To delete a column in a DataFrame, I can successfully use:
del df['column_name']
But why can't I use the following?
del df.column_name
Since it is possible to access the Series via df.column_name, I expected this to work.
To delete a column in a DataFrame, I can successfully use:
del df['column_name']
But why can't I use the following?
del df.column_name
Since it is possible to access the Series via df.column_name, I expected this to work.
As you've guessed, the right syntax is
del df['column_name']
It's difficult to make del df.column_name work simply as the result of syntactic limitations in Python. del df[name] gets translated to df.__delitem__(name) under the covers by Python.
del df[name], it gets translated to df.__delitem__(name) which is a method that DataFrame can implement and modify to its needs. In the case of del df.name, the member variable gets removed without a chance for any custom-code running. Consider your own example - can you get del a.var to result in a print of "deleting variable"? If you can, please tell me how. I can't :) –
Tricot pandas developers didn't, but that doesn't mean it is hard to do. –
Spheno Time? –
Albeit The best way to do this in Pandas is to use drop:
df = df.drop('column_name', axis=1)
where 1 is the axis number (0 for rows and 1 for columns.)
Or, the drop() method accepts index/columns keywords as an alternative to specifying the axis. So we can now just do:
df = df.drop(columns=['column_nameA', 'column_nameB'])
To delete the column without having to reassign df you can do:
df.drop('column_name', axis=1, inplace=True)
Finally, to drop by column number instead of by column label, try this to delete, e.g. the 1st, 2nd and 4th columns:
df = df.drop(df.columns[[0, 1, 3]], axis=1) # df.columns is zero-based pd.Index
Also working with "text" syntax for the columns:
df.drop(['column_nameA', 'column_nameB'], axis=1, inplace=True)
del for some reason? –
Blessing drop over del is that drop allows you to drop multiple columns at once, perform the operation inplace or not, and also delete records along any axis (especially useful for a 3-D matrix or Panel) –
Desalinate drop over del is that drop is part of the pandas API and contains documentation. –
Theola df = df.drop('column_name', 1) throws a "FutureWarning: In a future version of pandas all arguments of DataFrame.drop except for the argument 'labels' will be keyword-only" in 3.7.2. Specify df = df.drop('column_name', axis=1) to avoid warning, –
Hydrograph df.drop([0,1], inplace=True) and df.reset_index(drop=True, inplace=True) –
Manteau del faster than dropping and saving as a new dataframe? –
Latterly As you've guessed, the right syntax is
del df['column_name']
It's difficult to make del df.column_name work simply as the result of syntactic limitations in Python. del df[name] gets translated to df.__delitem__(name) under the covers by Python.
class A(object): def __init__(self): self.var = 1 sets up a class, then a = A(); del a.var works just fine... –
Viborg del df[name], it gets translated to df.__delitem__(name) which is a method that DataFrame can implement and modify to its needs. In the case of del df.name, the member variable gets removed without a chance for any custom-code running. Consider your own example - can you get del a.var to result in a print of "deleting variable"? If you can, please tell me how. I can't :) –
Tricot pandas developers didn't, but that doesn't mean it is hard to do. –
Spheno Time? –
Albeit Use:
columns = ['Col1', 'Col2', ...]
df.drop(columns, inplace=True, axis=1)
This will delete one or more columns in-place. Note that inplace=True was added in pandas v0.13 and won't work on older versions. You'd have to assign the result back in that case:
df = df.drop(columns, axis=1)
Delete first, second and fourth columns:
df.drop(df.columns[[0,1,3]], axis=1, inplace=True)
Delete first column:
df.drop(df.columns[[0]], axis=1, inplace=True)
There is an optional parameter inplace so that the original
data can be modified without creating a copy.
Column selection, addition, deletion
Delete column column-name:
df.pop('column-name')
df = DataFrame.from_items([('A', [1, 2, 3]), ('B', [4, 5, 6]), ('C', [7,8, 9])], orient='index', columns=['one', 'two', 'three'])
print df:
one two three
A 1 2 3
B 4 5 6
C 7 8 9
df.drop(df.columns[[0]], axis=1, inplace=True)
print df:
two three
A 2 3
B 5 6
C 8 9
three = df.pop('three')
print df:
two
A 2
B 5
C 8
The actual question posed, missed by most answers here is:
del df.column_name?At first we need to understand the problem, which requires us to dive into Python magic methods.
As Wes points out in his answer, del df['column'] maps to the Python magic method df.__delitem__('column') which is implemented in Pandas to drop the column.
However, as pointed out in the link above about Python magic methods:
In fact,
__del__should almost never be used because of the precarious circumstances under which it is called; use it with caution!
