For the Bayesian network as a classifier, the features are selected based on some scoring functions like Bayesian scoring function and minimal description length(the two are equivalent in theory to each other given that there are enough training data). The scoring functions mainly restrict the structure (connections and directions) and the parameters(likelihood) using the data. After the structure has been learned the class is only determined by the nodes in the Markov blanket(its parents, its children, and the parents of its children), and all variables given the Markov blanket are discarded.
For the Naive Bayesian Network which is more well-known nowadays, all features are considered as attributes and are independent given the class.
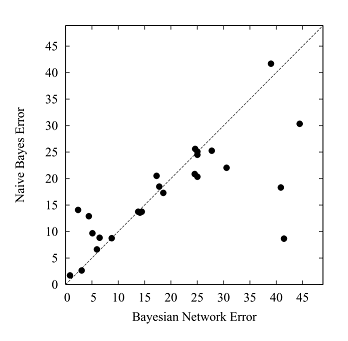
Bayesian networks and naive Bayesian network have their own advantages and disadvantages and we can see the performance comparison(done on 25 data sets mainly from the UCI repository) as depicted below:
![enter image description here]()
We can see that there are some points below the diagonal line representing the Naive Bayes performs better than the Bayesian Network on those datasets and some points above the diagonal line representing the reverse on some other datasets.
Bayesian Network is more complicated than the Naive Bayes but they almost perform equally well, and the reason is that all the datasets on which the Bayesian network performs worse than the Naive Bayes have more than 15 attributes. That's during the structure learning some crucial attributes are discarded.
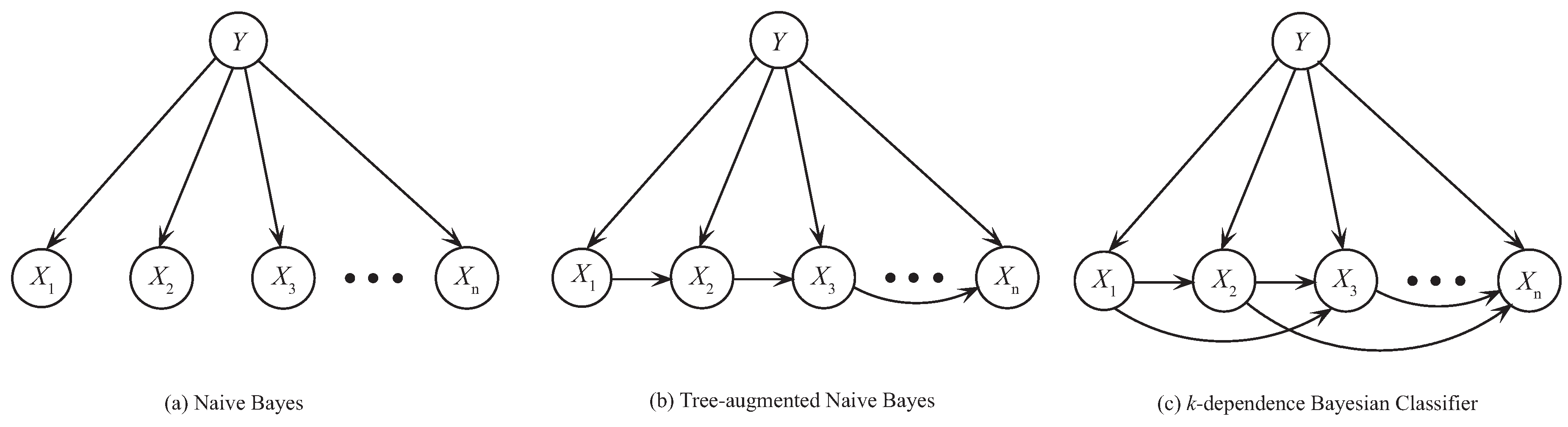
We can combine the two and add some connections between the features of the Naive Bayes and it becomes the tree augmented Naive Bayes or k-dependence Bayesian classifier.
![enter image description here]()
References:
1. Bayesian Network Classifiers