I am working on Retinal fundus images.The image consists of a circular retina on a black background. With OpenCV, I have managed to get a contour which surrounds the whole circular Retina. What I need is to crop out the circular retina from the black background.
How to crop the internal area of a contour?
![]()
![]()
what do you mean by cropping? images are always rectangular, so what you can do is either create a mask and do your following operations (processing/rendering) only on the masked pixels. Or you can crop the image so that it is represented by the bounding box of the retina, which might be much smaller than the original image, but will still have some black parts (since the retina isnt rectangular). Or you could crop to the maximum rectangular region INSIDE the retina, which wouldnt have any black background pixels left but will remove parts of the retina too. Which one do you want? –
Jovian
If it is the last scenario please try #21410949 –
Jovian
It is unclear in your question whether you want to actually crop out the information that is defined within the contour or mask out the information that isn't relevant to the contour chosen. I'll explore what to do in both situations.
Masking out the information
Assuming you ran cv2.findContours on your image, you will have received a structure that lists all of the contours available in your image. I'm also assuming that you know the index of the contour that was used to surround the object you want. Assuming this is stored in idx, first use cv2.drawContours to draw a filled version of this contour onto a blank image, then use this image to index into your image to extract out the object. This logic masks out any irrelevant information and only retain what is important - which is defined within the contour you have selected. The code to do this would look something like the following, assuming your image is a grayscale image stored in img:
import numpy as np
import cv2
img = cv2.imread('...', 0) # Read in your image
# contours, _ = cv2.findContours(...) # Your call to find the contours using OpenCV 2.4.x
_, contours, _ = cv2.findContours(...) # Your call to find the contours
idx = ... # The index of the contour that surrounds your object
mask = np.zeros_like(img) # Create mask where white is what we want, black otherwise
cv2.drawContours(mask, contours, idx, 255, -1) # Draw filled contour in mask
out = np.zeros_like(img) # Extract out the object and place into output image
out[mask == 255] = img[mask == 255]
# Show the output image
cv2.imshow('Output', out)
cv2.waitKey(0)
cv2.destroyAllWindows()
If you actually want to crop...
If you want to crop the image, you need to define the minimum spanning bounding box of the area defined by the contour. You can find the top left and lower right corner of the bounding box, then use indexing to crop out what you need. The code will be the same as before, but there will be an additional cropping step:
import numpy as np
import cv2
img = cv2.imread('...', 0) # Read in your image
# contours, _ = cv2.findContours(...) # Your call to find the contours using OpenCV 2.4.x
_, contours, _ = cv2.findContours(...) # Your call to find the contours
idx = ... # The index of the contour that surrounds your object
mask = np.zeros_like(img) # Create mask where white is what we want, black otherwise
cv2.drawContours(mask, contours, idx, 255, -1) # Draw filled contour in mask
out = np.zeros_like(img) # Extract out the object and place into output image
out[mask == 255] = img[mask == 255]
# Now crop
(y, x) = np.where(mask == 255)
(topy, topx) = (np.min(y), np.min(x))
(bottomy, bottomx) = (np.max(y), np.max(x))
out = out[topy:bottomy+1, topx:bottomx+1]
# Show the output image
cv2.imshow('Output', out)
cv2.waitKey(0)
cv2.destroyAllWindows()
The cropping code works such that when we define the mask to extract out the area defined by the contour, we additionally find the smallest horizontal and vertical coordinates which define the top left corner of the contour. We similarly find the largest horizontal and vertical coordinates that define the bottom left corner of the contour. We then use indexing with these coordinates to crop what we actually need. Note that this performs cropping on the masked image - that is the image that removes everything but the information contained within the largest contour.
Note with OpenCV 3.x
It should be noted that the above code assumes you are using OpenCV 2.4.x. Take note that in OpenCV 3.x, the definition of cv2.findContours has changed. Specifically, the output is a three element tuple output where the first image is the source image, while the other two parameters are the same as in OpenCV 2.4.x. Therefore, simply change the cv2.findContours statement in the above code to ignore the first output:
_, contours, _ = cv2.findContours(...) # Your call to find contours
@RedetGetachew - No, the coordinates are not swapped. The output of
np.where provides row locations in x and column locations in y that are non-zero. Therefore, indexing into the array is correct. Please actually test out your changes before suggesting an edit. –
Monson In OpenCV it's the other way around,
x stands for column location and y for row locations, that's why they may appear to be swapped. –
Unintentional @JoãoCartucho no not if you use
np.where. You're fine with the first approach in that case but not the second. –
Monson how to apply this for colored images ? –
Tabatha
@DavidIbrahim The code already converts the image to grayscale so colour images can still work. –
Monson
@rayryeng-ReinstateMonica I mean to apply this cropping on BGR Images without converting it to gray, I tried it but it only copied the B values from the Image –
Tabatha
@DavidIbrahim Still do it on the gray converted image but you'll need to duplicate the mask so that there are three channels, each with the same mask contents then index. I can modify my post later to address doing thus in colour but it's almost the same process. –
Monson
Here's another approach to crop out a rectangular ROI. The main idea is to find the edges of the retina using Canny edge detection, find contours, and then extract the ROI using Numpy slicing. Assuming you have an input image like this:

Extracted ROI

import cv2
# Load image, convert to grayscale, and find edges
image = cv2.imread('1.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY)[1]
# Find contour and sort by contour area
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
# Find bounding box and extract ROI
for c in cnts:
x,y,w,h = cv2.boundingRect(c)
ROI = image[y:y+h, x:x+w]
break
cv2.imshow('ROI',ROI)
cv2.imwrite('ROI.png',ROI)
cv2.waitKey()
This is a pretty simple way. Mask the image with transparency.
