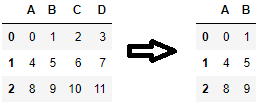
How do I select columns a and b from df, and save them into a new dataframe df1?
index a b c
1 2 3 4
2 3 4 5
Unsuccessful attempt:
df1 = df['a':'b']
df1 = df.ix[:, 'a':'b']
How do I select columns a and b from df, and save them into a new dataframe df1?
index a b c
1 2 3 4
2 3 4 5
Unsuccessful attempt:
df1 = df['a':'b']
df1 = df.ix[:, 'a':'b']
The column names (which are strings) cannot be sliced in the manner you tried.
Here you have a couple of options. If you know from context which variables you want to slice out, you can just return a view of only those columns by passing a list into the __getitem__ syntax (the []'s).
df1 = df[['a', 'b']]
Alternatively, if it matters to index them numerically and not by their name (say your code should automatically do this without knowing the names of the first two columns) then you can do this instead:
df1 = df.iloc[:, 0:2] # Remember that Python does not slice inclusive of the ending index.
Additionally, you should familiarize yourself with the idea of a view into a Pandas object vs. a copy of that object. The first of the above methods will return a new copy in memory of the desired sub-object (the desired slices).
Sometimes, however, there are indexing conventions in Pandas that don't do this and instead give you a new variable that just refers to the same chunk of memory as the sub-object or slice in the original object. This will happen with the second way of indexing, so you can modify it with the .copy() method to get a regular copy. When this happens, changing what you think is the sliced object can sometimes alter the original object. Always good to be on the look out for this.
df1 = df.iloc[0, 0:2].copy() # To avoid the case where changing df1 also changes df
To use iloc, you need to know the column positions (or indices). As the column positions may change, instead of hard-coding indices, you can use iloc along with get_loc function of columns method of dataframe object to obtain column indices.
{df.columns.get_loc(c): c for idx, c in enumerate(df.columns)}
Now you can use this dictionary to access columns through names and using iloc.
As of version 0.11.0, columns can be sliced in the manner you tried using the .loc indexer:
df.loc[:, 'C':'E']
is equivalent to
df[['C', 'D', 'E']] # or df.loc[:, ['C', 'D', 'E']]
and returns columns C through E.
A demo on a randomly generated DataFrame:
import pandas as pd
import numpy as np
np.random.seed(5)
df = pd.DataFrame(np.random.randint(100, size=(100, 6)),
columns=list('ABCDEF'),
index=['R{}'.format(i) for i in range(100)])
df.head()
Out:
A B C D E F
R0 99 78 61 16 73 8
R1 62 27 30 80 7 76
R2 15 53 80 27 44 77
R3 75 65 47 30 84 86
R4 18 9 41 62 1 82
To get the columns from C to E (note that unlike integer slicing, E is included in the columns):
df.loc[:, 'C':'E']
Out:
C D E
R0 61 16 73
R1 30 80 7
R2 80 27 44
R3 47 30 84
R4 41 62 1
R5 5 58 0
...
The same works for selecting rows based on labels. Get the rows R6 to R10 from those columns:
df.loc['R6':'R10', 'C':'E']
Out:
C D E
R6 51 27 31
R7 83 19 18
R8 11 67 65
R9 78 27 29
R10 7 16 94
.loc also accepts a Boolean array so you can select the columns whose corresponding entry in the array is True. For example, df.columns.isin(list('BCD')) returns array([False, True, True, True, False, False], dtype=bool) - True if the column name is in the list ['B', 'C', 'D']; False, otherwise.
df.loc[:, df.columns.isin(list('BCD'))]
Out:
B C D
R0 78 61 16
R1 27 30 80
R2 53 80 27
R3 65 47 30
R4 9 41 62
R5 78 5 58
...
Assuming your column names (df.columns) are ['index','a','b','c'], then the data you want is in the
third and fourth columns. If you don't know their names when your script runs, you can do this
newdf = df[df.columns[2:4]] # Remember, Python is zero-offset! The "third" entry is at slot two.
As EMS points out in his answer, df.ix slices columns a bit more concisely, but the .columns slicing interface might be more natural, because it uses the vanilla one-dimensional Python list indexing/slicing syntax.
Warning: 'index' is a bad name for a DataFrame column. That same label is also used for the real df.index attribute, an Index array. So your column is returned by df['index'] and the real DataFrame index is returned by df.index. An Index is a special kind of Series optimized for lookup of its elements' values. For df.index it's for looking up rows by their label. That df.columns attribute is also a pd.Index array, for looking up columns by their labels.
