I have a snippet of simple Java code:
public static void main(String[] args) {
String testStr = "test";
String rst = testStr + 1 + "a" + "pig" + 2;
System.out.println(rst);
}
Compile it with the Eclipse Java compiler, and examine the bytecode using AsmTools. It shows:
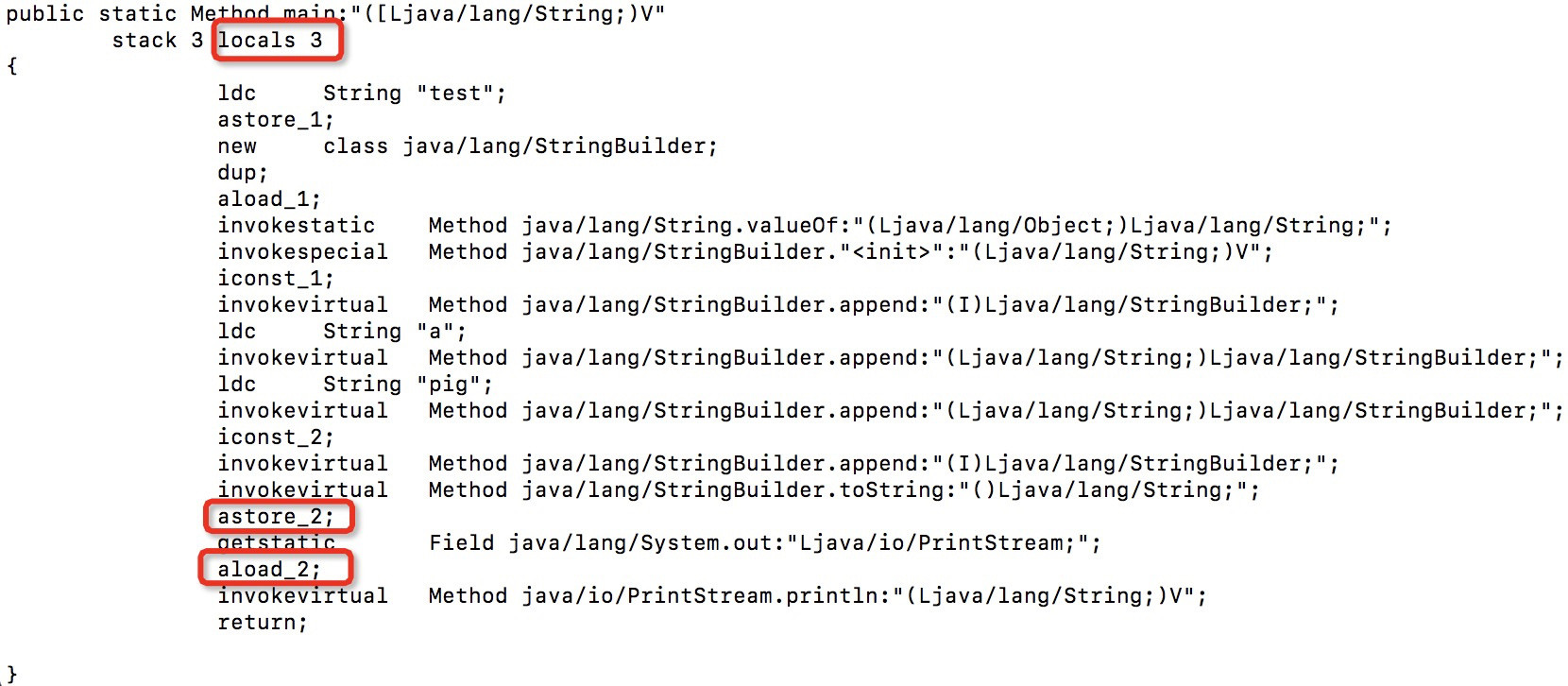
There are three local variables in the method. The argument is in slot 0, and slots 1 and 2 are supposedly used by the code. But I think 2 local variables are just enough — index 0 is the argument anyway, and the code needs only one more variable.
In order to see if my idea is correct, I edited the textual bytecode, reduced the number of local variables to 2, and adjusted some related instructions:
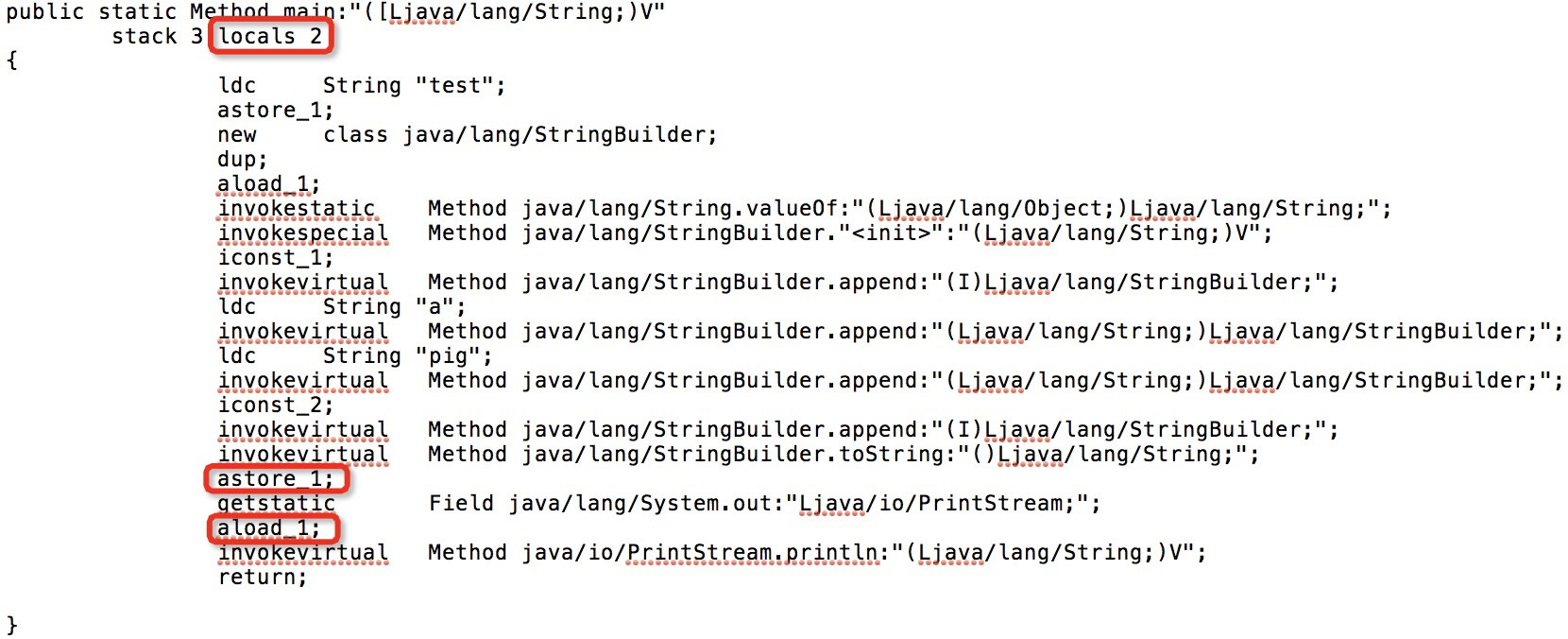
I recompiled it with AsmTools and it works fine!
So why don't Javac or the Eclipse compiler do this kind of optimization to use the minimal local variables?
finalit would have been less of everything. – Trifocals