- Read the image
- Make a grayscale version.
- Otsu Threshold
- Apply morphology open and close to thresholded image as a mask
- Put the mask into the alpha channel of the input
- Save the output
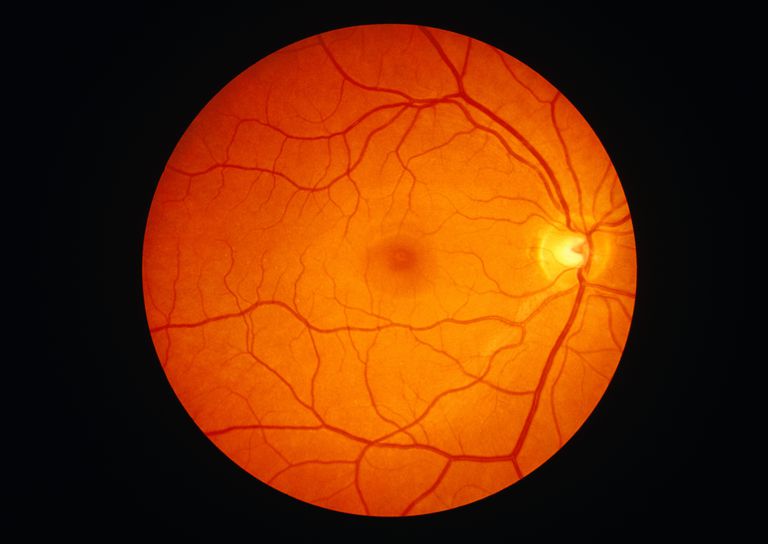
Input
Code
import cv2
import numpy as np
# load image as grayscale
img = cv2.imread('retina.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# threshold input image using otsu thresholding as mask and refine with morphology
ret, mask = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
kernel = np.ones((9,9), np.uint8)
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
mask = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel)
# put mask into alpha channel of result
result = img.copy()
result = cv2.cvtColor(result, cv2.COLOR_BGR2BGRA)
result[:, :, 3] = mask
# save resulting masked image
cv2.imwrite('retina_masked.png', result)
Output
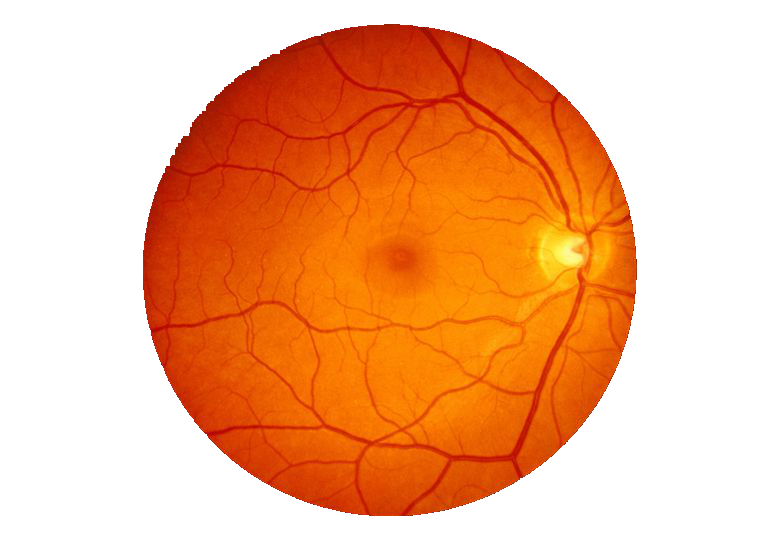
This only removes the background - this doesn't crop as per the original question –
Monson
Yes, you are right. I must have misread the question back then. –
Allegraallegretto
© 2022 - 2024 — McMap. All rights reserved.