You could argue that del df['column_name'] should not be used or encouraged, and thereby del df.column_name should not even be considered.
However, in theory, del df.column_name could be implemented to work in Pandas using the magic method __delattr__. This does however introduce certain problems, problems which the del df['column_name'] implementation already has, but to a lesser degree.
What if I define a column in a dataframe called "dtypes" or "columns"?
Then assume I want to delete these columns.
del df.dtypes would make the __delattr__ method confused as if it should delete the "dtypes" attribute or the "dtypes" column.
.ix, .loc or .iloc methods.You cannot do del df.column_name, because Pandas has a quite wildly grown architecture that needs to be reconsidered in order for this kind of cognitive dissonance not to occur to its users.
Don't use df.column_name. It may be pretty, but it causes cognitive dissonance.
There are multiple ways of deleting a column.
There should be one-- and preferably only one --obvious way to do it.
Columns are sometimes attributes but sometimes not.
Special cases aren't special enough to break the rules.
Does del df.dtypes delete the dtypes attribute or the dtypes column?
In the face of ambiguity, refuse the temptation to guess.
A nice addition is the ability to drop columns only if they exist. This way you can cover more use cases, and it will only drop the existing columns from the labels passed to it:
Simply add errors='ignore', for example.:
df.drop(['col_name_1', 'col_name_2', ..., 'col_name_N'], inplace=True, axis=1, errors='ignore')
From version 0.16.1, you can do
df.drop(['column_name'], axis = 1, inplace = True, errors = 'ignore')
errors= 'ignore') df.drop(['column_1','column_2'], axis=1 , inplace=True,errors= 'ignore'), if such an application desired! –
Focalize It's good practice to always use the [] notation. One reason is that attribute notation (df.column_name) does not work for numbered indices:
In [1]: df = DataFrame([[1, 2, 3], [4, 5, 6]])
In [2]: df[1]
Out[2]:
0 2
1 5
Name: 1
In [3]: df.1
File "<ipython-input-3-e4803c0d1066>", line 1
df.1
^
SyntaxError: invalid syntax
Pandas version 0.21 has changed the drop method slightly to include both the index and columns parameters to match the signature of the rename and reindex methods.
df.drop(columns=['column_a', 'column_c'])
Personally, I prefer using the axis parameter to denote columns or index because it is the predominant keyword parameter used in nearly all pandas methods. But, now you have some added choices in version 0.21.
In Pandas 0.16.1+, you can drop columns only if they exist per the solution posted by eiTan LaVi. Prior to that version, you can achieve the same result via a conditional list comprehension:
df.drop([col for col in ['col_name_1','col_name_2',...,'col_name_N'] if col in df],
axis=1, inplace=True)
Use:
df.drop('columnname', axis =1, inplace = True)
Or else you can go with
del df['colname']
To delete multiple columns based on column numbers
df.drop(df.iloc[:,1:3], axis = 1, inplace = True)
To delete multiple columns based on columns names
df.drop(['col1','col2',..'coln'], axis = 1, inplace = True)
A lot of effort to find a marginally more efficient solution. Difficult to justify the added complexity while sacrificing the simplicity of df.drop(dlst, 1, errors='ignore')
df.reindex_axis(np.setdiff1d(df.columns.values, dlst), 1)
Preamble
Deleting a column is semantically the same as selecting the other columns. I'll show a few additional methods to consider.
I'll also focus on the general solution of deleting multiple columns at once and allowing for the attempt to delete columns not present.
Using these solutions are general and will work for the simple case as well.
Setup
Consider the pd.DataFrame df and list to delete dlst
df = pd.DataFrame(dict(zip('ABCDEFGHIJ', range(1, 11))), range(3))
dlst = list('HIJKLM')
df
A B C D E F G H I J
0 1 2 3 4 5 6 7 8 9 10
1 1 2 3 4 5 6 7 8 9 10
2 1 2 3 4 5 6 7 8 9 10
dlst
['H', 'I', 'J', 'K', 'L', 'M']
The result should look like:
df.drop(dlst, 1, errors='ignore')
A B C D E F G
0 1 2 3 4 5 6 7
1 1 2 3 4 5 6 7
2 1 2 3 4 5 6 7
Since I'm equating deleting a column to selecting the other columns, I'll break it into two types:
We start by manufacturing the list/array of labels that represent the columns we want to keep and without the columns we want to delete.
