Something the other answers are missing is that it must be understood that Authentication and Authorization in the context of RFC 2616 refers ONLY to the HTTP Authentication protocol of RFC 2617. Authentication by schemes outside of RFC2617 is not supported in HTTP status codes and are not considered when deciding whether to use 401 or 403.
Brief and Terse
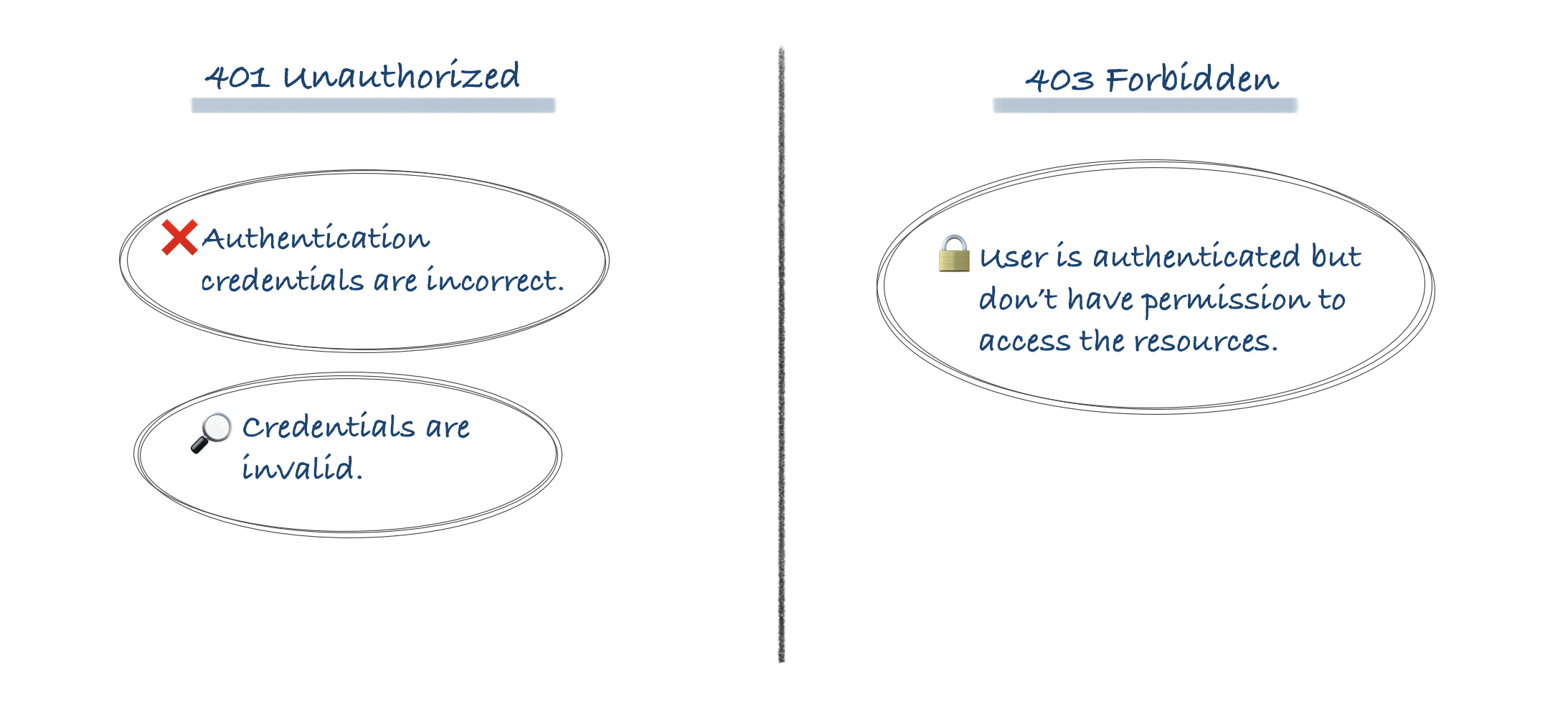
Unauthorized indicates that the client is not RFC2617 authenticated and the server is initiating the authentication process. Forbidden indicates either that the client is RFC2617 authenticated and does not have authorization or that the server does not support RFC2617 for the requested resource.
Meaning if you have your own roll-your-own login process and never use HTTP Authentication, 403 is always the proper response and 401 should never be used.
Detailed and In-Depth
From RFC2616
10.4.2 401 Unauthorized
The request requires user authentication. The response MUST include a WWW-Authenticate header field (section 14.47) containing a challenge applicable to the requested resource. The client MAY repeat the request with a suitable Authorization header field (section 14.8).
and
10.4.4 403 Forbidden
The server understood the request but is refusing to fulfil it. Authorization will not help and the request SHOULD NOT be repeated.
The first thing to keep in mind is that "Authentication" and "Authorization" in the context of this document refer specifically to the HTTP Authentication protocols from RFC 2617. They do not refer to any roll-your-own authentication protocols you may have created using login pages, etc. I will use "login" to refer to authentication and authorization by methods other than RFC2617
So the real difference is not what the problem is or even if there is a solution. The difference is what the server expects the client to do next.
401 indicates that the resource can not be provided, but the server is REQUESTING that the client log in through HTTP Authentication and has sent reply headers to initiate the process. Possibly there are authorizations that will permit access to the resource, possibly there are not, but let's give it a try and see what happens.
403 indicates that the resource can not be provided and there is, for the current user, no way to solve this through RFC2617 and no point in trying. This may be because it is known that no level of authentication is sufficient (for instance because of an IP blacklist), but it may be because the user is already authenticated and does not have authority. The RFC2617 model is one-user, one-credentials so the case where the user may have a second set of credentials that could be authorized may be ignored. It neither suggests nor implies that some sort of login page or other non-RFC2617 authentication protocol may or may not help - that is outside the RFC2616 standards and definition.
Edit: RFC2616 is obsolete, see RFC7231 and RFC7235.