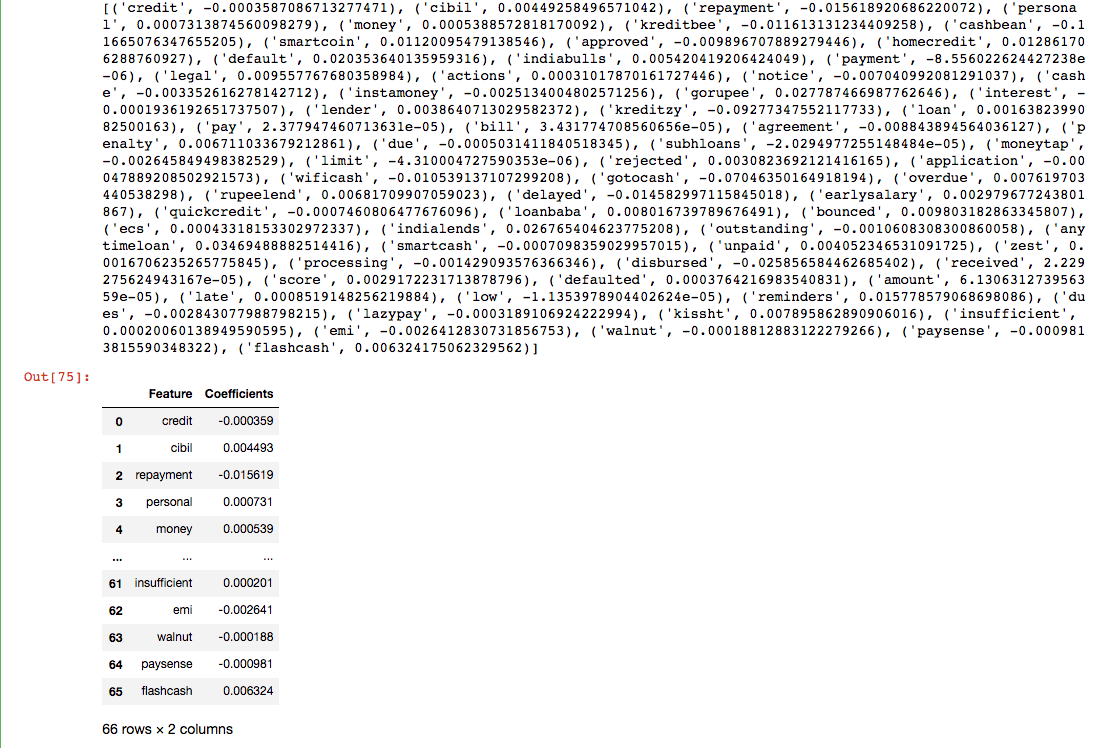
I'm trying to perform feature selection by evaluating my regressions coefficient outputs, and select the features with the highest magnitude coefficients. The problem is, I don't know how to get the respective features, as only coefficients are returned form the coef._ attribute. The documentation says:
Estimated coefficients for the linear regression problem. If multiple targets are passed during the fit (y 2D), this is a 2D array of shape (n_targets, n_features), while if only one target is passed, this is a 1D array of length n_features.
I am passing into my regression.fit(A,B), where A is a 2-D array, with tfidf value for each feature in a document. Example format:
"feature1" "feature2"
"Doc1" .44 .22
"Doc2" .11 .6
"Doc3" .22 .2
B are my target values for the data, which are just numbers 1-100 associated with each document:
"Doc1" 50
"Doc2" 11
"Doc3" 99
Using regression.coef_, I get a list of coefficients, but not their corresponding features! How can I get the features? I'm guessing I need to modfy the structure of my B targets, but I don't know how.