I've come across research publications and Q&A's discussing a need for inspecting RNN weights; some related answers are in the right direction, suggesting get_weights() - but how do I actually visualize the weights meaningfully? Namely, LSTMs and GRUs have gates, and all RNNs have channels that serve as independent feature extractors - so how do I (1) fetch per-gate weights, and (2) plot them in an informative manner?
How to visualize RNN/LSTM weights in Keras/TensorFlow?
Asked Answered
Keras/TF build RNN weights in a well-defined order, which can be inspected from the source code or via layer.__dict__ directly - then to be used to fetch per-kernel and per-gate weights; per-channel treatment can then be employed given a tensor's shape. Below code & explanations cover every possible case of a Keras/TF RNN, and should be easily expandable to any future API changes.
Also see visualizing RNN gradients, and an application to RNN regularization; unlike in the former post, I won't be including a simplified variant here, as it'd still be rather large and complex per the nature of weight extraction and organization; instead, simply view relevant source code in the repository (see next section).
Code source: See RNN (this post included w/ bigger images), my repository; included are:
- Activations visualization
- Weights visualization
- Activations gradients visualization
- Weights gradients visualization
- Docstrings explaining all functionality
- Support for Eager, Graph, TF1, TF2, and
from keras&from tf.keras - Greater visual customizability than shown in examples
Visualization methods:
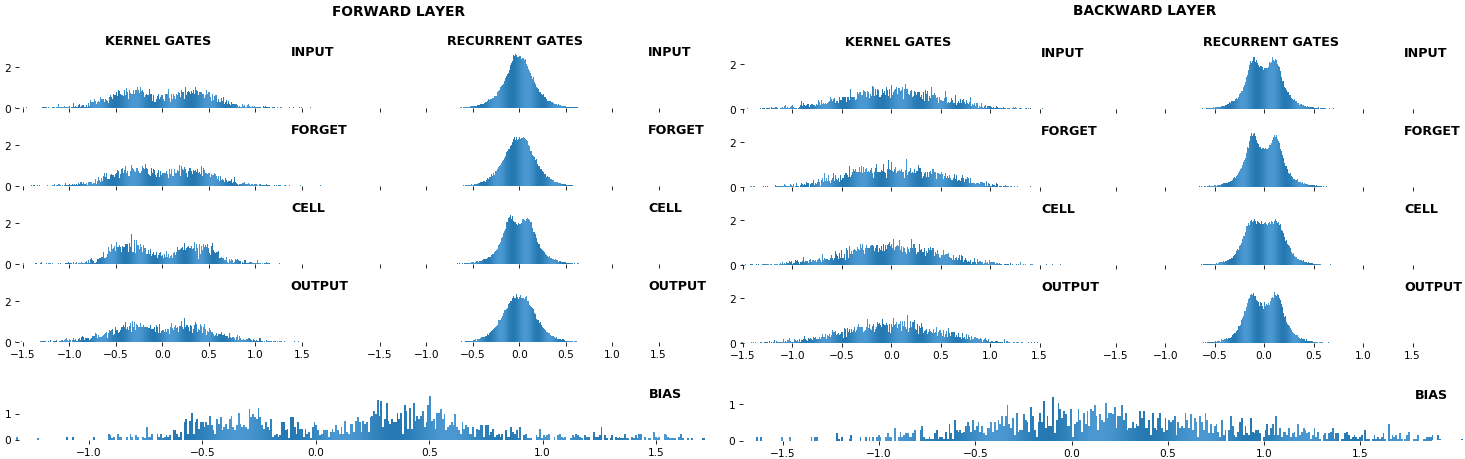
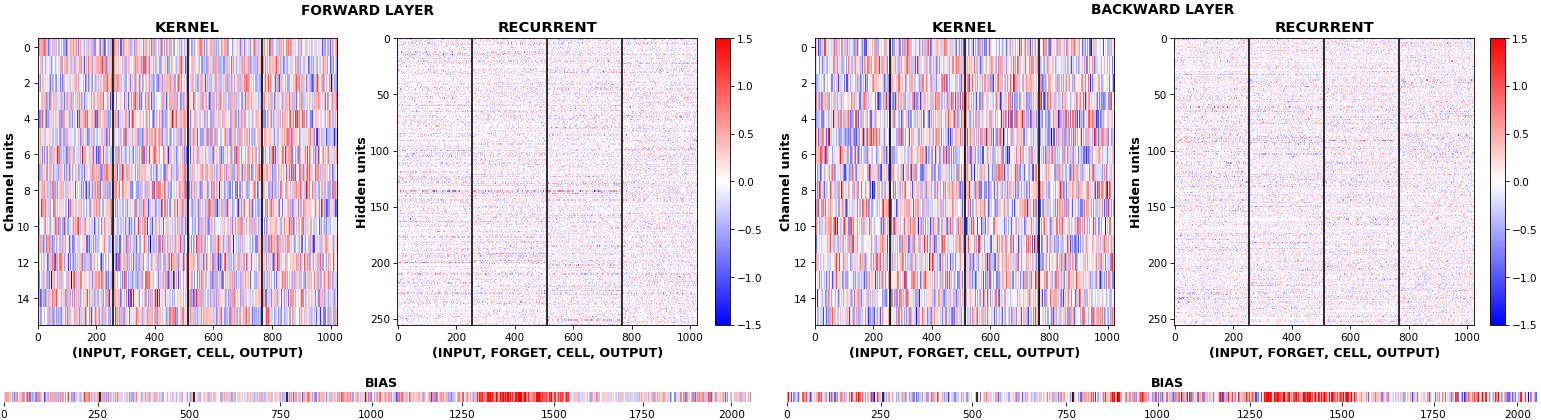
- 2D heatmap: plot weight distributions per gate, per kernel, per direction; clearly shows kernel-to-hidden relations
- histogram: plot weight distributions per gate, per kernel, per direction; loses context info
EX 1: uni-LSTM, 256 units, weights -- batch_shape = (16, 100, 20) (input)
rnn_histogram(model, 'lstm', equate_axes=False, show_bias=False)
rnn_histogram(model, 'lstm', equate_axes=True, show_bias=False)
rnn_heatmap(model, 'lstm')
- Top plot is a histogram subplot grid, showing weight distributions per kernel, and within each kernel, per gate
- Second plot sets
equate_axes=Truefor an even comparison across kernels and gates, improving quality of comparison, but potentially degrading visual appeal - Last plot is a heatmap of the same weights, with gate separations marked by vertical lines, and bias weights also included
- Unlike histograms, the heatmap preserves channel/context information: input-to-hidden and hidden-to-hidden transforming matrices can be clearly distinguished
- Note the large concentration of maximal values at the Forget gate; as trivia, in Keras (and usually), bias gates are all initialized to zeros, except the Forget bias, which is initialized to ones



