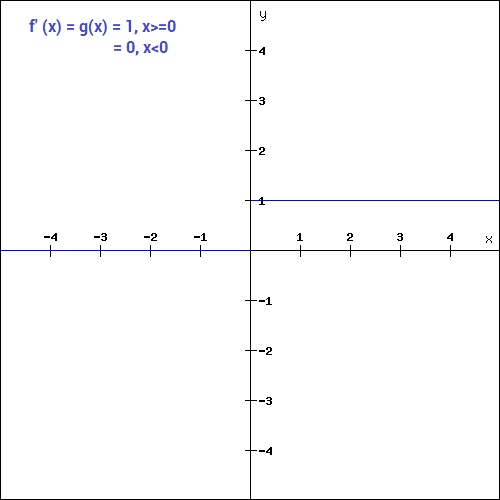
While ReLU is common, the derivative can be confusing, part of the reason is that it is in theory not defined at x=0, in practice, we just use f'(x=0)=0.
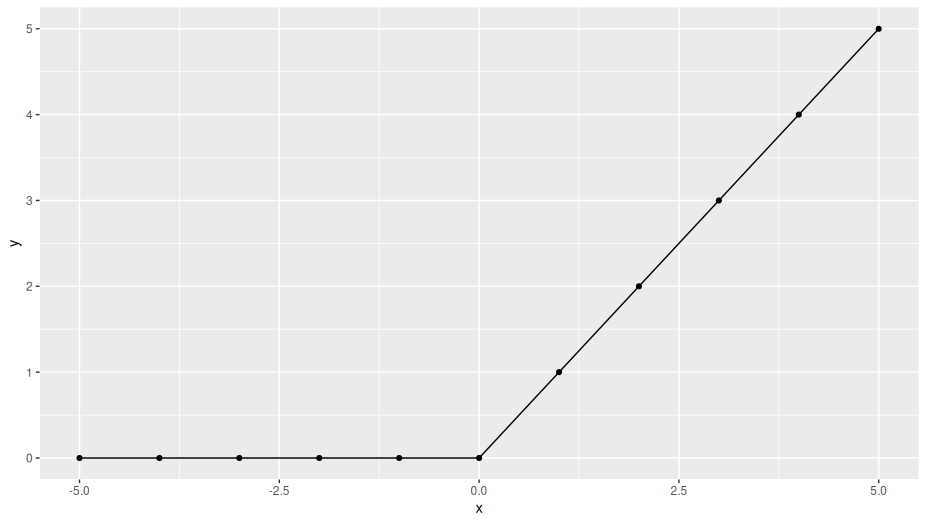
This is assuming by ReLU (Rectified Linear Unit) is meant y=max(0,x). This function looks like so:
![ReLU]()
For the part where x>0 it is fairly easy to see what the derivative is. For every 1 that x increases, y increases by 1 (as we can also see from the function definition ofcourse), the derivative here is thus f'(x>0)=1.
For the part where x<0 it is fairly easy to see that the line is level, i.e. the slope is flat or 0. Here we thus have f'(x<0)=0.
The tricky (but not terribly important in practice) part comes at x=0. The Left-Hand Side (LHS) and Right-Hand Side (RHS) of the derivative here are not equal, in theory it is thus undefined.
In practice we normally just use: f'(x=0)=0. But you can also use f'(x=0)=1, try it out.
Why can we just do that? Remember that we use these derivates to scale the weight updates. Normally the weight updates are scaled in all kinds of other ways (learning rate, etc.). Scaling by 0 of course does mean that no update is made, this also happens e.g. with Hinton's dropout. Remember also that what you're computing of is the derivative of the error term (at the output layer), if the error term is 0...
{kind=link}