df.columns.difference(dlst)
Index(['A', 'B', 'C', 'D', 'E', 'F', 'G'], dtype='object')
np.setdiff1d(df.columns.values, dlst)
array(['A', 'B', 'C', 'D', 'E', 'F', 'G'], dtype=object)
df.columns.drop(dlst, errors='ignore')
Index(['A', 'B', 'C', 'D', 'E', 'F', 'G'], dtype='object')
list(set(df.columns.values.tolist()).difference(dlst))
# does not preserve order
['E', 'D', 'B', 'F', 'G', 'A', 'C']
[x for x in df.columns.values.tolist() if x not in dlst]
['A', 'B', 'C', 'D', 'E', 'F', 'G']
Columns from Labels
For the sake of comparing the selection process, assume:
cols = [x for x in df.columns.values.tolist() if x not in dlst]
Then we can evaluate
df.loc[:, cols]df[cols]df.reindex(columns=cols)df.reindex_axis(cols, 1)Which all evaluate to:
A B C D E F G
0 1 2 3 4 5 6 7
1 1 2 3 4 5 6 7
2 1 2 3 4 5 6 7
We can construct an array/list of booleans for slicing
~df.columns.isin(dlst)~np.in1d(df.columns.values, dlst)[x not in dlst for x in df.columns.values.tolist()](df.columns.values[:, None] != dlst).all(1)Columns from Boolean
For the sake of comparison
bools = [x not in dlst for x in df.columns.values.tolist()]
df.loc[: bools]Which all evaluate to:
A B C D E F G
0 1 2 3 4 5 6 7
1 1 2 3 4 5 6 7
2 1 2 3 4 5 6 7
Robust Timing
Functions
setdiff1d = lambda df, dlst: np.setdiff1d(df.columns.values, dlst)
difference = lambda df, dlst: df.columns.difference(dlst)
columndrop = lambda df, dlst: df.columns.drop(dlst, errors='ignore')
setdifflst = lambda df, dlst: list(set(df.columns.values.tolist()).difference(dlst))
comprehension = lambda df, dlst: [x for x in df.columns.values.tolist() if x not in dlst]
loc = lambda df, cols: df.loc[:, cols]
slc = lambda df, cols: df[cols]
ridx = lambda df, cols: df.reindex(columns=cols)
ridxa = lambda df, cols: df.reindex_axis(cols, 1)
isin = lambda df, dlst: ~df.columns.isin(dlst)
in1d = lambda df, dlst: ~np.in1d(df.columns.values, dlst)
comp = lambda df, dlst: [x not in dlst for x in df.columns.values.tolist()]
brod = lambda df, dlst: (df.columns.values[:, None] != dlst).all(1)
Testing
res1 = pd.DataFrame(
index=pd.MultiIndex.from_product([
'loc slc ridx ridxa'.split(),
'setdiff1d difference columndrop setdifflst comprehension'.split(),
], names=['Select', 'Label']),
columns=[10, 30, 100, 300, 1000],
dtype=float
)
res2 = pd.DataFrame(
index=pd.MultiIndex.from_product([
'loc'.split(),
'isin in1d comp brod'.split(),
], names=['Select', 'Label']),
columns=[10, 30, 100, 300, 1000],
dtype=float
)
res = res1.append(res2).sort_index()
dres = pd.Series(index=res.columns, name='drop')
for j in res.columns:
dlst = list(range(j))
cols = list(range(j // 2, j + j // 2))
d = pd.DataFrame(1, range(10), cols)
dres.at[j] = timeit('d.drop(dlst, 1, errors="ignore")', 'from __main__ import d, dlst', number=100)
for s, l in res.index:
stmt = '{}(d, {}(d, dlst))'.format(s, l)
setp = 'from __main__ import d, dlst, {}, {}'.format(s, l)
res.at[(s, l), j] = timeit(stmt, setp, number=100)
rs = res / dres
rs
10 30 100 300 1000
Select Label
loc brod 0.747373 0.861979 0.891144 1.284235 3.872157
columndrop 1.193983 1.292843 1.396841 1.484429 1.335733
comp 0.802036 0.732326 1.149397 3.473283 25.565922
comprehension 1.463503 1.568395 1.866441 4.421639 26.552276
difference 1.413010 1.460863 1.587594 1.568571 1.569735
in1d 0.818502 0.844374 0.994093 1.042360 1.076255
isin 1.008874 0.879706 1.021712 1.001119 0.964327
setdiff1d 1.352828 1.274061 1.483380 1.459986 1.466575
setdifflst 1.233332 1.444521 1.714199 1.797241 1.876425
ridx columndrop 0.903013 0.832814 0.949234 0.976366 0.982888
comprehension 0.777445 0.827151 1.108028 3.473164 25.528879
difference 1.086859 1.081396 1.293132 1.173044 1.237613
setdiff1d 0.946009 0.873169 0.900185 0.908194 1.036124
setdifflst 0.732964 0.823218 0.819748 0.990315 1.050910
ridxa columndrop 0.835254 0.774701 0.907105 0.908006 0.932754
comprehension 0.697749 0.762556 1.215225 3.510226 25.041832
difference 1.055099 1.010208 1.122005 1.119575 1.383065
setdiff1d 0.760716 0.725386 0.849949 0.879425 0.946460
setdifflst 0.710008 0.668108 0.778060 0.871766 0.939537
slc columndrop 1.268191 1.521264 2.646687 1.919423 1.981091
comprehension 0.856893 0.870365 1.290730 3.564219 26.208937
difference 1.470095 1.747211 2.886581 2.254690 2.050536
setdiff1d 1.098427 1.133476 1.466029 2.045965 3.123452
setdifflst 0.833700 0.846652 1.013061 1.110352 1.287831
fig, axes = plt.subplots(2, 2, figsize=(8, 6), sharey=True)
for i, (n, g) in enumerate([(n, g.xs(n)) for n, g in rs.groupby('Select')]):
ax = axes[i // 2, i % 2]
g.plot.bar(ax=ax, title=n)
ax.legend_.remove()
fig.tight_layout()
This is relative to the time it takes to run df.drop(dlst, 1, errors='ignore'). It seems like after all that effort, we only improve performance modestly.
