Python is an interpreted language. But why does my source directory contain .pyc files, which are identified by Windows as "Compiled Python Files"?
If Python is interpreted, what are .pyc files?
Asked Answered
They contain byte code, which is what the Python interpreter compiles the source to. This code is then executed by Python's virtual machine.
Python's documentation explains the definition like this:
Python is an interpreted language, as opposed to a compiled one, though the distinction can be blurry because of the presence of the bytecode compiler. This means that source files can be run directly without explicitly creating an executable which is then run.
Interesting, thanks. So is Python considered a purely interpreted language? –
Pratt
@froadie: a language is not "interpreted" or "compiled" as such. A specific implementation can be an interpreter or a compiler (or a hybrid or a JIT compiler). –
Sparing
One test of 'compiled': is it compiled to actual machine instructions? Python bytecode are not machine instructions, and neither are Java 'JVM' instructions, so neither of these languages are compiled by that definition. But both 'compiled' to an intermediate 'abstract machine' code, and both are far, faster than running the program by more or less directly interpreting the source code (which is what old-school BASIC does). –
Cristen
To be pedantic, 'compiled' means 'translated'. Python is then compiled to a bytecode. AFAIK, only Bash is really interpreted , all other popular "interpreted" languages are all compiled to a bytecode. –
Rausch
Actually, they are machine instructions, just not native machine instructions for the host's physical CPU. Hence why we call it a VM ? Like Esperanto for assembly language really. Nowadays we even have native code for fictional (but still emulated) CPU's (Mojang's effort to get the kiddies interested). Rexx was (or could be) truly interpreted, and BAT and CMD (and DCL) are interpreted. –
Starfish
I am lookin at some python sources, and I see
file.py and file.pyc and file.pyo. I need to do a quick fix without debugging. Can I just change file.py, or I need to "compile" and regenerate all? –
Pastime @Danijel: when importing a module, python automatically detects if the .py file has been modified and automatically recompile a new .pyc/.pyo as necessary. In most cases, you would never need to worry about the managing the .pyc/.pyo files. –
Cooley
@Lordan - So if I have a git repository of Python files, I should ignore all *.pyc files (no need to keep them) , or shell it be more "efficient" to keep them around ? –
Ygerne
@GuyAvraham: Typically you want to add a line to your
.gitignore to prevent it from tracking *.py[co] (and git rm any you've already committed so they don't appear if someone else clones it). The cost of tracking them in git far exceeds the benefits. The cost of compiling from source to bytecode, including all the disk I/O, is typically in the single digit millisecond range (a test of calling py_compile.compile on Python's built-in _collections_abc.py outputting to a junk file took about 8 ms for a 26 KB file). Paying that cost for a few dozen files once after cloning is trivial. –
Borgia @Cristen Nuitka can compile the entirety Python to machine code via machine-dependent C++, and Cython can similarly compile Python to portable C code. –
Photostat
@GuyAvraham more important than efficiency (.pyc files generally take milliseconds to generate), you don't want to put a file into source control which is built directly from another file or files, which are also in source control. Because such a file is not "source". Specific issues (a) how will you make sure it's always consistent with .py (b) the format of .pyc depends on the python release you're using (c) Whenever you merge changes from two different branches to a .py, git will want to you manually resolve the conflict on the binary .pyc file. –
Cristen
@bfontaine, does that mean that all python
*.py code is first "translated" to the *.pyc byte code and then interpreted (run to do its job)? –
Hessney @Hessney Yes, although that
*.pyc file is not always written to disk. –
Rausch @Rausch
.py is compiled and/or loaded when PVM encounters import(not "all .py codes first are translated to .pyc"). –
Koontz I've been given to understand that Python is an interpreted language...
This popular meme is incorrect, or, rather, constructed upon a misunderstanding of (natural) language levels: a similar mistake would be to say "the Bible is a hardcover book". Let me explain that simile...
"The Bible" is "a book" in the sense of being a class of (actual, physical objects identified as) books; the books identified as "copies of the Bible" are supposed to have something fundamental in common (the contents, although even those can be in different languages, with different acceptable translations, levels of footnotes and other annotations) -- however, those books are perfectly well allowed to differ in a myriad of aspects that are not considered fundamental -- kind of binding, color of binding, font(s) used in the printing, illustrations if any, wide writable margins or not, numbers and kinds of builtin bookmarks, and so on, and so forth.
