Shamir uses much less memory (everything fits in L2 cache), so it may be preferable when other CPU cores perform some memory-intensive tasks or to do set partitioning using multiple threads. Or to solve bigger problems with not as strict time limit (where Horowitz-Sahni just runs out of memory).
When size multiplied by sum of all values is less than 5*109 (blue area), dynamic programming approach is applicable. Border between brute force and dynamic programming areas on diagram shows where each algorithm performs better.
Green area to the right is the place where Karmarkar-Karp algorithm gives optimal result with almost 100% probability. Here there are so many perfect partitioning options (with delta 0 or 1) that Karmarkar-Karp algorithm almost certainly finds one of them. It is possible to invent data set where Karmarkar-Karp always gives sub-optimal result. For example {17 13 10 10 10 ...}. If you multiply this to some large number, neither KK nor DP would be able to find optimal solution. Fortunately such data sets are very unlikely in practice. But problem setter could add such data set to make contest more difficult. In this case you can choose some advanced algorithm for better results (but only for grey and right green areas on diagram).
I tried 2 ways to implement Karmarkar-Karp algorithm's priority queue: with max heap and with sorted array. Sorted array option appears to be slightly faster with linear search and significantly faster with binary search.
Yellow area is the place where you can choose between guaranteed optimal result (with DP) or just optimal result with high probability (with Karmarkar-Karp).
Finally, grey area, where neither of simple algorithms by itself gives optimal result. Here we could use Karmarkar-Karp to pre-process data until it is applicable to either Horowitz-Sahni or dynamic programming. In this place there are also many perfect partitioning options, but less than in green area, so Karmarkar-Karp by itself could sometimes miss proper partitioning. Update: As noted by @mhum, it is not necessary to implement dynamic programming algorithm to make things working. Horowitz-Sahni with Karmarkar-Karp pre-processing is enough. But it is essential for Horowitz-Sahni algorithm to work on sizes up to 54 in said time limit to (almost) guarantee optimal partitioning. So C++ or other language with good optimizing compiler and fast computer are preferable.
Here is how I combined Karmarkar-Karp with other algorithms:
template<bool Preprocess = false>
i64 kk(const vector<i64>& values, i64 sum, Log& log)
{
log.name("Karmarkar-Karp");
vector<i64> pq(values.size() * 2);
copy(begin(values), end(values), begin(pq) + values.size());
sort(begin(pq) + values.size(), end(pq));
auto first = end(pq);
auto last = begin(pq) + values.size();
while (first - last > 1)
{
if (Preprocess && first - last <= kHSLimit)
{
hs(last, first, sum, log);
return 0;
}
if (Preprocess && static_cast<double>(first - last) * sum <= kDPLimit)
{
dp(last, first, sum, log);
return 0;
}
const auto diff = *(first - 1) - *(first - 2);
sum -= *(first - 2) * 2;
first -= 2;
const auto place = lower_bound(last, first, diff);
--last;
copy(last + 1, place, last);
*(place - 1) = diff;
}
const auto result = (first - last)? *last: 0;
log(result);
return result;
}
Link to full C++11 implementation. This program only determines difference between partition sums, it does not report the partitions themselves. Warning: if you want to run it on a computer with less than 1 Gb free memory, decrease kHSLimit constant.
n(up to 40..50) use brute force algorithm, for largernswitch to Karmarkar-Karp. Also you could analyse input numbers' ranges, and if they are small, switch to DP. – Annabelannabela