I want to find the parameters of ParamGridBuilder that make the best model in CrossValidator in Spark 1.4.x,
In Pipeline Example in Spark documentation, they add different parameters (numFeatures, regParam) by using ParamGridBuilder in the Pipeline. Then by the following line of code they make the best model:
val cvModel = crossval.fit(training.toDF)
Now, I want to know what are the parameters (numFeatures, regParam) from ParamGridBuilder that produces the best model.
I already used the following commands without success:
cvModel.bestModel.extractParamMap().toString()
cvModel.params.toList.mkString("(", ",", ")")
cvModel.estimatorParamMaps.toString()
cvModel.explainParams()
cvModel.getEstimatorParamMaps.mkString("(", ",", ")")
cvModel.toString()
Any help?
Thanks in advance,
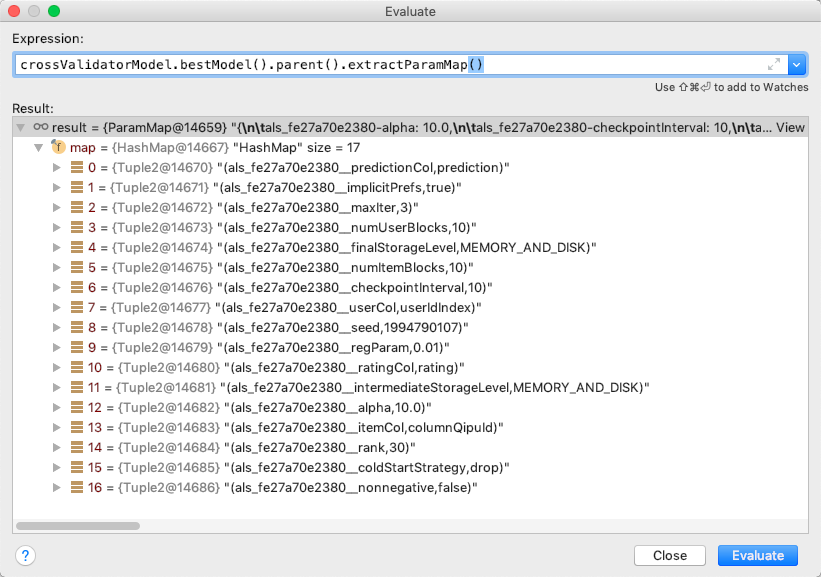
CrossValidatorModelinstance. – GentlemancvModel.bestModel, please see my answer below – Steverson