This is a very difficult problem about how to maneuver a spaceship that can both translate and rotate in 3D, for a space game.
The spaceship has n jets placing in various positions and directions.
Transformation of i-th jet relative to the CM of spaceship is constant = Ti.
- Transformation is a tuple of position and orientation (quaternion or matrix 3x3 or, less preferable, Euler angles).
- A transformation can also be denoted by a single matrix 4x4.
In other words, all jet are glued to the ship and cannot rotate.
A jet can exert force to the spaceship only in direction of its axis (green).
As a result of glue, the axis rotated along with the spaceship.

All jets can exert force (vector,Fi) at a certain magnitude (scalar,fi) :
i-th jet can exert force (Fi= axis x fi) only within range min_i<= fi <=max_i.
Both min_i and max_i are constant with known value.
To be clear, unit of min_i,fi,max_i is Newton.
Ex. If the range doesn't cover 0, it means that the jet can't be turned off.
The spaceship's mass = m and inertia tensor = I.
The spaceship's current transformation = Tran0, velocity = V0, angularVelocity = W0.
The spaceship physic body follows well-known physic rules :-
Torque=r x F
F=ma
angularAcceleration = I^-1 x Torque
linearAcceleration = m^-1 x F
I is different for each direction, but for the sake of simplicity, it has the same value for every direction (sphere-like). Thus, I can be thought as a scalar instead of matrix 3x3.
Question
How to control all jets (all fi) to land the ship with position=0 and angle=0?
Math-like specification: Find function of fi(time) that take minimum time to reach position=(0,0,0), orient=identity with final angularVelocity and velocity = zero.
More specifically, what are names of technique or related algorithms to solve this problem?
My research (1 dimension)
If the universe is 1D (thus, no rotation), the problem will be easy to solve.
( Thank Gavin Lock, https://mcmap.net/q/450599/-ai-of-spaceship-39-s-propulsion-control-the-force-to-land-a-ship-at-x-0-and-v-0 )
First, find the value MIN_BURN=sum{min_i}/m and MAX_BURN=sum{max_i}/m.
Second, think in opposite way, assume that x=0 (position) and v=0 at t=0,
then create two parabolas with x''=MIN_BURN and x''=MAX_BURN.
(The 2nd derivative is assumed to be constant for a period of time, so it is parabola.)
The only remaining work is to join two parabolas together.
The red dash line is where them join.

In the period of time that x''=MAX_BURN, all fi=max_i.
In the period of time that x''=MIN_BURN, all fi=min_i.
It works really well for 1D, but in 3D, the problem is far more harder.
Note:
Just a rough guide pointing me to a correct direction is really appreciated.
I don't need a perfect AI, e.g. it can take a little more time than optimum.
I think about it for more than 1 week, still find no clue.
Other attempts / opinions
- I don't think machine learning like neural network is appropriate for this case.
- Boundary-constrained-least-square-optimisation may be useful but I don't know how to fit my two hyper-parabola to that form of problem.
- This may be solved by using many iterations, but how?
- I have searched NASA's website, but not find anything useful.
- The feature may exist in "Space Engineer" game.
- Commented by Logman: Knowledge in mechanical engineering may help.
- Commented by AndyG: It is a motion planning problem with nonholonomic constraints. It could be solved by Rapidly exploring random tree (RRTs), theory around Lyapunov equation, and Linear quadratic regulator.
- Commented by John Coleman: This seems more like optimal control than AI.
Edit: "Near-0 assumption" (optional)
- In most case, AI (to be designed) run continuously (i.e. called every time-step).
- Thus, with the AI's tuning,
Tran0is usually near-identity,V0andW0are usually not so different from 0, e.g.|Seta0|<30 degree,|W0|<5 degree per time-step. - I think that AI based on this assumption would work OK in most case. Although not perfect, it can be considered as a correct solution (I started to think that without this assumption, this question might be too hard).
- I faintly feel that this assumption may enable some tricks that use some "linear"-approximation.
The 2nd Alternative Question - "Tune 12 Variables" (easier)
The above question might also be viewed as followed :-
I want to tune all six values and six values' (1st-derivative) to be 0, using lowest amount of time-steps.
