tl;dr
How do I pass data, e.g. the $BUILD_VERSION variable, between jobs in different pipelines in Gitlab CI?
So (in my case) this:
Pipeline 1 on push ect. Pipeline 2 after merge
`building` job ... `deploying` job
│ ▲
└─────── $BUILD_VERSION ─────────┘
Background
Consider the following example (full yml below):
building:
stage: staging
# only on merge requests
rules:
# execute when a merge request is open
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
when: always
- when: never
script:
- echo "BUILD_VERSION=1.2.3" > build.env
artifacts:
reports:
dotenv: build.env
deploying:
stage: deploy
# after merge request is merged
rules:
# execute when a branch was merged to staging
- if: $CI_COMMIT_BRANCH == $STAGING_BRANCH
when: always
- when: never
dependencies:
- building
script:
- echo $BUILD_VERSION
I have two stages, staging and deploy. The building job in staging builds the app and creates a "Review App" (no separate build stage for simplicity). The deploying job in deploy then uploads the new app.
The pipeline containing the building job runs whenever a merge request is opened. This way the app is built and the developer can click on the "Review App" icon in the merge request. The deploying job is run right after the merge request is merged. The idea is the following:
*staging* stage (pipeline 1) *deploy* stage (pipeline 2)
<open merge request> -> `building` job (and show) ... <merge> -> `deploying` job
│ ▲
└───────────── $BUILD_VERSION ───────────────┘
The problem for me is, that the staging/building creates some data, e.g. a $BUILD_VERSION. I want to have this $BUILD_VERSION in the deploy/deploying, e.g. for creating a new release via the Gitlab API.
So my question is: How do I pass the $BUILD_VERSION (and other data) from staging/building to deploy/deploying?
What I've tried so far
artifacts.reports.dotenv
The described case is more less handled in the gitlab docs in Pass an environment variable to another job. Also the yml file shown below is heavily inspired by this example. Still, it does not work.
The build.env artifact is created in building, but whenever the deploying job is executed, the build.env file gets removed as shown below in line 15: "Removing build.env". I tried to add build.env to the .gitignore but it still gets removed.
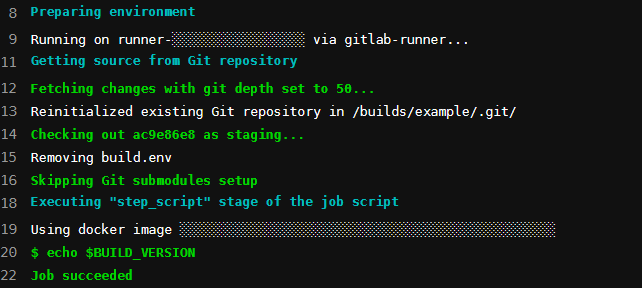
After hours of searching I found in this gitlab issue comment and this stackoverflow post that the artifacts.reports.dotenv doesn't work with the dependencies or the needs keywords.
Removing dependencies doesn't work. Using needs only doesn't work either. Using both is not allowed.
Does anyone know a way how to get this to work? I feel like this is the way it should work.
Getting the artifacts as a file
This answer of the stackoverflow post Gitlab ci cd removes artifact for merge requests suggests to use the build.env as a normal file. I also tried this. The (relevant) yml is the following:
building:
# ...
artifacts:
paths:
- build.env
deploying:
# ...
before_script:
- source build.env
The result is the same as above. The build.env gets removed. Then the source build.env command fails because build.env does not exist. (Doesn't matter if build.env is in the .gitignore or not, tested both)
Getting the artifacts from the API
I also found the answer of the stackoverflow post Use artifacts from merge request job in GitLab CI which suggests to use the API together with $CI_JOB_TOKEN. But since I need the artifacts in a non-merge-request pipeline, I cannot use the suggested CI_MERGE_REQUEST_REF_PATH.
I tried to use $CI_COMMIT_REF_NAME. The (important section of the) yml is then:
deploying:
# ...
script:
- url=$CI_API_V4_URL/projects/jobs/artifacts/$CI_COMMIT_REF_NAME/download?job=building
- echo "Downloading $url"
- 'curl --header "JOB-TOKEN: ${CI_JOB_TOKEN}" --output $url'
# ...
But this the API request gets rejected with "404 Not Found". Since commit SHAs are not supported, $CI_COMMIT_BEFORE_SHA or $CI_COMMIT_SHA do not work either.
Using needs
Update: I found the section Artifact downloads between pipelines in the same project in the gitlab docs which is exactly what I want. But: I can't get it to work.
The yml looks like the following after more less copying from the docs:
building:
# ...
artifacts:
paths:
- version
expire_in: never
deploying:
# ...
needs:
- project: $CI_PROJECT_PATH
job: building
ref: staging # building runs on staging branch, main doesn't work either
artifacts: true
Now the deploying job instantly fails and I get the following error banner:

I tried to set artifacts.expire_in = never (as shown) but I still get the same error. Also in Settings > CI/CD > Artifacts "Keep artifacts from most recent successful jobs" is selected. So the artifact should be present. What did I miss here? This should work according to the docs!
I hope somebody can help me on getting the $BUILD_VERSION to the deploying job. If there are other ways than the ones I've tried, I'm very happy to hear them. Thanks in advance.
The example .gitlab-ci.yml:
stages:
- staging
- deploy
building:
tags:
- docker
image: bash
stage: staging
rules:
- if: ($CI_PIPELINE_SOURCE == "merge_request_event") && $CI_MERGE_REQUEST_TARGET_BRANCH_NAME == "staging"
when: always
- when: never
script:
- echo "BUILD_VERSION=1.2.3" > build.env
artifacts:
reports:
dotenv: build.env
environment:
name: Example
url: https://example.com
deploying:
tags:
- docker
image: bash
stage: deploy
rules:
- if: $CI_COMMIT_BRANCH == "staging"
when: always
- when: never
dependencies:
- building
script:
echo $BUILD_VERSION
reports: dotenv:and dopaths:instead. Then keepdependencies:exactly as you have it to restore build.env in the deploy pipeline – Vizierateymlfrom my answer and changed only theartifacts.reportsofbuildingtoartifacts.paths: -build.env– Mmbuildingstage on some builds, and trying to pass the data between unrelated pipelines. See my answer – Vizierate