Redux author here!
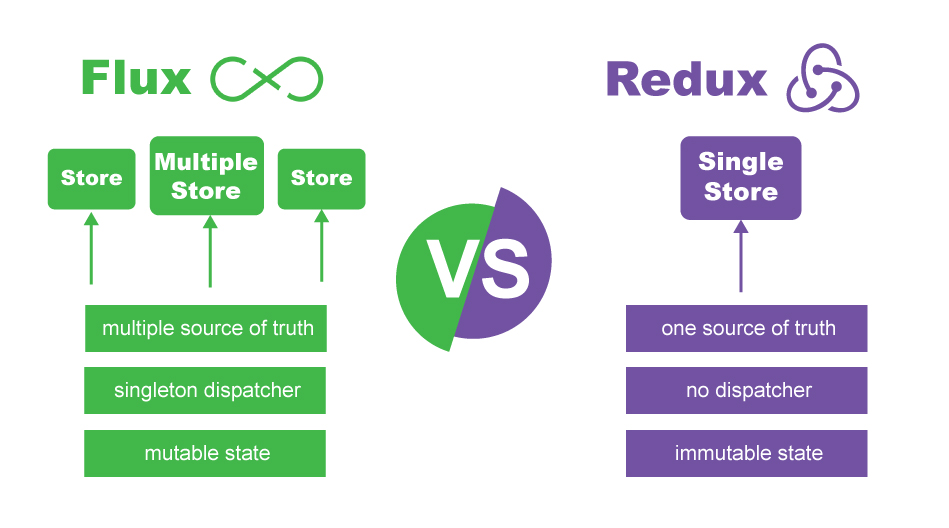
Redux is not that different from Flux. Overall it has same architecture, but Redux is able to cut some complexity corners by using functional composition where Flux uses callback registration.
There is not a fundamental difference in Redux, but I find it makes certain abstractions easier, or at least possible to implement, that would be hard or impossible to implement in Flux.
Reducer Composition
Take, for example, pagination. My Flux + React Router example handles pagination, but the code for that is awful. One of the reasons it's awful is that Flux makes it unnatural to reuse functionality across stores. If two stores need to handle pagination in response to different actions, they either need to inherit from a common base store (bad! you're locking yourself into a particular design when you use inheritance), or call an externally defined function from within the event handler, which will need to somehow operate on the Flux store's private state. The whole thing is messy (although definitely in the realm of possible).
On the other hand, with Redux pagination is natural thanks to reducer composition. It's reducers all the way down, so you can write a reducer factory that generates pagination reducers and then use it in your reducer tree. The key to why it's so easy is because in Flux, stores are flat, but in Redux, reducers can be nested via functional composition, just like React components can be nested.
This pattern also enables wonderful features like no-user-code undo/redo. Can you imagine plugging Undo/Redo into a Flux app being two lines of code? Hardly. With Redux, it is—again, thanks to reducer composition pattern. I need to highlight there's nothing new about it—this is the pattern pioneered and described in detail in Elm Architecture which was itself influenced by Flux.
Server Rendering
People have been rendering on the server fine with Flux, but seeing that we have 20 Flux libraries each attempting to make server rendering “easier”, perhaps Flux has some rough edges on the server. The truth is Facebook doesn't do much server rendering, so they haven't been very concerned about it, and rely on the ecosystem to make it easier.
In traditional Flux, stores are singletons. This means it's hard to separate the data for different requests on the server. Not impossible, but hard. This is why most Flux libraries (as well as the new Flux Utils) now suggest you use classes instead of singletons, so you can instantiate stores per request.
There are still the following problems that you need to solve in Flux (either yourself or with the help of your favorite Flux library such as Flummox or Alt):
- If stores are classes, how do I create and destroy them with dispatcher per request? When do I register stores?
- How do I hydrate the data from the stores and later rehydrate it on the client? Do I need to implement special methods for this?
Admittedly Flux frameworks (not vanilla Flux) have solutions to these problems, but I find them overcomplicated. For example, Flummox asks you to implement serialize() and deserialize() in your stores. Alt solves this nicer by providing takeSnapshot() that automatically serializes your state in a JSON tree.
Redux just goes further: since there is just a single store (managed by many reducers), you don't need any special API to manage the (re)hydration. You don't need to “flush” or “hydrate” stores—there's just a single store, and you can read its current state, or create a new store with a new state. Each request gets a separate store instance. Read more about server rendering with Redux.
Again, this is a case of something possible both in Flux and Redux, but Flux libraries solve this problem by introducing a ton of API and conventions, and Redux doesn't even have to solve it because it doesn't have that problem in the first place thanks to conceptual simplicity.
Developer Experience
I didn't actually intend Redux to become a popular Flux library—I wrote it as I was working on my ReactEurope talk on hot reloading with time travel. I had one main objective: make it possible to change reducer code on the fly or even “change the past” by crossing out actions, and see the state being recalculated.
![]()
I haven't seen a single Flux library that is able to do this. React Hot Loader also doesn't let you do this—in fact it breaks if you edit Flux stores because it doesn't know what to do with them.
When Redux needs to reload the reducer code, it calls replaceReducer(), and the app runs with the new code. In Flux, data and functions are entangled in Flux stores, so you can't “just replace the functions”. Moreover, you'd have to somehow re-register the new versions with the Dispatcher—something Redux doesn't even have.
Ecosystem
Redux has a rich and fast-growing ecosystem. This is because it provides a few extension points such as middleware. It was designed with use cases such as logging, support for Promises, Observables, routing, immutability dev checks, persistence, etc, in mind. Not all of these will turn out to be useful, but it's nice to have access to a set of tools that can be easily combined to work together.
Simplicity
Redux preserves all the benefits of Flux (recording and replaying of actions, unidirectional data flow, dependent mutations) and adds new benefits (easy undo-redo, hot reloading) without introducing Dispatcher and store registration.
Keeping it simple is important because it keeps you sane while you implement higher-level abstractions.
Unlike most Flux libraries, Redux API surface is tiny. If you remove the developer warnings, comments, and sanity checks, it's 99 lines. There is no tricky async code to debug.
You can actually read it and understand all of Redux.
See also my answer on downsides of using Redux compared to Flux.