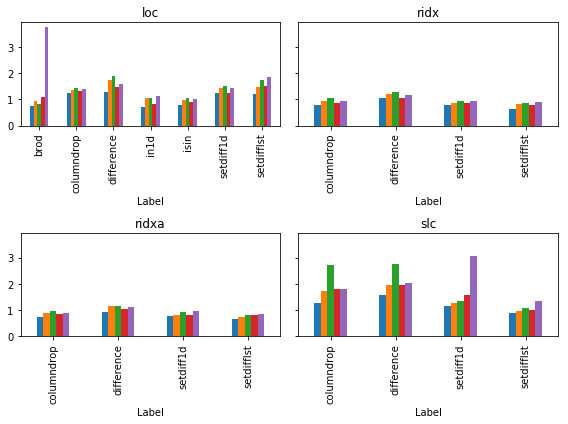
If fact the best solutions use reindex or reindex_axis on the hack list(set(df.columns.values.tolist()).difference(dlst)). A close second and still very marginally better than drop is np.setdiff1d.
rs.idxmin().pipe(
lambda x: pd.DataFrame(
dict(idx=x.values, val=rs.lookup(x.values, x.index)),
x.index
)
)
idx val
10 (ridx, setdifflst) 0.653431
30 (ridxa, setdifflst) 0.746143
100 (ridxa, setdifflst) 0.816207
300 (ridx, setdifflst) 0.780157
1000 (ridxa, setdifflst) 0.861622
We can remove or delete a specified column or specified columns by the drop() method.
Suppose df is a dataframe.
Column to be removed = column0
Code:
df = df.drop(column0, axis=1)
To remove multiple columns col1, col2, . . . , coln, we have to insert all the columns that needed to be removed in a list. Then remove them by the drop() method.
Code:
df = df.drop([col1, col2, . . . , coln], axis=1)
If your original dataframe df is not too big, you have no memory constraints, and you only need to keep a few columns, or, if you don't know beforehand the names of all the extra columns that you do not need, then you might as well create a new dataframe with only the columns you need:
new_df = df[['spam', 'sausage']]
Deleting a column using the iloc function of dataframe and slicing, when we have a typical column name with unwanted values:
df = df.iloc[:,1:] # Removing an unnamed index column
Here 0 is the default row and 1 is the first column, hence :,1: is our parameter for deleting the first column.
The dot syntax works in JavaScript, but not in Python.
del df['column_name']del df['column_name'] or del df.column_nameAnother way of deleting a column in a Pandas DataFrame
If you're not looking for in-place deletion then you can create a new DataFrame by specifying the columns using DataFrame(...) function as:
my_dict = { 'name' : ['a','b','c','d'], 'age' : [10,20,25,22], 'designation' : ['CEO', 'VP', 'MD', 'CEO']}
df = pd.DataFrame(my_dict)
Create a new DataFrame as
newdf = pd.DataFrame(df, columns=['name', 'age'])
You get a result as good as what you get with del / drop.
Taking advantage by using Autocomplete or "IntelliSense" over string literals:
del df[df.column1.name]
# or
df.drop(df.column1.name, axis=1, inplace=True)
It works fine with current Pandas versions.
