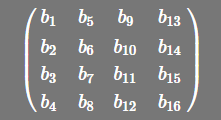I've been reading a lot about this, the more I read the more confused I get.
My understanding: In row-major rows are stored contiguously in memory, in column-major columns are stored contiguously in memory. So if we have a sequence of numbers [1, ..., 9] and we want to store them in a row-major matrix, we get:
|1, 2, 3|
|4, 5, 6|
|7, 8, 9|
while the column-major (correct me if I'm wrong) is:
|1, 4, 7|
|2, 5, 8|
|3, 6, 9|
which is effectively the transpose of the previous matrix.
My confusion: Well, I don't see any difference. If we iterate on both the matrices (by rows in the first one, and by columns in the second one) we'll cover the same values in the same order: 1, 2, 3, ..., 9
Even matrix multiplication is the same, we take the first contiguous elements and multiply them with the second matrix columns. So say we have the matrix M:
|1, 0, 4|
|5, 2, 7|
|6, 0, 0|
If we multiply the previous row-major matrix R with M, that is R x M we'll get:
|1*1 + 2*0 + 3*4, 1*5 + 2*2 + 3*7, etc|
|etc.. |
|etc.. |
If we multiply the column-major matrix C with M, that is C x M by taking the columns of C instead of its rows, we get exactly the same result from R x M
I'm really confused, if everything is the same, why do these two terms even exist? I mean even in the first matrix R, I could look at the rows and consider them columns...
Am I missing something? What does row-major vs col-major actually imply on my matrix math? I've always learned in my Linear Algebra classes that we multiply rows from the first matrix with columns from the second one, does that change if the first matrix was in column-major? do we now have to multiply its columns with columns from the second matrix like I did in my example or was that just flat out wrong?
Any clarifications are really appreciated!
EDIT: One of the other main sources of confusion I'm having is GLM... So I hover over its matrix type and hit F12 to see how it's implemented, there I see a vector array, so if we have a 3x3 matrix we have an array of 3 vectors. Looking at the type of those vectors I saw 'col_type' so I assumed that each one of those vectors represent a column, and thus we have a column-major system right?
Well, I don't know to be honest. I wrote this print function to compare my translation matrix with glm's, I see the translation vector in glm at the last row, and mine is at the last column...
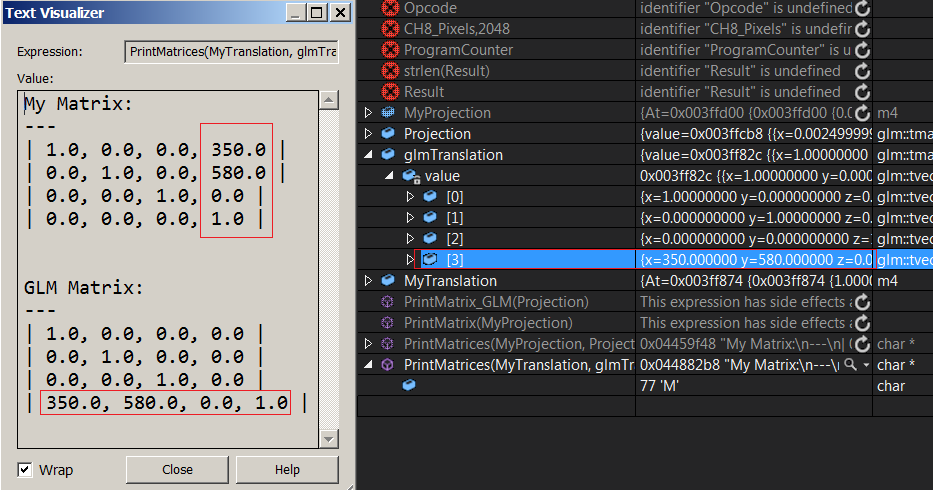
This adds nothing but more confusion. You can clearly see that each vector in glmTranslate matrix represents a row in the matrix. So... that means that the matrix is row-major right? What about my matrix? (I'm using a float array[16]) the translation values are in the last column, does that mean my matrix is column-major and I didn't now it? tries to stop head from spinning