It's quite possible that a typical printing of the Bible would indeed be in hardcover binding -- after all, it's a book that's typically meant to be read over and over, bookmarked at several places, thumbed through looking for given chapter-and-verse pointers, etc, etc, and a good hardcover binding can make a given copy last longer under such use. However, these are mundane (practical) issues that cannot be used to determine whether a given actual book object is a copy of the Bible or not: paperback printings are perfectly possible!
Similarly, Python is "a language" in the sense of defining a class of language implementations which must all be similar in some fundamental respects (syntax, most semantics except those parts of those where they're explicitly allowed to differ) but are fully allowed to differ in just about every "implementation" detail -- including how they deal with the source files they're given, whether they compile the sources to some lower level forms (and, if so, which form -- and whether they save such compiled forms, to disk or elsewhere), how they execute said forms, and so forth.
The classical implementation, CPython, is often called just "Python" for short -- but it's just one of several production-quality implementations, side by side with Microsoft's IronPython (which compiles to CLR codes, i.e., ".NET"), Jython (which compiles to JVM codes), PyPy (which is written in Python itself and can compile to a huge variety of "back-end" forms including "just-in-time" generated machine language). They're all Python (=="implementations of the Python language") just like many superficially different book objects can all be Bibles (=="copies of The Bible").
If you're interested in CPython specifically: it compiles the source files into a Python-specific lower-level form (known as "bytecode"), does so automatically when needed (when there is no bytecode file corresponding to a source file, or the bytecode file is older than the source or compiled by a different Python version), usually saves the bytecode files to disk (to avoid recompiling them in the future). OTOH IronPython will typically compile to CLR codes (saving them to disk or not, depending) and Jython to JVM codes (saving them to disk or not -- it will use the .class extension if it does save them).
These lower level forms are then executed by appropriate "virtual machines" also known as "interpreters" -- the CPython VM, the .Net runtime, the Java VM (aka JVM), as appropriate.
So, in this sense (what do typical implementations do), Python is an "interpreted language" if and only if C# and Java are: all of them have a typical implementation strategy of producing bytecode first, then executing it via a VM/interpreter.
More likely the focus is on how "heavy", slow, and high-ceremony the compilation process is. CPython is designed to compile as fast as possible, as lightweight as possible, with as little ceremony as feasible -- the compiler does very little error checking and optimization, so it can run fast and in small amounts of memory, which in turns lets it be run automatically and transparently whenever needed, without the user even needing to be aware that there is a compilation going on, most of the time. Java and C# typically accept more work during compilation (and therefore don't perform automatic compilation) in order to check errors more thoroughly and perform more optimizations. It's a continuum of gray scales, not a black or white situation, and it would be utterly arbitrary to put a threshold at some given level and say that only above that level you call it "compilation"!-)
Beautiful answer. Just a small correction to the last paragraph: Python is designed to compile as fast as possible (etc.). This time it really is the language, with its lack of static type system and stuff. When people talk about "interpreted" languages, they usually mean "dynamic" languages. –
Twigg
@Elazar, actually, other implementations of Python, such as PyPy, which are in no hurry to compile, manage to do the more thorough analysis required by the lack of static typing and produce just-in-time compilation to machine code (thus speeding up long-running programs by many times). –
Sonority
Where does Cython fit in here? Would you consider it a different language or is it a Python implementation? Also, is this meme of "interpreted" vs compiled perhaps just a terminology confusion because Python's VM is often referred to as its "interpreter"? It would be just as valid to call the JVM or the .NET runtime interpreters. They both mostly interpret bytecode into JIT machine code (with some caching optimization exceptions) –
Albumen
Great answer, but I think the last paragraph could do a better job of emphasizing the main reason why Python is commonly considered an "interpreted" language: it's about the user (developer) experience - no separate build step. You execute your source code file(s) (with the Python executable as the interpreter) and immediately have a process doing what your source code says to do. And this is the default behavior - the normal or even standard behavior for Python implementations. You do vaguely gesture at this with "ceremony", but only vaguely while talking about the "work" aspect. –
Caltanissetta
They contain byte code, which is what the Python interpreter compiles the source to. This code is then executed by Python's virtual machine.
