We are in the process of migrating from MySQL to PGSQL and we have a 100 million row table.
When I was trying to ascertain how much space both systems use, I found much less difference for tables, but found huge differences for indexes.
MySQL indexes were occupying more size than the table data itself and postgres was using considerably lesser sizes.
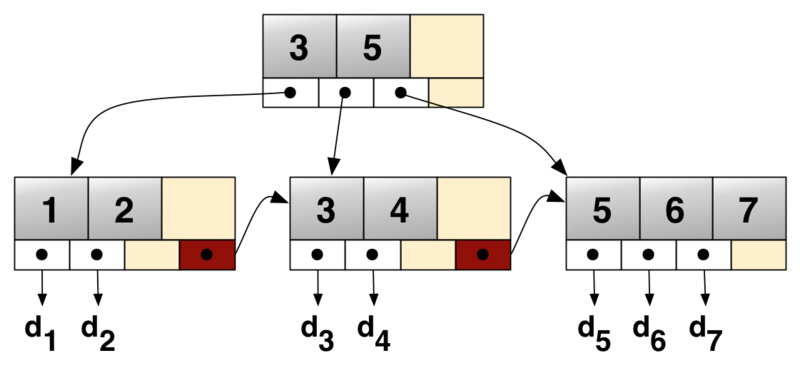
When digging through for the reason, I found that MySQL uses B+ trees to store the indexes and postgres uses B-trees.
MySQL usage of indexes was a little different, it stores the data along with the indexes (due to which the increased size), but postgres doesn't.
Now the questions:
Comparing B-tree and B+ trees on database speak, it is better to use B+trees since they are better for range queries O(m) + O(logN) - where m in the range and lookup is logarithmic in B+trees?
Now in B-trees the lookup is logarithmic for range queries it shoots up to O(N) since it does not have the linked list underlying structure for the data nodes. With that said, why does postgres uses B-trees? Does it perform well for range queries (it does, but how does it handle internally with B-trees)?
The above question is from a postgres point of view, but from a MySQL perspective, why does it use more storage than postgres, what is the performance benefit of using B+trees in reality?
I could have missed/misunderstood many things, so please feel free to correct my understanding here.
Edit for answering Rick James questions
- I am using InnoDB engine for MySQL
- I built the index after populating the data - same way I did in postgres
- The indexes are not UNIQUE indexes, just normal indexes
- There were no random inserts, I used csv loading in both postgres and MySQL and only after this I created the indexes.
- Postgres block size for both indexes and data is 8KB, I am not sure for MySQL, but I didn't change it, so it must be the defaults.
- I would not call the rows big, they have around 4 text fields with 200 characters long, 4 decimal fields and 2 bigint fields - 19 numbers long.
- The P.K is a bigint column with 19 numbers,I am not sure if this is bulky? On what scale should be differentiate bulky vs non-bulky?
- The MySQL table size was 600 MB and Postgres was around 310 MB both including indexes - this amounts to 48% bigger size if my math is right.But is there a way that I can measure the index size alone in MySQL excluding the table size? That can lead to better numbers I guess.
- Machine info : I had enough RAM - 256GB to fit all the tables and indexes together, but I don't think we need to traverse this route at all, I didn't see any noticeable performance difference in both of them.
Additional Questions
- When we say fragmentation occurs ? Is there a way to do de-fragmentation so that we can say that beyond this, there is nothing to be done.I am using Cent OS by the way.
- Is there a way to measure index size along in MySQL, ignoring the primary key as it is clustered, so that we can actually see what type is occupying more size if any.