I need to know this differences in order to undestand how to use them right.
Which are the differences of DFD and Activity diagram?
I need to know this differences in order to undestand how to use them right.
Which are the differences of DFD and Activity diagram?
Actually, it's reasonably logical. You only have to look at the names.
In data flow diagrams, the lines between "boxes" represent data that flows between components of a system. Because these only show the flow of data, they do not give an indication of sequencing(1).
In activity diagrams, those lines are simply transitions between activities and do not represent data flow at all. They more represent the sequencing of activities and decisions. You can tell from these what order things happen in.
That's a simplistic explanation but should be a good starting point. Further information can be garnered from Wikipedia for DFDs and activity diagrams.
(1) There's another style of diagram, the UML sequence diagram, which can show sequencing for specific session types, such as (see Wikipedia entry for sequence diagrams):
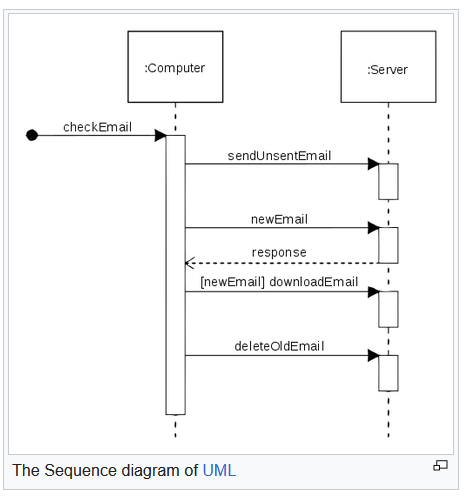
This has time increasing from top to bottom so the sequence is hopefully obvious.
Explicit bias: I'm a DFDs proponent.
@John is correct that Activity diagrams can be used to represent object flow. @pax equally correct they seldom are.
Two big DFD advantages for me:
Link to object model. Data stores on a DFD provide a really nice way to link the data produced / consumed to the object model. Very useful for consistency and ensuring your thinking is joined up.
They de-emphasise control flow. Far too often designs over-constrain sequencing. Activity diagrams do support concurrency - but it requires the user to (a) remember and (b) use it. So the default is over-serialisation. DFDs don't. They lay bare the real sequence dependencies without any extra effort on the part of the user. Consequently they also make it easier to see causal relationships. If processes a and b both require data input D then it's obvious on the diagram. And hence parallel activity is obvious.
Don't get me wrong - I'm not against Activity diags. Where control flow is the primary consideration I'll use an AD over a DFD. But empirically I'd say I find DFDs a more useful tool in ~70-80% of cases.
Of course, YMMV.
Just a humble opinion from someone who has had to explain processes, both computer and manual, to upper management and CIOs. I have found simple is better and pound-for-pound, DFDs get the message across when I am actually "asked" about details. That being said, the better approach is to always practice the story line and answer in simple answers.
One final comment regarding the age of tools and products. Remember that in most cases these are running the business and work pretty darn good. The adage "you break it (or replace it) and you own it" can make you a hero or make you into a clown.
We have a CIO who wants to replace all mainframe application for the simple reason that they are old technology. One must weigh the consequences and understand if the replacement can handle workload. Have you ever wondered why JPMC, Credit Swiss, Walmart, and Bank of America to name a few still run mainframes?
My apologies for taking it in that direction. Just make sure, whatever analysis tool is used, that all aspects of the replacement are documented including workload, I/O, concurrent users, adoption curve, and scalability.
Data Flow represents flow within one module or one independent code. However Sequence Diagram represents sequence of activity in between different modules.
Yes at some points they may pass the same messages.
I basically use Sequence diagram in interface documents which will be shared with other modules/elements, however DFD will be used in Low level design documents which will be used to develop the code within one module or network element.
If we look closer to a dataflow diagram, we can notice that when a node collects data from all its edges, it starts to process them. And to process, it needs an activity token, which represents access to a processor. Usually the process of obtaining that token is omitted, but it has to exist. Typically, the whole node as a token is put in a double-ended queue, where on the other end of that queue free activities (processors or threads) are stored. A thread pool is a perfect example of such a queue, and the nodes ready to work are represented as tasks. As soon as a node meets activity, they both are taken from the queue and actual processing starts. When processing finishes, activity is returned to the queue. This way we can think of activity as a special kind of token.
So both dataflow and activity diagrams are just simplified variants of a general active-data-flow diagram, with either activities or data tokens omitted. But generally, both kinds of tokens can be represented in a diagram simultaneously.
Programmers used to think about threads as activities, but if we look at them closer, we notice that when a thread is ready to execute, it gets in a line to processors, and real execution starts only when a free processor switch to that thread. This is absolute analogy as tasks are executed on a thread pool. So from simplified point of view, a thread is an activity, and from more rigorous point of view a thread is a data token and the only real activity is a physical processor. This shows that activity tokens are not different from data tokens. And indeed, we can omit the route of node chasing an activity and consider a dataflow node as an activity itself, which starts to work immediately when all its edges (inputs) contain data.
© 2022 - 2024 — McMap. All rights reserved.