Python's documentation explains the definition like this:
Python is an interpreted language, as opposed to a compiled one, though the distinction can be blurry because of the presence of the bytecode compiler. This means that source files can be run directly without explicitly creating an executable which is then run.
Interesting, thanks. So is Python considered a purely interpreted language? –
Pratt
@froadie: a language is not "interpreted" or "compiled" as such. A specific implementation can be an interpreter or a compiler (or a hybrid or a JIT compiler). –
Sparing
One test of 'compiled': is it compiled to actual machine instructions? Python bytecode are not machine instructions, and neither are Java 'JVM' instructions, so neither of these languages are compiled by that definition. But both 'compiled' to an intermediate 'abstract machine' code, and both are far, faster than running the program by more or less directly interpreting the source code (which is what old-school BASIC does). –
Cristen
To be pedantic, 'compiled' means 'translated'. Python is then compiled to a bytecode. AFAIK, only Bash is really interpreted , all other popular "interpreted" languages are all compiled to a bytecode. –
Rausch
Actually, they are machine instructions, just not native machine instructions for the host's physical CPU. Hence why we call it a VM ? Like Esperanto for assembly language really. Nowadays we even have native code for fictional (but still emulated) CPU's (Mojang's effort to get the kiddies interested). Rexx was (or could be) truly interpreted, and BAT and CMD (and DCL) are interpreted. –
Starfish
I am lookin at some python sources, and I see
file.py and file.pyc and file.pyo. I need to do a quick fix without debugging. Can I just change file.py, or I need to "compile" and regenerate all? –
Pastime @Danijel: when importing a module, python automatically detects if the .py file has been modified and automatically recompile a new .pyc/.pyo as necessary. In most cases, you would never need to worry about the managing the .pyc/.pyo files. –
Cooley
@Lordan - So if I have a git repository of Python files, I should ignore all *.pyc files (no need to keep them) , or shell it be more "efficient" to keep them around ? –
Ygerne
@GuyAvraham: Typically you want to add a line to your
.gitignore to prevent it from tracking *.py[co] (and git rm any you've already committed so they don't appear if someone else clones it). The cost of tracking them in git far exceeds the benefits. The cost of compiling from source to bytecode, including all the disk I/O, is typically in the single digit millisecond range (a test of calling py_compile.compile on Python's built-in _collections_abc.py outputting to a junk file took about 8 ms for a 26 KB file). Paying that cost for a few dozen files once after cloning is trivial. –
Borgia @Cristen Nuitka can compile the entirety Python to machine code via machine-dependent C++, and Cython can similarly compile Python to portable C code. –
Photostat
@GuyAvraham more important than efficiency (.pyc files generally take milliseconds to generate), you don't want to put a file into source control which is built directly from another file or files, which are also in source control. Because such a file is not "source". Specific issues (a) how will you make sure it's always consistent with .py (b) the format of .pyc depends on the python release you're using (c) Whenever you merge changes from two different branches to a .py, git will want to you manually resolve the conflict on the binary .pyc file. –
Cristen
@bfontaine, does that mean that all python
*.py code is first "translated" to the *.pyc byte code and then interpreted (run to do its job)? –
Hessney @Hessney Yes, although that
*.pyc file is not always written to disk. –
Rausch @Rausch
.py is compiled and/or loaded when PVM encounters import(not "all .py codes first are translated to .pyc"). –
Koontz There is no such thing as an interpreted language. Whether an interpreter or a compiler is used is purely a trait of the implementation and has absolutely nothing whatsoever to do with the language.
Every language can be implemented by either an interpreter or a compiler. The vast majority of languages have at least one implementation of each type. (For example, there are interpreters for C and C++ and there are compilers for JavaScript, PHP, Perl, Python and Ruby.) Besides, the majority of modern language implementations actually combine both an interpreter and a compiler (or even multiple compilers).
A language is just a set of abstract mathematical rules. An interpreter is one of several concrete implementation strategies for a language. Those two live on completely different abstraction levels. If English were a typed language, the term "interpreted language" would be a type error. The statement "Python is an interpreted language" is not just false (because being false would imply that the statement even makes sense, even if it is wrong), it just plain doesn't make sense, because a language can never be defined as "interpreted."