In the latest version of Pandas there is an easy way to do exactly this. Column names (which are strings) can be sliced in whatever manner you like.
columns = ['b', 'c']
df1 = pd.DataFrame(df, columns=columns)
In [39]: df
Out[39]:
index a b c
0 1 2 3 4
1 2 3 4 5
In [40]: df1 = df[['b', 'c']]
In [41]: df1
Out[41]:
b c
0 3 4
1 4 5
With Pandas,
wit column names
dataframe[['column1','column2']]
to select by iloc and specific columns with index number:
dataframe.iloc[:,[1,2]]
with loc column names can be used like
dataframe.loc[:,['column1','column2']]
You can use the pandas.DataFrame.filter method to either filter or reorder columns like this:
df1 = df.filter(['a', 'b'])
This is also very useful when you are chaining methods.
You could provide a list of columns to be dropped and return back the DataFrame with only the columns needed using the drop() function on a Pandas DataFrame.
Just saying
colsToDrop = ['a']
df.drop(colsToDrop, axis=1)
would return a DataFrame with just the columns b and c.
The drop method is documented here.
I found this method to be very useful:
# iloc[row slicing, column slicing]
surveys_df.iloc [0:3, 1:4]
More details can be found here.
Starting with 0.21.0, using .loc or [] with a list with one or more missing labels is deprecated in favor of .reindex. So, the answer to your question is:
df1 = df.reindex(columns=['b','c'])
In prior versions, using .loc[list-of-labels] would work as long as at least one of the keys was found (otherwise it would raise a KeyError). This behavior is deprecated and now shows a warning message. The recommended alternative is to use .reindex().
Read more at Indexing and Selecting Data.
You can use Pandas.
I create the DataFrame:
import pandas as pd
df = pd.DataFrame([[1, 2,5], [5,4, 5], [7,7, 8], [7,6,9]],
index=['Jane', 'Peter','Alex','Ann'],
columns=['Test_1', 'Test_2', 'Test_3'])
The DataFrame:
Test_1 Test_2 Test_3
Jane 1 2 5
Peter 5 4 5
Alex 7 7 8
Ann 7 6 9
To select one or more columns by name:
df[['Test_1', 'Test_3']]
Test_1 Test_3
Jane 1 5
Peter 5 5
Alex 7 8
Ann 7 9
You can also use:
df.Test_2
And you get column Test_2:
Jane 2
Peter 4
Alex 7
Ann 6
You can also select columns and rows from these rows using .loc(). This is called "slicing". Notice that I take from column Test_1 to Test_3:
df.loc[:, 'Test_1':'Test_3']
The "Slice" is:
Test_1 Test_2 Test_3
Jane 1 2 5
Peter 5 4 5
Alex 7 7 8
Ann 7 6 9
And if you just want Peter and Ann from columns Test_1 and Test_3:
df.loc[['Peter', 'Ann'], ['Test_1', 'Test_3']]
You get:
Test_1 Test_3
Peter 5 5
Ann 7 9
If you want to get one element by row index and column name, you can do it just like df['b'][0]. It is as simple as you can imagine.
Or you can use df.ix[0,'b'] - mixed usage of index and label.
Note: Since v0.20, ix has been deprecated in favour of loc / iloc.
Even though there are a lot methods to select multiple columns (using a list of column names cols or a list of column indices idx):
[cols], .loc[:, cols], .filter(cols), .get(cols), .reindex(cols, axis=1), .xs(cols, axis=1).iloc[:, idx], .take(idx, axis=1).iloc[:, 0:1], .loc[:, 'col1':'col2'], .truncate('col1', 'col2', axis=1)df.loc[:, pd.RangeIndex(df.shape[1])<2], df.loc[:, df.columns.isin(cols)]in practice, probably the only method worth remembering is [cols] or __getitem__(cols) method, e.g. df[['A', 'B']]. All methods to select multiple columns create a copy anyway. If you're worried about SettingWithCopyWarning, then turn on copy-on-write mode as soon as you import pandas (see this answer for more details).
pd.set_option('mode.copy_on_write', True) # turn on copy-on-write
df = pd.DataFrame(0, range(5), [*'ABCD']) # some initial dataframe
df1 = df[['A','C']] # select columns
df1['E'] = 1 # no warnings, life's good
Old answer:
To select columns by index, take() could be used.