Here is a table show a possible situation that AI can face:-
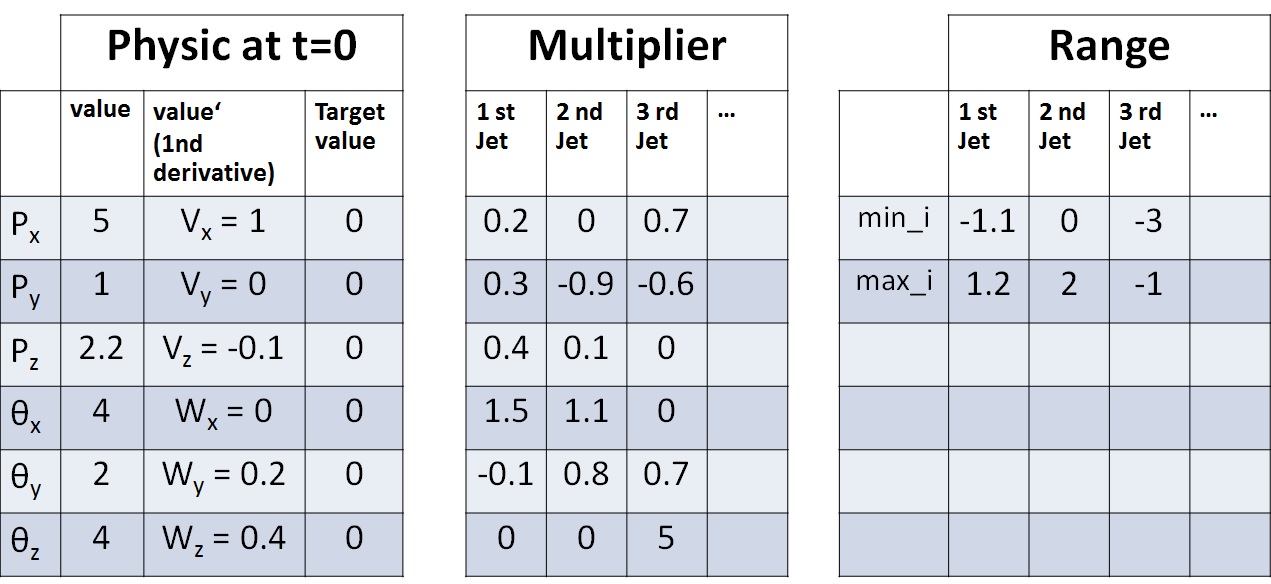
The Multiplier table stores inertia^-1 * r and mass^-1 from the original question.
The Multiplier and Range are constant.
Each timestep, the AI will be asked to pick a tuple of values fi that must be in the range [min_i,max_i] for every i+1-th jet.
Ex. From the table, AI can pick (f0=1,f1=0.1,f2=-1).
Then, the caller will use fi to multiply with the Multiplier table to get values''.
Px'' = f0*0.2+f1*0.0+f2*0.7
Py'' = f0*0.3-f1*0.9-f2*0.6
Pz'' = ....................
SetaX''= ....................
SetaY''= ....................
SetaZ''= f0*0.0+f1*0.0+f2*5.0
After that, the caller will update all values' with formula values' += values''.
Px' += Px''
.................
SetaZ' += SetaZ''
Finally, the caller will update all values with formula values += values'.
Px += Px'
.................
SetaZ += SetaZ'
AI will be asked only once for each time-step.
The objective of AI is to return tuples of fi (can be different for different time-step), to make Px,Py,Pz,SetaX,SetaY,SetaZ,Px',Py',Pz',SetaX',SetaY',SetaZ' = 0 (or very near),
by using least amount of time-steps as possible.
I hope providing another view of the problem will make it easier.
It is not the exact same problem, but I feel that a solution that can solve this version can bring me very close to the answer of the original question.
An answer for this alternate question can be very useful.
The 3rd Alternative Question - "Tune 6 Variables" (easiest)
This is a lossy simplified version of the previous alternative.
The only difference is that the world is now 2D, Fi is also 2D (x,y).
Thus I have to tune only Px,Py,SetaZ,Px',Py',SetaZ'=0, by using least amount of time-steps as possible.
An answer to this easiest alternative question can be considered useful.
max_i<->min_i). I doubt it might be changed more than once in 3D ( and the value can be in betweenmin_iandmax_i, only this part can be fit into your model). Thus, it is not that simple. – Neighmin_i,max_i] is allowed. – Neighmin_irestriction. I would also add that there may be many configurations without a solution, and that there be at least 2 jets for there to be a solution. – Dammax_iconstraint can also be ignored. – DamFican be changed at will with no delay, if that is what you asked. For simplicity again, there is no fuel limit. - a jet can exertmax_ias long as AI wants. ..... I agree that sometimes there is no solution. In those cases, AI should do "its best". ..... "pulse rate modulation" = on/off quickly and repeatly? Concept of "on/off" here is replaced by adjustingFifreely within the range, and the range [min_i,max_i] doesn't have to cover0. .... Thank, I will improve the question. – Neighmin_iis meaningless by running jet1 atmin_ifor 1 sec is the same as running jet1 atmin_i / 2for two seconds. The importance is that jets can be turned on/off and it is not the min thrust a jet can produce but the balance of thrust between all jets. If you need 1/100th of the power of jet2 from jet1 you fire jet1 for 1/100sec to jet2 1sec. Also if there was a error range in end condition zero V and w (angular) Zero makes it too hard. – Dammin_i,max_i] = [1,2], the jet can't be "turned off" (Fi=0) in your definition because it will become out of range. I understand your trick. Sorry if I wasn't clear. I will improve it. ......... I don't understand "If you need 1/100th of the power of jet2 ... 1sec". ..... Yes, it is also too hard for me. – Neighmin_iwere the minimal thrust when turned on. Besides, unless they are switching off after landing, you should consider the friction between the surface of the planet and the spaceship too ;) – Hebelmin_iwill not make designing the AI much harder. 2. Such rule will make the AI work OK even while some jets are partially malfunctioning. 3. Such rule will allow me to adapt the AI to situation that external force != 0. ........ Yes, I will finally have to cope with that friction later. The question is already too hard, so I just exclude that feature, i.e. I agree. – Neigh