This is why I'm asking this question: Last year I made some C++ code to compute posterior probabilities for a particular type of model (described by a Bayesian network). The model worked pretty well and some other people started to use my software. Now I want to improve my model. Since I'm already coding slightly different inference algorithms for the new model, I decided to use python because runtime wasn't critically important and python may let me make more elegant and manageable code.
Usually in this situation I'd search for an existing Bayesian network package in python, but the inference algorithms I'm using are my own, and I also thought this would be a great opportunity to learn more about good design in python.
I've already found a great python module for network graphs (networkx), which allows you to attach a dictionary to each node and to each edge. Essentially, this would let me give nodes and edges properties.
For a particular network and it's observed data, I need to write a function that computes the likelihood of the unassigned variables in the model.
For instance, in the classic "Asia" network (http://www.bayesserver.com/Resources/Images/AsiaNetwork.png), with the states of "XRay Result" and "Dyspnea" known, I need to write a function to compute the likelihood that the other variables have certain values (according to some model).
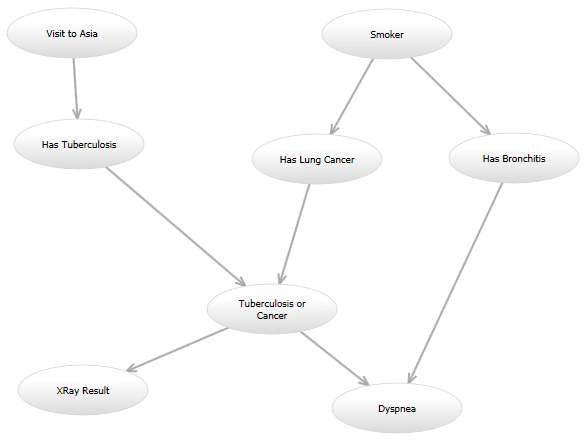{kind=link}
Here is my programming question: I'm going to try a handful of models, and in the future it's possible I'll want to try another model after that. For instance, one model might look exactly like the Asia network. In another model, a directed edge might be added from "Visit to Asia" to "Has Lung Cancer." Another model might use the original directed graph, but the probability model for the "Dyspnea" node given the "Tuberculosis or Cancer" and "Has Bronchitis" nodes might be different. All of these models will compute the likelihood in a different way.
All the models will have substantial overlap; for instance, multiple edges going into an "Or" node will always make a "0" if all inputs are "0" and a "1" otherwise. But some models will have nodes that take on integer values in some range, while others will be boolean.
In the past I've struggled with how to program things like this. I'm not going to lie; there's been a fair amount of copied and pasted code and sometimes I've needed to propagate changes in a single method to multiple files. This time I really want to spend the time to do this the right way.
Some options:
- I was already doing this the right way. Code first, ask questions later. It's faster to copy and paste the code and have one class for each model. The world is a dark and disorganized place...
- Each model is its own class, but also a subclass of a general BayesianNetwork model. This general model will use some functions that are going to be overridden. Stroustrup would be proud.
- Make several functions in the same class that compute the different likelihoods.
- Code a general BayesianNetwork library and implement my inference problems as specific graphs read in by this library. The nodes and edges should be given properties like "Boolean" and "OrFunction" which, given known states of the parent node, can be used to compute the probabilities of different outcomes. These property strings, like "OrFunction" could even be used to look up and call the right function. Maybe in a couple of years I'll make something similar to the 1988 version of Mathematica!
Thanks a lot for your help.
Update: Object oriented ideas help a lot here (each node has a designated set of predecessor nodes of a certain node subtype, and each node has a likelihood function that computes its likelihood of different outcome states given the states of the predecessor nodes, etc.). OOP FTW!