I will try to explain the page rendering process in depth. Kindly note that I am not focusing on the request-response process as the OP has asked in the question.
Once the server supplies the resources (HTML, CSS, JS, images, etc.) to the browser it undergoes the below process:
Parsing - HTML, CSS, JS
Rendering - Construct DOM Tree → Render Tree → Layout of Render Tree → Painting the render tree
- The rendering engine starts getting the contents of the requested document from the networking layer. This will usually be done in 8kB chunks.
- A DOM tree is built out of the broken response.
- New requests are made to the server for each new resource that is found in the HTML source (typically images, style sheets, and JavaScript files).
- At this stage the browser marks the document as interactive and starts parsing scripts that are in "deferred" mode: those that should be executed after the document is parsed. The document state is set to "complete" and a "load" event is fired.
- Each CSS file is parsed into a StyleSheet object, where each object contains CSS rules with selectors and objects corresponding CSS grammar. The tree built is called CSSCOM.
- On top of DOM and CSSOM, a rendering tree is created, which is a set of objects to be rendered. Each of the rendering objects contains its corresponding DOM object (or a text block) plus the calculated styles. In other words, the render tree describes the visual representation of a DOM.
- After the construction of the render tree it goes through a "layout" process. This means giving each node the exact coordinates where it should appear on the screen.
- The next stage is painting–the render tree will be traversed and each node will be painted using the UI backend layer.
- Repaint: When changing element styles which don't affect the element's position on a page (such as background-color, border-color, visibility), the browser just repaints the element again with the new styles applied (that means a "repaint" or "restyle" is happening).
- Reflow: When the changes affect document contents or structure, or element position, a reflow (or relayout) happens.
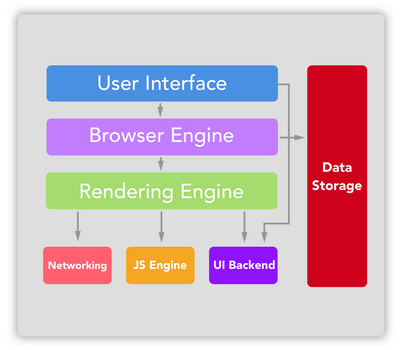
What is the internal structure of a web browser?
![browser structure]()
To understand the page rendering process explained in the above points we also need to understand the structure of a web browser.
User interface: The user interface includes the address bar, back/forward button, bookmarking menu, etc. Every part of the browser display except the window where you see the requested page.
Browser engine: The browser engine marshals actions between the UI and the rendering engine.
Rendering engine: The rendering engine is responsible for displaying requested content. For example if the requested content is HTML, the rendering engine parses HTML and CSS, and displays the parsed content on the screen.
Networking: The networking handles network calls such as HTTP requests, using different implementations for different platforms behind a platform-independent interface.
UI backend: The UI backend is used for drawing basic widgets like combo boxes and windows. This backend exposes a generic interface that is not platform specific. Underneath it uses operating system user interface methods.
JavaScript engine: The JavaScript engine is used to parse and execute JavaScript code.
Data storage: The data storage is a persistence layer. The browser may need to save all sorts of data locally, such as cookies. Browsers also support storage mechanisms such as localStorage, IndexedDB, WebSQL and FileSystem.
Note:
During the rendering process the graphical computing layers can use general purpose CPU or the graphical processor GPU as well.
When using GPU for graphical rendering computations the graphical software layers split the task into multiple pieces, so it can take advantage of GPU massive parallelism for float point calculations required for the rendering process.
Useful Links:
1. https://github.com/alex/what-happens-when
2. https://codeburst.io/how-browsers-work-6350a4234634
<script>tags (that are not marked asynchronous) is that they may change the DOM and thus what is going to be rendered. IE6 would often start drawing early, hence those "jumps" in the page of modern websites. Note that the entire DOM is read from the page you are accessing. Tommy says "DOM construction", it's already fully constructed by the time you hit any scripts. What he meant is more "DOM execution/interpretation". Also, it is a good idea to have CSS files before scripts otherwise the width/height will be wrong. – Kendo