In particular, if you look at the currently existing Python implementations, these are the implementation strategies they are using:
- IronPython: compiles to DLR trees which the DLR then compiles to CIL bytecode. What happens to the CIL bytecode depends upon which CLI VES you are running on, but Microsoft .NET, GNU Portable.NET and Novell Mono will eventually compile it to native machine code.
- Jython: interprets Python sourcecode until it identifies the hot code paths, which it then compiles to JVML bytecode. What happens to the JVML bytecode depends upon which JVM you are running on. Maxine will directly compile it to un-optimized native code until it identifies the hot code paths, which it then recompiles to optimized native code. HotSpot will first interpret the JVML bytecode and then eventually compile the hot code paths to optimized machine code.
- PyPy: compiles to PyPy bytecode, which then gets interpreted by the PyPy VM until it identifies the hot code paths which it then compiles into native code, JVML bytecode or CIL bytecode depending on which platform you are running on.
- CPython: compiles to CPython bytecode which it then interprets.
- Stackless Python: compiles to CPython bytecode which it then interprets.
- Unladen Swallow: compiles to CPython bytecode which it then interprets until it identifies the hot code paths which it then compiles to LLVM IR which the LLVM compiler then compiles to native machine code.
- Cython: compiles Python code to portable C code, which is then compiled with a standard C compiler
- Nuitka: compiles Python code to machine-dependent C++ code, which is then compiled with a standard C compiler
You might notice that every single one of the implementations in that list (plus some others I didn't mention, like tinypy, Shedskin or Psyco) has a compiler. In fact, as far as I know, there is currently no Python implementation which is purely interpreted, there is no such implementation planned and there never has been such an implementation.
Not only does the term "interpreted language" not make sense, even if you interpret it as meaning "language with interpreted implementation", it is clearly not true. Whoever told you that, obviously doesn't know what he is talking about.
In particular, the .pyc files you are seeing are cached bytecode files produced by CPython, Stackless Python or Unladen Swallow.
Old-school basic such as MSBASIC had no intermediate form. The program was interpreted directly from the source form (or near source, a form in which keywords were represented by 1-byte tokens, and line #'s by 2-byte binary ints, but the rest was just ASCII). So in fact a 'goto' would take different amounts of time depending on how many source lines it had to search through looking for the matching destination. Expressions like a*b-2*cos(x) were effectively re-parsed every time they were executed. –
Cristen
@greggo: And if you want to go even more old-school, the original version of BASIC was a native code compiler. This should prove how ridiculous the notion of a "compiled" or "interpreted" language is. –
Johnajohnath
Thanks for explaining how the various python compilers/interpreters behave. I wonder if there are good Python compilers that generate efficient C or JavaScript yet. It seems very doable, maybe not for mass consumption, but for a reasonable subset of Python at least. Also I wonder what Cython is. –
Amaurosis
Cython was mentioned in SciPy 2009, but I can forgive you for not knowing about it back in 2010 (here I am in 2017 only just now learning about it). Still we ought to find a JavaScript example... Jython makes no sense to me (wasn't Java already dead by 2009? Well hmm, maybe not... C++ boost wasn't so good back then) –
Amaurosis
@personal_cloud: I don't quite follow your comment. Yes, of course, I know about Cython, but what does that have to do with anything? It's not an implementation of Python, it is a completely different language. Also, it's really not hard to find a JavaScript example, in fact, all currently existing mainstream JavaScript implementations have compilers. Lastly, Jython is an implementation of Python just like any other implementation of Python. And it is an implementation of a language on the Java platform just like any other language implementation on the Java platform. –
Johnajohnath
The Cython page describes it as
a superset of the Python language that additionally supports calling C functions and declaring C types on variables and class attributes . Syntactically it might be considered "python plus extras", does having extra features make it not a Python implementation? Does compiling to C make it different? Based on your clarification that languages are not defined by their route taken on their eventual & inevitable path to native binary executable code, then it can't be that. Great answer btw, made me reflect a lot. –