# select the first and third columns
df1 = df.take([0,2], axis=1)
Since this creates a copy by default, you won't get the pesky SettingWithCopyWarning with this.
Also xs() could be used to select columns by label (must pass Series/array/Index).
# select columns A and B
df1 = df.xs(pd.Index(['A', 'B']), axis=1)
The most useful aspect of xs is that it could be used to select MultiIndex columns by level.
df2 = df.xs('col1', level=1, axis=1)
# can select specific columns as well
df3 = df.xs(pd.MultiIndex.from_tuples([('A', 'col1'), ('B', 'col2')]), axis=1)

df[['a', 'b']] # Select all rows of 'a' and 'b'column
df.loc[0:10, ['a', 'b']] # Index 0 to 10 select column 'a' and 'b'
df.loc[0:10, 'a':'b'] # Index 0 to 10 select column 'a' to 'b'
df.iloc[0:10, 3:5] # Index 0 to 10 and column 3 to 5
df.iloc[3, 3:5] # Index 3 of column 3 to 5
Try to use pandas.DataFrame.get (see the documentation):
import pandas as pd
import numpy as np
dates = pd.date_range('20200102', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
df.get(['A', 'C'])
One different and easy approach: iterating rows
df1 = pd.DataFrame() # Creating an empty dataframe
for index,i in df.iterrows():
df1.loc[index, 'A'] = df.loc[index, 'A']
df1.loc[index, 'B'] = df.loc[index, 'B']
df1.head()
The different approaches discussed in the previous answers are based on the assumption that either the user knows column indices to drop or subset on, or the user wishes to subset a dataframe using a range of columns (for instance between 'C' : 'E').
pandas.DataFrame.drop() is certainly an option to subset data based on a list of columns defined by user (though you have to be cautious that you always use copy of dataframe and inplace parameters should not be set to True!!)
Another option is to use pandas.columns.difference(), which does a set difference on column names, and returns an index type of array containing desired columns. Following is the solution:
df = pd.DataFrame([[2,3,4], [3,4,5]], columns=['a','b','c'], index=[1,2])
columns_for_differencing = ['a']
df1 = df.copy()[df.columns.difference(columns_for_differencing)]
print(df1)
The output would be:
b c
1 3 4
2 4 5
You can also use df.pop():
>>> df = pd.DataFrame([('falcon', 'bird', 389.0),
... ('parrot', 'bird', 24.0),
... ('lion', 'mammal', 80.5),
... ('monkey', 'mammal', np.nan)],
... columns=('name', 'class', 'max_speed'))
>>> df
name class max_speed
0 falcon bird 389.0
1 parrot bird 24.0
2 lion mammal 80.5
3 monkey mammal
>>> df.pop('class')
0 bird
1 bird
2 mammal
3 mammal
Name: class, dtype: object
>>> df
name max_speed
0 falcon 389.0
1 parrot 24.0
2 lion 80.5
3 monkey NaN
Please use df.pop(c).
I've seen several answers on that, but one remained unclear to me. How would you select those columns of interest?
The answer to that is that if you have them gathered in a list, you can just reference the columns using the list.