If you want find the simple ways to delete column_name from df data frame, here we go:
df = df[df.columns.drop('column_name')]
Deleting a column using del is not only problematic (as explained by @firelynx) but also very slow. For example, it's ~37 times slower than drop().
from timeit import timeit
setup = "import pandas as pd; df=pd.DataFrame([range(10000)])"
for _ in range(3):
t1 = timeit("df = df.drop(columns=df.columns[0])", setup, number=10000)
t2 = timeit("del df[df.columns[0]]", setup, number=10000)
print(f"{t2/t1:.2f}")
# 37.40
# 37.45
# 37.34
On the topic of performance, if a single column needs to be dropped, boolean indexing (create a boolean Series of wanted columns and loc-index them) is actually the fastest method for the job. However, if multiple columns need to be dropped, drop() is the fastest method.
As a refresher, the methods in question are as follows (all of the methods given on this page where tested but these two were the fastest).
import pandas as pd
df = pd.DataFrame([range(10)]*5).add_prefix('col')
# drop a single column (the performance comparison is shown in LHS subplot)
df1 = df.loc[:, df.columns != 'col2'] # boolean indexing
df2 = df.drop(columns='col2') # drop
# drop multiple columns (the performance comparison is shown in RHS subplot)
df1 = df.loc[:, ~df.columns.isin(['col2', 'col4'])] # boolean indexing
df2 = df.drop(columns=['col2', 'col4']) # drop
The following performance comparison graph was created using the perfplot library (which performs timeit tests under the hood). This supports the claim made above. The main takeaway is when dropping single column, boolean indexing is faster; however, when dropping multiple columns for very wide dataframes, drop() is faster.
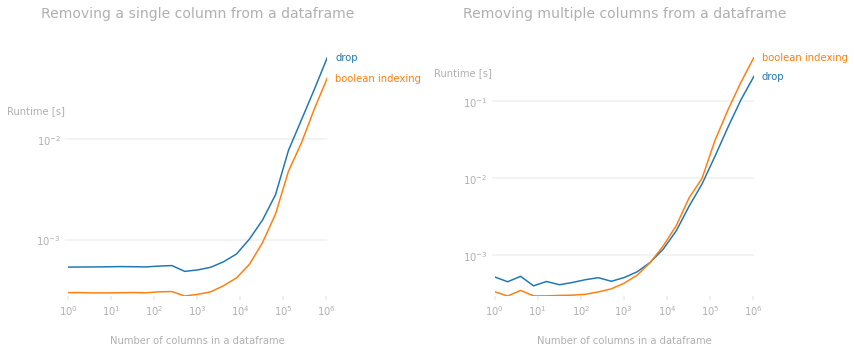
Code used to produce the performance plots:
import pandas as pd
import perfplot
import random
import matplotlib.pyplot as plt
plt.figure(figsize=(12,5), facecolor='white')
plt.subplot(1, 2, 1)
perfplot.plot(
setup=lambda n: pd.DataFrame([range(n+1)]),
kernels=[lambda df: df.drop(columns=df.columns[0]), lambda df: df.loc[:, df.columns != df.columns[0]]],
labels= ['drop', 'boolean indexing'],
n_range=[2**k for k in range(21)],
xlabel='Number of columns in a dataframe',
title='Removing a single column from a dataframe',
equality_check=pd.DataFrame.equals)
plt.subplot(1, 2, 2)
perfplot.plot(
setup=lambda n: (pd.DataFrame([range(n+1)]), random.sample(range(n+1), k=(n+1)//2)),
kernels=[lambda df,cols: df.drop(columns=cols), lambda df,cols: df.loc[:, ~df.columns.isin(cols)]],
labels= ['drop', 'boolean indexing'],
n_range=[2**k for k in range(21)],
xlabel='Number of columns in a dataframe',
title='Removing multiple columns from a dataframe',
equality_check=pd.DataFrame.equals)
plt.tight_layout();
To remove columns before and after specific columns you can use the method truncate. For example:
A B C D E
0 1 10 100 1000 10000
1 2 20 200 2000 20000
df.truncate(before='B', after='D', axis=1)
Output:
B C D
0 10 100 1000
1 20 200 2000
Viewed from a general Python standpoint, del obj.column_name makes sense if the attribute column_name can be deleted. It needs to be a regular attribute - or a property with a defined deleter.
The reasons why this doesn't translate to Pandas, and does not make sense for Pandas Dataframes are:
df.column_name to be a “virtual attribute”, it is not a thing in its own right, it is not the “seat” of that column, it's just a way to access the column. Much like a property with no deleter.© 2022 - 2024 — McMap. All rights reserved.
class A(object): def __init__(self): self.var = 1sets up a class, thena = A(); del a.varworks just fine... – Viborg