Albumen @Davos: The documentation for the current official release says (bold emphasis mine): "It aims to become a superset of the [Python] language" and "Cython can compile (most) regular Python code", so apparently, it is not a superset, and thus not an implementation of Python. Of course, it if it can compile all Python code, and follows the Python Language Specification, then it is a Python implementation, just like every JavaScript implementation is also at the same time an ECMAScript implementation. –
Johnajohnath
@JörgWMittag: Thank you very much for the great answer. So, is it a right statement to say that any implementation which interpreting the high level language instructions to machine level instructions (statement by statement) would be purely interpreted only, and rest of the implementations where byte code etc. (as intermediate step) is generated would not be considered purely interpreted implementation? –
Hickory
WRONG: "Every language can be implemented by either an interpreter or a compiler." - every language with an "eval()" statement BY DEFINITION requires it to always be interpreted. Like Python and Perl for example. –
Equinoctial
@AnonCoward: There is a question on Stack Overflow which asks about
pyc files, which are compiled Python byte code files. The fact that these compiled Python byte code files exist, proves beyond any doubt that Python can be compiled. Lisp is the original language which had EVAL, and Lisps have been compiled for over 50 years. Ruby has eval, and every single Ruby implementation in existence has a compiler. ECMAScript has eval, and every single ECMAScript implementation in existence has a compiler. As does every single Python implementation. –
Johnajohnath @Jorg - maybe read up on what a compiler is? Converting something to bytecode is not "compiling" it, and in every case you mention, the entire interpreter is included or required to run the NOT COMPILED code that's inside the eval. Do you need to install your entire C++ build chain to run compiled C code? No. do you need to install your entire Python/Ruby/ECMAScrpit/Perl build chain to run any of that code (bytecode or otherwise)? YES you do. –
Equinoctial
@AnonCoward: A compiler is a program which translates a program from language A to language B. The CPython compiler translates programs from Python to CPython bytecode, therefore, it is a compiler. And CPython does not include an interpreter for Python. It includes an interpreter for CPython byte code, which is a different language. Note that compiling a C program to native code and then executing it, still requires an interpreter for native code, sometimes called a "CPU". –
Johnajohnath
So IronPython programs can become a metro system? –
Hordein
These are created by the Python interpreter when a .py file is imported, and they contain the "compiled bytecode" of the imported module/program, the idea being that the "translation" from source code to bytecode (which only needs to be done once) can be skipped on subsequent imports if the .pyc is newer than the corresponding .py file, thus speeding startup a little. But it's still interpreted.
True. Except many core Python libraries are written in C. So parts of python run interpreted, part run in C. You can do the same to your own performance sensitive bits of code. –
Bushweller
Then why it is common practice to execute a *.py file? Won't *.pyc execution will be faster than that? –
Biparous
@Ankur: If there is a current *.pyc file, it will be executed. If not, the *.py file will be compiled, and then the compiled version will be executed. So if you already have a current *.pyc file, invoking the *.py file only takes a tiny bit longer - just how long it takes to compare two files' timestamps. –
Cloe
To speed up loading modules, Python caches the compiled content of modules in .pyc.
CPython compiles its source code into "byte code", and for performance reasons, it caches this byte code on the file system whenever the source file has changes. This makes loading of Python modules much faster because the compilation phase can be bypassed. When your source file is foo.py , CPython caches the byte code in a foo.pyc file right next to the source.
In python3, Python's import machinery is extended to write and search for byte code cache files in a single directory inside every Python package directory. This directory will be called __pycache__ .