print(extracted_features.shape)
print(extracted_features)
(63,)
['f000004' 'f000005' 'f000006' 'f000014' 'f000039' 'f000040' 'f000043'
'f000047' 'f000048' 'f000049' 'f000050' 'f000051' 'f000052' 'f000053'
'f000054' 'f000055' 'f000056' 'f000057' 'f000058' 'f000059' 'f000060'
'f000061' 'f000062' 'f000063' 'f000064' 'f000065' 'f000066' 'f000067'
'f000068' 'f000069' 'f000070' 'f000071' 'f000072' 'f000073' 'f000074'
'f000075' 'f000076' 'f000077' 'f000078' 'f000079' 'f000080' 'f000081'
'f000082' 'f000083' 'f000084' 'f000085' 'f000086' 'f000087' 'f000088'
'f000089' 'f000090' 'f000091' 'f000092' 'f000093' 'f000094' 'f000095'
'f000096' 'f000097' 'f000098' 'f000099' 'f000100' 'f000101' 'f000103']
I have the following list/NumPy array extracted_features, specifying 63 columns. The original dataset has 103 columns, and I would like to extract exactly those, then I would use
dataset[extracted_features]
And you will end up with this
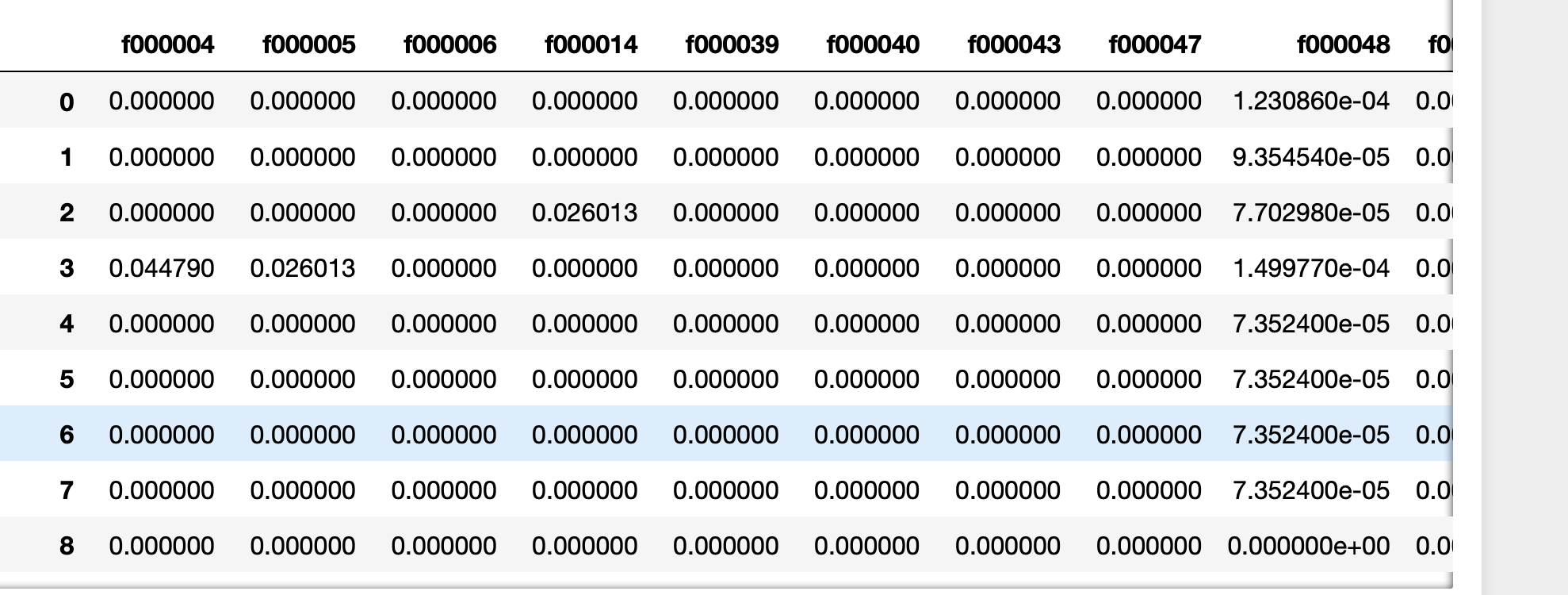
This something you would use quite often in machine learning (more specifically, in feature selection). I would like to discuss other ways too, but I think that has already been covered by other Stack Overflower users.
To select multiple columns, extract and view them thereafter: df is the previously named data frame. Then create a new data frame df1, and select the columns A to D which you want to extract and view.
df1 = pd.DataFrame(data_frame, columns=['Column A', 'Column B', 'Column C', 'Column D'])
df1
All required columns will show up!
To exclude some columns you can drop them in the column index. For example:
A B C D
0 1 10 100 1000
1 2 20 200 2000
Select all except two:
df[df.columns.drop(['B', 'D'])]
Output:
A C
0 1 100
1 2 200
You can also use the method truncate to select middle columns:
df.truncate(before='B', after='C', axis=1)
Output:
B C
0 10 100
1 20 200
def get_slize(dataframe, start_row, end_row, start_col, end_col):
assert len(dataframe) > end_row and start_row >= 0
assert len(dataframe.columns) > end_col and start_col >= 0
list_of_indexes = list(dataframe.columns)[start_col:end_col]
ans = dataframe.iloc[start_row:end_row][list_of_indexes]
return ans
Just use this function
© 2022 - 2024 — McMap. All rights reserved.
df[['a','b']]produces a copy – Pumpernickel