EX 2: bi-CuDNNLSTM, 256 units, weights -- batch_shape = (16, 100, 16) (input)
rnn_histogram(model, 'bidir', equate_axes=2)
rnn_heatmap(model, 'bidir', norm=(-.8, .8))
- Bidirectional is supported by both; biases included in this example for histograms
- Note again the bias heatmaps; they no longer appear to reside in the same locality as in EX 1. Indeed,
CuDNNLSTM(andCuDNNGRU) biases are defined and initialized differently - something that can't be inferred from histograms
EX 3: uni-CuDNNGRU, 64 units, weights gradients -- batch_shape = (16, 100, 16) (input)
rnn_heatmap(model, 'gru', mode='grads', input_data=x, labels=y, cmap=None, absolute_value=True)
- We may wish to visualize gradient intensity, which can be done via
absolute_value=Trueand a greyscale colormap - Gate separations are apparent even without explicit separating lines in this example:
Newis the most active kernel gate (input-to-hidden), suggesting more error correction on permitting information flowResetis the least active recurrent gate (hidden-to-hidden), suggesting least error correction on memory-keeping

BONUS EX: LSTM NaN detection, 512 units, weights -- batch_shape = (16, 100, 16) (input)
- Both the heatmap and the histogram come with built-in NaN detection - kernel-, gate-, and direction-wise
- Heatmap will print NaNs to console, whereas histogram will mark them directly on the plot
- Both will set NaN values to zero before plotting; in example below, all related non-NaN weights were already zero

First of all, great work! However looking through this I feel like this is a great tool for debugging monitoring sequential models for any undesirable behaviors/errors. But is there an interpretability component here? For example, can you extract insights from the visualizations of what the model has learned? –
Backbreaking
@Backbreaking Thanks; excellent question - but as much as I myself seek it, no satisfactory answer. The principal difference between timeseries and images is that former models a process, whereas latter models a state - so signal information is inherently more complex. Signal analysis, surely, is the main toolkit, but not complete for NNs -- this 2019 book is the best material I found on the topic. (Clarification: "signal" assuming working w/ signal data - else for NLP & word embeddings, stuff complicates yet further) –
Ancylostomiasis
@Backbreaking The iNNvestigate repo is better suited for interpretability, and is actually authored by the linked textbook's authors –
Ancylostomiasis
Awesome! I really liked the topics in the book. Thanks a lot for sharing that!!! Wasn't aware of it before. Will also check out the repo. :) –
Backbreaking
© 2022 - 2024 — McMap. All rights reserved.