Here is a flow chart describing how modules are loaded:
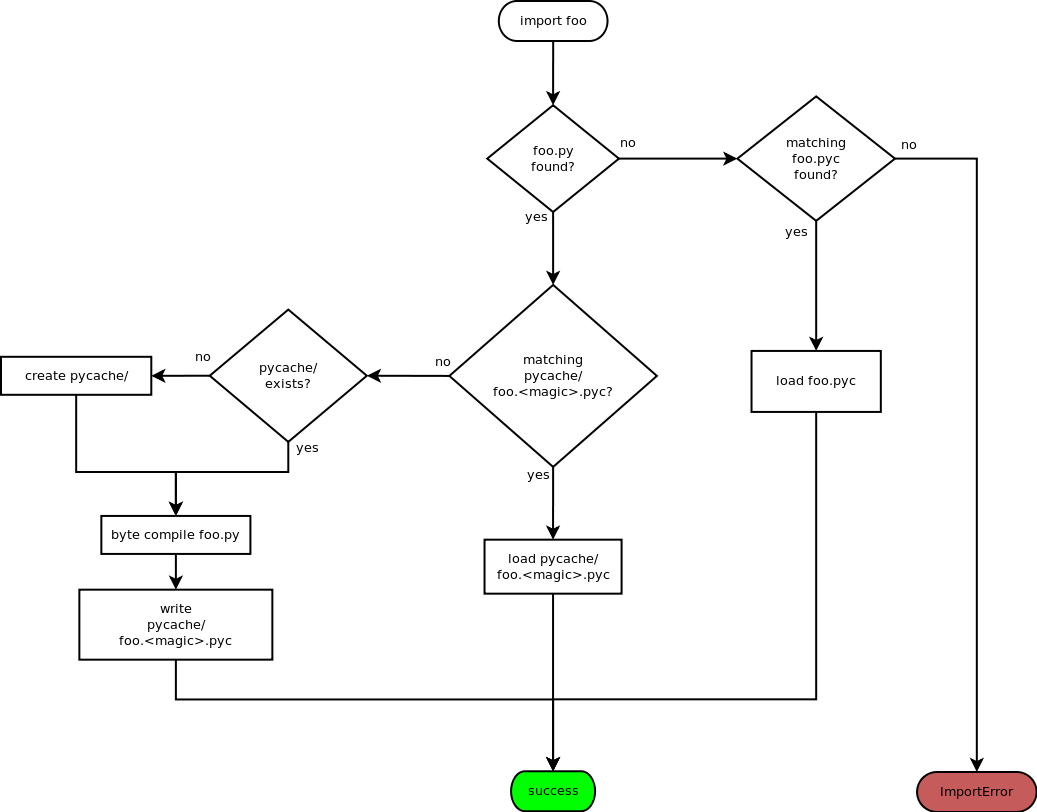
For more information:
ref:PEP3147
ref:“Compiled” Python files
once foo.py is compiled in pyc and after that, some changes are done in foo.py, how python is handling to recompile it? –
Sava
Python checks to see if the .pyc file's internal timestamp is not older than the corresponding .py file. @KaushalPrajapati –
Hyperkinesia
THIS IS FOR BEGINNERS,
Python automatically compiles your script to compiled code, so called byte code, before running it.
Running a script is not considered an import and no .pyc will be created.
For example, if you have a script file abc.py that imports another module xyz.py, when you run abc.py, xyz.pyc will be created since xyz is imported, but no abc.pyc file will be created since abc.py isn’t being imported.
If you need to create a .pyc file for a module that is not imported, you can use the py_compile and compileall modules.
The py_compile module can manually compile any module. One way is to use the py_compile.compile function in that module interactively:
>>> import py_compile
>>> py_compile.compile('abc.py')
This will write the .pyc to the same location as abc.py (you can override that with the optional parameter cfile).
You can also automatically compile all files in a directory or directories using the compileall module.
python -m compileall
If the directory name (the current directory in this example) is omitted, the module compiles everything found on sys.path
and what is the benefit of compiling to get the abc.py? –
Capacitor
@SaherAhwal One benefit I can think of is syntax checking. –
Temporize
Python (at least the most common implementation of it) follows a pattern of compiling the original source to byte codes, then interpreting the byte codes on a virtual machine. This means (again, the most common implementation) is neither a pure interpreter nor a pure compiler.
The other side of this is, however, that the compilation process is mostly hidden -- the .pyc files are basically treated like a cache; they speed things up, but you normally don't have to be aware of them at all. It automatically invalidates and re-loads them (re-compiles the source code) when necessary based on file time/date stamps.
About the only time I've seen a problem with this was when a compiled bytecode file somehow got a timestamp well into the future, which meant it always looked newer than the source file. Since it looked newer, the source file was never recompiled, so no matter what changes you made, they were ignored...
Python's *.py file is just a text file in which you write some lines of code. When you try to execute this file using say "python filename.py"
This command invokes Python Virtual Machine. Python Virtual Machine has 2 components: "compiler" and "interpreter". Interpreter cannot directly read the text in *.py file, so this text is first converted into a byte code which is targeted to the PVM (not hardware but PVM). PVM executes this byte code. *.pyc file is also generated, as part of running it which performs your import operation on file in shell or in some other file.
If this *.pyc file is already generated then every next time you run/execute your *.py file, system directly loads your *.pyc file which won't need any compilation(This will save you some machine cycles of processor).
Once the *.pyc file is generated, there is no need of *.py file, unless you edit it.
tldr; it's a converted code from the source code, which the python VM interprets for execution.
Bottom-up understanding: the final stage of any program is to run/execute the program's instructions on the hardware/machine. So here are the stages preceding execution:
Executing/running on CPU
Converting bytecode to machine code.
Machine code is the final stage of conversion.
Instructions to be executed on CPU are given in machine code. Machine code can be executed directly by CPU.
Converting Bytecode to machine code.
- Bytecode is a medium stage. It could be skipped for efficiency, but sacrificing portability.
Converting Source code to bytecode.
- Source code is a human readable code. This is what is used when working on IDEs (code editors) such as Pycharm.
Now the actual plot. There are two approaches when carrying any of these stages: convert [or execute] a code all at once (aka compile) and convert [or execute] the code line by line (aka interpret).
For example, we could compile a source code to bytecode, compile bytecode to machine code, interpret machine code for execution.
Some implementations of languages skip stage 3 for efficiency, i.e. compile source code into machine code and then interpret machine code for execution.
Some implementations skip all middle steps and interpret the source code directly for execution.
Modern languages often involve both compiling an interpreting.
JAVA for example, compiles source code to bytecode [that is how JAVA source is stored, as a bytecode, compile bytecode to machine code [using JVM], and interpret machine code for execution. [Thus JVM is implemented differently for different OSs, but the same JAVA source code could be executed on different OS that have JVM installed.]
Python for example, compile source code to bytecode [usually found as .pyc files accompanying the .py source codes], compile bytecode to machine code [done by a virtual machine such as PVM and the result is an executable file], interpret the machine code/executable for execution.
When can we say that a language is interpreted or compiled?
- The answer is by looking into the approach used in execution. If it executes the machine code all at once (== compile), then it's a compiled language. On the other hand, if it executes the machine code line-by-line (==interpret) then it's an interpreted language.
Therefore, JAVA and Python are interpreted languages.
A confusion might occur because of the third stage, that's converting bytecode to machine code. Often this is done using a software called a virtual machine. The confusion occurs because a virtual machine acts like a machine, but it's actually not! Virtual machines are introduced for portability, having a VM on any REAL machine will allow us to execute the same source code. The approach used in most VMs [that's the third stage] is compiling, thus some people would say it's a compiled language. For the importance of VMs, we often say that such languages are both compiled and interpreted.
Python code goes through 2 stages. First step compiles the code into .pyc files which is actually a bytecode. Then this .pyc file(bytecode) is interpreted using CPython interpreter. Please refer to this link. Here process of code compilation and execution is explained in easy terms.
Its important distinguish language specification from language implementations:
- Language specification is just a document with the formal specification of the language, with its context free grammar and definition of the semantic rules (like specifying primitive types and scope dynamics).
- Language implementation is just a program (a compiler) that implement the use of the language according to its specification.
Any compiler consists of two independent parts: a frontend and backend. The frontend receives the source code, validate it and translate it into an intermediate code. After that, a backend translate it to machine code to run in a physical or a virtual machine. An interpreter is a compiler, but in this case it can produce a way of executing the intermediate code directly in a virtual machine. To execute python code, its necessary transform the code in a intermediate code, after that the code is then "assembled" as bytecode that can be stored in a file.pyc, so no need to compile modules of a program every time you run it. You can view this assembled python code using:
from dis import dis
def a(): pass
dis(a)
Anyone can build a Compiler to static binary in Python language, as can build an interpreter to C language. There are tools (lex/yacc) to simplify and automate the proccess of building a compiler.
Machines don't understand English or any other languages, they understand only byte code, which they have to be compiled (e.g., C/C++, Java) or interpreted (e.g., Ruby, Python), the .pyc is a cached version of the byte code. https://www.geeksforgeeks.org/difference-between-compiled-and-interpreted-language/ Here is a quick read on what is the difference between compiled language vs interpreted language, TLDR is interpreted language does not require you to compile all the code before run time and thus most of the time they are not strict on typing etc.
© 2022 - 2024 — McMap. All rights reserved.
javaandjavac. – Lecia